Présentation
- Certaines règles spécifiques doivent être suivies lors de la création des objets de la base de données. Pour améliorer les performances d'une base de données, une clé primaire, des index clusterisés et non clusterisés et des contraintes doivent être affectés à une table. Bien que nous suivions toutes ces règles, des lignes en double peuvent toujours apparaître dans un tableau.
- Il est toujours recommandé d'utiliser les clés de la base de données. L'utilisation des clés de base de données réduira les risques d'obtenir des enregistrements en double dans une table. Mais si des enregistrements en double sont déjà présents dans une table, il existe des moyens spécifiques qui sont utilisés pour supprimer ces enregistrements en double.
Méthodes pour supprimer les lignes en double
- Utilisation de DELETE JOIN déclaration pour supprimer les lignes en double
L'instruction DELETE JOIN est fournie dans MySQL et permet de supprimer les lignes en double d'une table.
Considérez une base de données avec le nom "studentdb". Nous allons y créer une table student.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
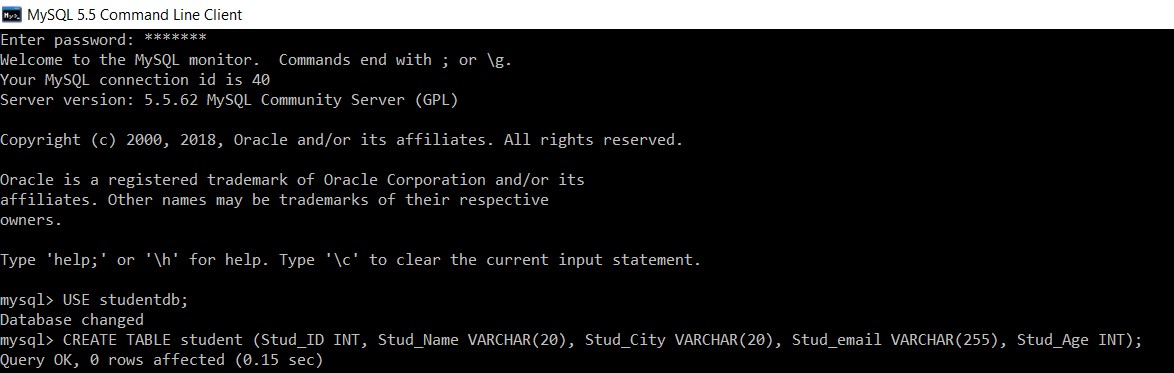
Nous avons créé avec succès une table 'student' dans la base de données 'studentdb'.
Maintenant, nous allons écrire les requêtes suivantes pour insérer des données dans la table des étudiants.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
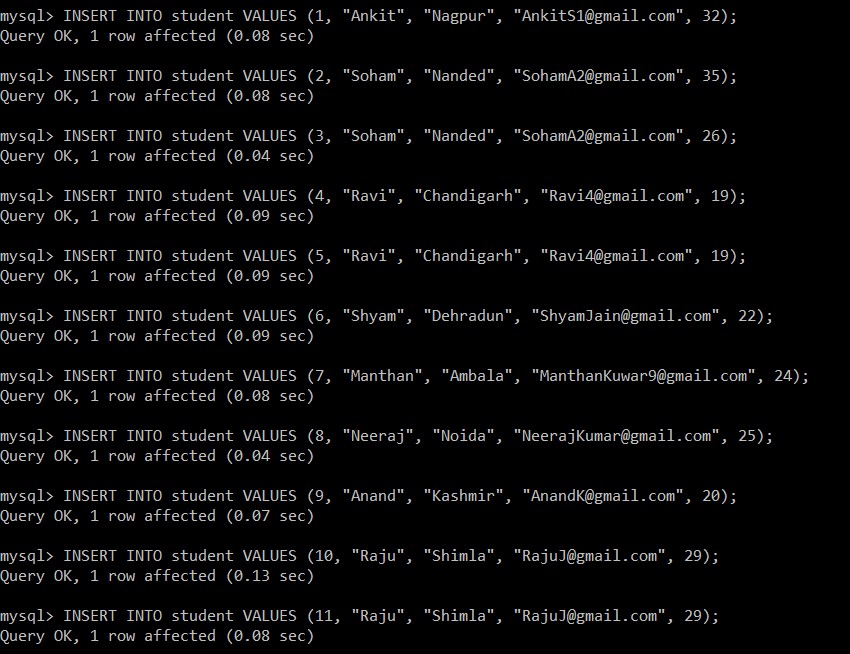
Maintenant, nous allons récupérer tous les enregistrements de la table des étudiants. Nous considérerons ce tableau et cette base de données pour tous les exemples suivants.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
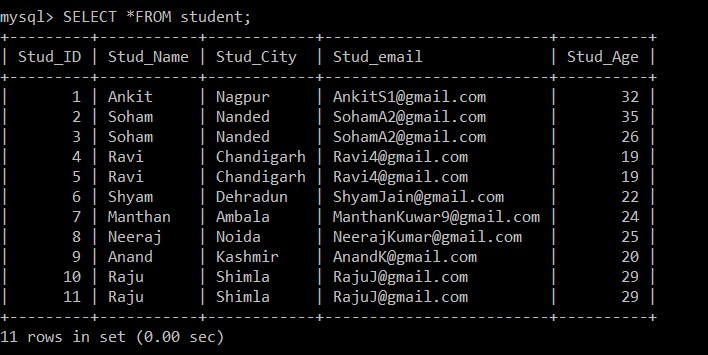
Exemple 1 :
Écrivez une requête pour supprimer les lignes en double de la table des étudiants à l'aide de DELETE JOIN déclaration.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Nous avons utilisé la requête DELETE avec INNER JOIN. Pour implémenter INNER JOIN sur une seule table, nous avons créé deux instances s1 et s2. Ensuite, à l'aide de la clause WHERE, nous avons vérifié deux conditions pour trouver les lignes en double dans la table des étudiants. Si l'identifiant de messagerie dans deux enregistrements différents est le même et que l'identifiant de l'étudiant est différent, il sera traité comme un enregistrement en double conformément à la condition de la clause WHERE.
Sortie :
Query OK, 3 rows affected (0.20 sec)Les résultats de la requête ci-dessus montrent qu'il existe trois enregistrements en double dans la table des étudiants.

Nous utiliserons la requête SELECT pour trouver les enregistrements en double qui ont été supprimés.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
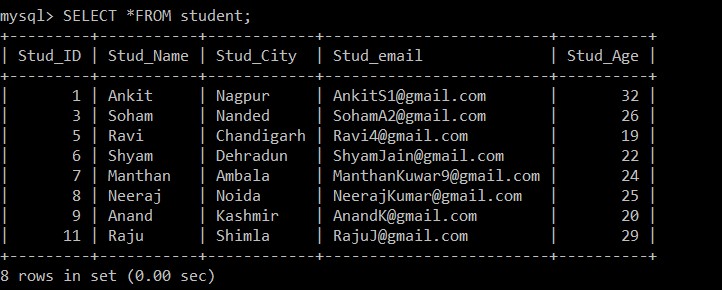
Désormais, seuls 8 enregistrements sont présents dans la table des étudiants car les trois enregistrements en double sont supprimés de la table actuellement sélectionnée. Selon la condition suivante :
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Si les identifiants de messagerie de deux enregistrements sont identiques, puisque le signe inférieur à est utilisé entre l'identifiant de l'étudiant, seul l'enregistrement avec les identifiants d'employé les plus grands sera conservé et l'autre enregistrement en double sera supprimé entre les deux enregistrements.
Exemple 2 :
Écrivez une requête pour supprimer les lignes en double de la table des étudiants à l'aide de l'instruction delete join tout en conservant l'enregistrement en double avec un identifiant d'employé inférieur et en supprimant l'autre.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Nous avons utilisé la requête DELETE avec INNER JOIN. Pour implémenter INNER JOIN sur une seule table, nous avons créé deux instances s1 et s2. Ensuite, à l'aide de la clause WHERE, nous avons vérifié deux conditions pour trouver les lignes en double dans la table des étudiants. Si l'identifiant de messagerie présent dans deux enregistrements différents est le même et que l'identifiant de l'étudiant est différent, il sera traité comme un enregistrement en double conformément à la condition de la clause WHERE.
Sortie :
Query OK, 3 rows affected (0.09 sec)Les résultats de la requête ci-dessus montrent qu'il existe trois enregistrements en double dans la table des étudiants.

Nous utiliserons la requête SELECT pour trouver les enregistrements en double qui ont été supprimés.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
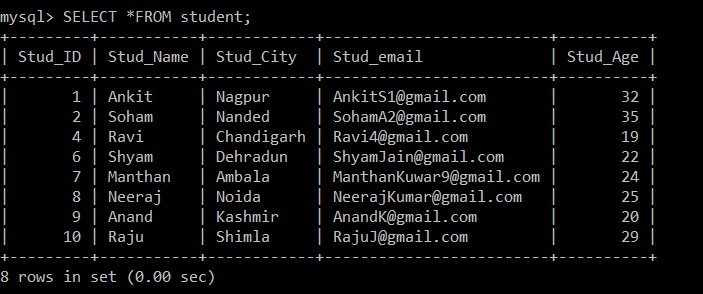
Désormais, seuls 8 enregistrements sont présents dans la table des étudiants car les trois enregistrements en double sont supprimés de la table actuellement sélectionnée. Selon la condition suivante :
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Si les identifiants de messagerie de deux enregistrements sont identiques puisque le signe supérieur à est utilisé entre l'identifiant de l'étudiant, seul l'enregistrement avec l'identifiant d'employé le plus petit sera conservé et l'autre enregistrement en double sera supprimé parmi les deux enregistrements.
- Utilisation d'un tableau intermédiaire pour supprimer les lignes en double
Les étapes suivantes doivent être suivies lors de la suppression des lignes en double à l'aide d'une table intermédiaire.
- Une nouvelle table doit être créée, qui sera la même que la table réelle.
- Ajouter des lignes distinctes du tableau réel au tableau nouvellement créé.
- Supprimer la table réelle et renommer la nouvelle table avec le même nom qu'une table réelle.
Exemple :
Écrivez une requête pour supprimer les enregistrements en double de la table des étudiants en utilisant une table intermédiaire.
Étape 1 :
Dans un premier temps, nous allons créer une table intermédiaire qui sera la même que la table des employés.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Ici, 'employee' est la table d'origine et 'temp_student' est la table intermédiaire.
Étape 2 :
Maintenant, nous allons récupérer uniquement les enregistrements uniques de la table des étudiants et insérer tous les enregistrements récupérés dans la table temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Ici, avant d'insérer les enregistrements distincts de la table des étudiants dans temp_student, tous les enregistrements en double sont filtrés par Stud_email. Ensuite, seuls les enregistrements avec un identifiant de messagerie unique ont été insérés dans temp_student.
Étape 3 :
Ensuite, nous supprimerons la table des étudiants et renommerons la table temp_student en table des étudiants.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
La table des étudiants est supprimée avec succès et temp_student est renommé en table des étudiants, qui ne contient que les enregistrements uniques.
Ensuite, nous devons vérifier que la table des étudiants ne contient désormais que les enregistrements uniques. Pour vérifier cela, nous avons utilisé la requête SELECT pour voir les données contenues dans la table des étudiants.
mysql> SELECT *FROM student;Sortie :
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
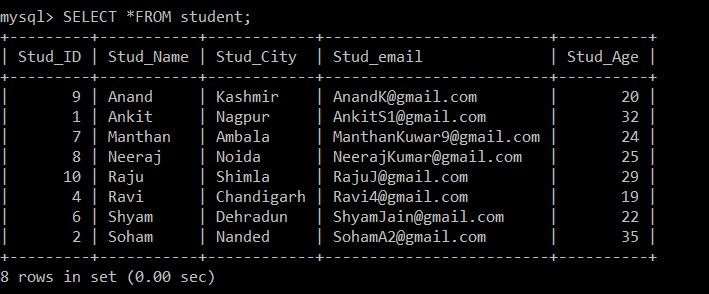
Désormais, seuls 8 enregistrements sont présents dans la table des étudiants car les trois enregistrements en double sont supprimés de la table actuellement sélectionnée. À l'étape 2, lors de la récupération des enregistrements distincts de la table d'origine et de leur insertion dans une table intermédiaire, une clause GROUP BY a été utilisée sur Stud_email, de sorte que tous les enregistrements ont été insérés en fonction des identifiants de messagerie des étudiants. Ici, seul l'enregistrement avec un identifiant d'employé inférieur est conservé parmi les enregistrements en double par défaut, et l'autre est supprimé.