SQL Server a introduit les objets OLTP en mémoire dans SQL Server 2014. Il y avait de nombreuses limitations dans la version initiale; certains ont été traités dans SQL Server 2016, et il est prévu que d'autres seront traités dans la prochaine version à mesure que la fonctionnalité continue d'évoluer. Jusqu'à présent, l'adoption de l'OLTP en mémoire ne semble pas très répandue, mais à mesure que la fonctionnalité mûrit, je m'attends à ce que davantage de clients commencent à poser des questions sur la mise en œuvre. Comme pour tout changement majeur de schéma ou de code, je recommande des tests approfondis pour déterminer si l'OLTP en mémoire fournira les avantages attendus. Dans cet esprit, j'étais intéressé de voir comment les performances changeaient pour des instructions INSERT, UPDATE et DELETE très simples avec OLTP en mémoire. J'espérais que si je pouvais démontrer que le verrouillage ou le verrouillage était un problème avec les tables sur disque, les tables en mémoire fourniraient une solution, car elles sont sans verrouillage ni verrouillage.
J'ai développé le test suivant cas :
- Une table sur disque avec des procédures stockées traditionnelles pour DML.
- Une table en mémoire avec des procédures stockées traditionnelles pour DML.
- Une table en mémoire avec des procédures nativement compilées pour DML.
J'étais intéressé par la comparaison des performances des procédures stockées traditionnelles et des procédures compilées en mode natif, car une restriction d'une procédure compilée en mode natif est que toutes les tables référencées doivent être en mémoire. Alors que les modifications solitaires à une seule ligne peuvent être courantes dans certains systèmes, je vois souvent des modifications se produire dans une procédure stockée plus grande avec plusieurs instructions (SELECT et DML) accédant à une ou plusieurs tables. La documentation OLTP en mémoire recommande fortement d'utiliser des procédures compilées en mode natif pour tirer le meilleur parti en termes de performances. Je voulais comprendre à quel point cela améliorait les performances.
La configuration
J'ai créé une base de données avec un groupe de fichiers à mémoire optimisée, puis créé trois tables différentes dans la base de données (une sur disque, deux en mémoire) :
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
Le DDL était presque le même pour tous les objets, en tenant compte du disque par rapport à la mémoire, le cas échéant. DiskTable DDL contre DDL en mémoire :
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
J'ai également créé neuf procédures stockées - une pour chaque combinaison table/modification.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Mise à jour
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Chaque procédure stockée acceptait une entrée entière à boucler pour ce nombre de modifications. Les procédures stockées suivaient le même format, les variations n'étaient que la table accédée et si l'objet était compilé nativement ou non. Le code complet pour créer la base de données et les objets peut être trouvé ici , avec des exemples d'instructions INSERT et UPDATE ci-dessous :
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Remarque :Les tables IDs_* ont été repeuplées après chaque ensemble d'insertions terminées et étaient spécifiques aux trois scénarios différents.
Méthodologie de test
Les tests ont été effectués à l'aide de scripts .cmd qui utilisaient sqlcmd pour appeler un script exécutant la procédure stockée, par exemple :
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"quitter
J'ai utilisé cette approche pour créer une ou plusieurs connexions à la base de données qui s'exécuteraient simultanément. En plus de comprendre les modifications de base des performances, je souhaitais également examiner l'effet de différentes charges de travail. Ces scripts ont été lancés à partir d'une machine distincte pour éliminer la surcharge liée à l'instanciation des connexions. Chaque procédure stockée a été exécutée 1000 fois par une connexion, et j'ai testé 1 connexion, 10 connexions et 100 connexions (respectivement 1000, 10000 et 100000 modifications). J'ai capturé des mesures de performances à l'aide de Query Store, ainsi que des statistiques d'attente. Avec Query Store, je pouvais capturer la durée moyenne et le processeur pour chaque procédure stockée. Les données des statistiques d'attente ont été capturées pour chaque connexion à l'aide de dm_exec_session_wait_stats, puis agrégées pour l'ensemble du test.
J'ai exécuté chaque test quatre fois, puis j'ai calculé les moyennes globales des données utilisées dans cet article. Les scripts utilisés pour les tests de charge de travail peuvent être téléchargés à partir d'ici.
Résultats
Comme on pouvait s'y attendre, les performances avec les objets en mémoire étaient meilleures qu'avec les objets basés sur disque. Cependant, une table en mémoire avec une procédure stockée standard présentait parfois des performances comparables ou légèrement meilleures par rapport à une table sur disque avec une procédure stockée standard. Souvenez-vous :j'étais intéressé à comprendre si j'avais vraiment besoin d'une procédure stockée compilée pour obtenir un avantage important avec une table en mémoire. Pour ce scénario, je l'ai fait. Dans tous les cas, la table en mémoire avec la procédure compilée nativement avait des performances nettement meilleures. Les deux graphiques ci-dessous affichent les mêmes données, mais avec des échelles différentes pour l'axe des x, afin de démontrer que les performances des procédures stockées régulières qui modifient les données se dégradent avec davantage de connexions simultanées.
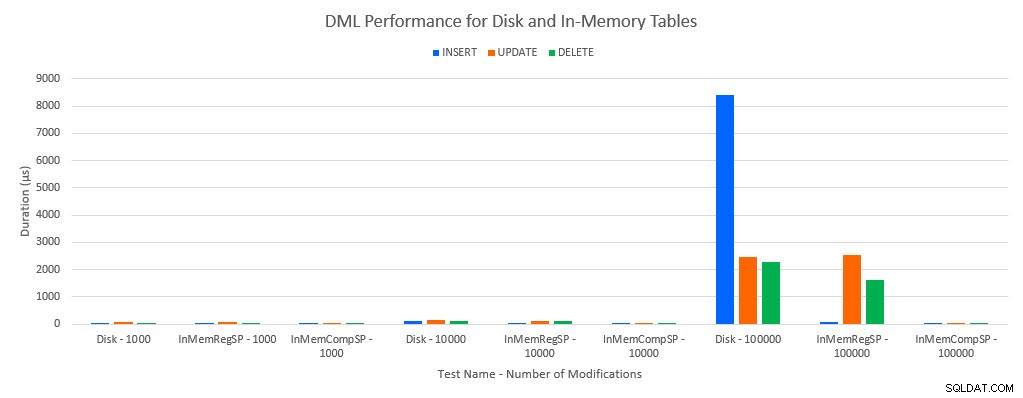
Performance DML par test et charge de travail
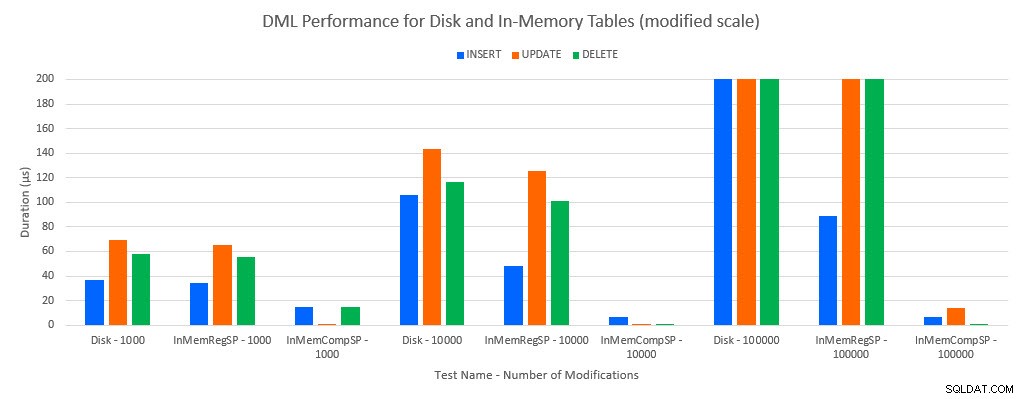
Performances DML par test et charge de travail [Échelle modifiée]
L'exception concerne les INSERT dans la table en mémoire avec la procédure stockée normale. Avec 100 connexions, la durée moyenne est supérieure à 8 ms pour une table sur disque, mais inférieure à 100 microsecondes pour la table In-Memory. La raison probable est l'absence de verrouillage et de verrouillage avec la table In-Memory, et cela est pris en charge avec les données de statistiques d'attente :
| Tester | INSÉRER | MISE À JOUR | SUPPRIMER |
|---|---|---|---|
| Table des disques – 1 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tableau des disques – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10 000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Tableau des disques – 100 000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
Statistiques d'attente par test
Les données des statistiques d'attente sont répertoriées ici en fonction du temps d'attente total des ressources (qui se traduit généralement également par le temps moyen le plus élevé des ressources, mais il y a eu des exceptions). Le type d'attente WRITELOG est le facteur limitant dans ce système la plupart du temps. Cependant, le PAGELATCH_EX attend 100 connexions simultanées exécutant des instructions INSERT suggère qu'avec une charge supplémentaire, le comportement de verrouillage et de verrouillage qui existe avec les tables sur disque pourrait être un facteur limitant. Dans les scénarios UPDATE et DELETE avec 10 et 100 connexions pour les tests de table sur disque, le temps d'attente moyen des ressources était le plus élevé pour les verrous (LCK_M_X).
Conclusion
L'OLTP en mémoire peut absolument fournir une amélioration des performances pour la bonne charge de travail. Cependant, les exemples testés ici sont extrêmement simples et ne doivent pas être considérés comme une seule raison de migrer vers une solution In-Memory. Il existe encore plusieurs limitations qui doivent être prises en compte et des tests approfondis doivent être effectués avant qu'une migration ne se produise (en particulier parce que la migration vers une table en mémoire est un processus hors ligne). Mais pour le bon scénario, cette nouvelle fonctionnalité peut améliorer les performances. Tant que vous comprenez que certaines limitations sous-jacentes existeront toujours, telles que la vitesse du journal des transactions pour les tables durables, bien que très probablement de manière réduite, que la table existe sur disque ou en mémoire.