Le Service Pack 2 pour SQL Server 2014 a été publié le mois dernier (lisez les notes de publication ici) et inclut une nouvelle instruction DBCC :DBCC CLONEDATABASE . J'étais assez excité de voir cette commande introduite, car elle fournit un moyen très facile façon de copier un schéma de base de données, y compris les statistiques , qui peut être utilisé pour tester les performances des requêtes sans nécessiter tout l'espace nécessaire pour les données dans la base de données. J'ai enfin pris le temps de tester DBCC CLONEDATABASE et comprendre les limites, et je dois dire que c'était plutôt amusant.
Les bases
J'ai commencé par créer un clone de la base de données AdventureWorks2014 et en exécutant une requête sur la base de données source, puis sur la base de données clone :
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Si je regarde la sortie I/O et TIME, je peux voir que la requête sur la base de données source a pris plus de temps et a généré beaucoup plus d'E/S, ce qui est attendu car la base de données clonée ne contient aucune donnée :
/* Base de données SOURCE */
Temps d'exécution de SQL Server :
Temps CPU =0 ms, temps écoulé =0 ms.
Temps d'analyse et de compilation de SQL Server :
Temps CPU =0 ms, temps écoulé =4 ms.
(121317 ligne(s) concernée(s))
Tableau 'SalesOrderHeader'. Nombre de balayages 0, lectures logiques 371567, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'SalesOrderDetail'. Nombre de balayages 5, lectures logiques 1361, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
(1 ligne(s) concernée(s))
Temps d'exécution de SQL Server :
Temps CPU =686 ms, temps écoulé =2 548 ms.
/* CLONE base de données */
Temps d'exécution de SQL Server :
Temps CPU =0 ms, temps écoulé =0 ms.
Temps d'analyse et de compilation de SQL Server :
Temps CPU =12 ms, temps écoulé =12 ms.
(0 ligne(s) concernée(s))
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'SalesOrderHeader'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'SalesOrderDetail'. Nombre de balayages 5, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
(1 ligne(s) concernée(s))
Temps d'exécution de SQL Server :
Temps CPU =0 ms, temps écoulé =83 ms.
Si je regarde les plans d'exécution, ils sont les mêmes pour les deux bases de données à l'exception des valeurs réelles (la quantité de données qui s'est réellement déplacée dans le plan) :
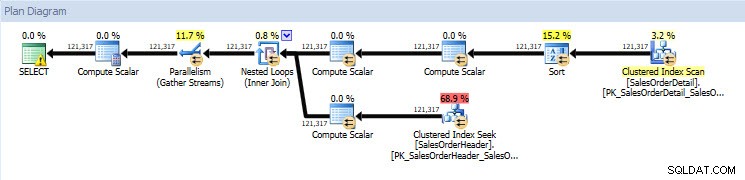 Plan de requête pour la base de données AdventureWorks2014
Plan de requête pour la base de données AdventureWorks2014
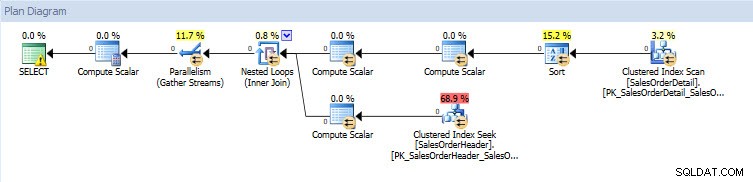 Plan de requête pour la base de données AdventureWorks2014_CLONE
Plan de requête pour la base de données AdventureWorks2014_CLONE
C'est là que la valeur de DBCC CLONEDATABASE est évident - je peux obtenir une copie vide d'une base de données à n'importe qui (support produit Microsoft, mon collègue DBA, etc.) et les faire recréer et enquêter sur un problème, et ils n'ont pas besoin potentiellement de centaines de Go d'espace disque pour faire ce. Le billet du mardi T-SQL de Melissa en juillet contient des informations détaillées sur ce qui se passe pendant le processus de clonage, je vous recommande donc de le lire pour plus d'informations.
C'est ça ?
Mais… puis-je faire plus avec DBCC CLONEDATABASE ? Je veux dire, c'est génial, mais je pense qu'il y a beaucoup d'autres choses que je peux faire avec une copie vide de la base de données. Si vous lisez la documentation de DBCC CLONEDATABASE , vous verrez cette ligne :
Ma première pensée a été :"optimiseur de requête – hmm ... puis-je l'utiliser comme option pour tester les mises à niveau ? ?"
Eh bien, la base de données clonée est en lecture seule, mais j'ai pensé essayer de changer certaines options de toute façon. Par exemple, si je pouvais changer le mode de compatibilité, ce serait vraiment cool, car je pourrais alors tester les changements CE dans SQL Server 2014 et SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
J'obtiens une erreur :
Msg 3906, niveau 16, état 1Échec de la mise à jour de la base de données "AdventureWorks2014_CLONE" car la base de données est en lecture seule.
Msg 5069, niveau 16, état 1
Échec de l'instruction ALTER DATABASE.
Hum. Puis-je changer le modèle de récupération ?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Je peux. Cela ne semble pas juste. Eh bien, c'est en lecture seule, puis-je changer cela ?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
OUI! Avant que vous ne soyez trop excité, permettez-moi de laisser cette note de la documentation ici :
Remarque La base de données nouvellement générée générée à partir de DBCC CLONEDATABASE n'est pas prise en charge pour être utilisée comme base de données de production et est principalement destinée à des fins de dépannage et de diagnostic. Nous vous recommandons de détacher la base de données clonée une fois la base de données créée.Je vais répéter cette ligne de la documentation, la mettre en gras et la mettre en rouge comme un signe amical mais extrêmement important rappel :
La nouvelle base de données générée à partir de DBCC CLONEDATABASE n'est pas prise en charge pour être utilisée comme base de données de production et est principalement destinée à des fins de dépannage et de diagnostic.Eh bien ça me va, je n'allais certainement pas l'utiliser pour la production, mais maintenant je peux l'utiliser pour les tests ! MAINTENANT, je peux changer le mode de compatibilité, et MAINTENANT je peux le sauvegarder et le restaurer sur une autre instance pour le tester !
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
C'EST GROS.
Dans mon dernier message, j'ai parlé de l'indicateur de trace 2389 et des tests avec le nouvel estimateur de cardinalité parce que, mes amis, vous avez besoin à tester avec le nouveau CE avant de procéder à la mise à niveau. Si vous ne testez pas et si vous changez le mode de compatibilité en 120 (SQL Server 2014) ou 130 (SQL Server 2016) dans le cadre de votre mise à niveau, vous courez le risque de travailler en mode anti-incendie si vous rencontrez régressions avec le nouveau CE. Maintenant, vous pourriez être très bien et les performances peuvent être encore meilleures après la mise à niveau. Mais… ne voudriez-vous pas en être certain ?
Très souvent, lorsque je mentionne les tests avant une mise à niveau, on me dit qu'il n'y a pas d'environnement dans lequel effectuer les tests. Je sais que certains d'entre vous ont un environnement de test. Certains d'entre vous ont Test, Dev, QA, UAT et qui sait quoi d'autre. Vous avez de la chance.
Pour ceux d'entre vous qui déclarent n'avoir aucun environnement de test dans lequel tester, je vous donne DBCC CLONEDATABASE . Avec cette commande, vous n'avez aucune excuse pour ne pas exécuter les requêtes les plus fréquemment exécutées et les poids lourds sur un clone de votre base de données. Même si vous n'avez pas d'environnement de test, vous avez votre propre machine. Sauvegardez la base de données de clone à partir de la production, supprimez le clone, restaurez la sauvegarde sur votre instance locale, puis testez. La base de données clonée occupe très peu d'espace sur le disque et vous n'aurez pas de conflit de mémoire ou d'E/S car il n'y a pas de données. Vous allez être en mesure de valider les plans de requête du clone par rapport à ceux de votre base de données de production. De plus, si vous restaurez sur SQL Server 2016, vous pouvez intégrer Query Store dans vos tests ! Activez le magasin de requêtes, effectuez vos tests dans le mode de compatibilité d'origine, puis mettez à niveau le mode de compatibilité et testez à nouveau. Vous pouvez utiliser Query Store pour comparer les requêtes côte à côte ! (Pouvez-vous dire que je danse sur ma chaise en ce moment ?)
Considérations
Encore une fois, cela ne devrait pas être quelque chose que vous utiliseriez en production, et je sais que vous ne le feriez pas, mais cela mérite d'être répété car dans son état actuel, DBCC CLONEDATABASE n'est pas entièrement complet . Ceci est noté dans l'article de la base de connaissances sous les objets pris en charge ; les objets tels que les tables à mémoire optimisée et les tables de fichiers ne sont pas copiés, le texte intégral n'est pas pris en charge, etc.
Maintenant, la base de données clone n'est pas sans inconvénients. Si vous exécutez par inadvertance une reconstruction d'index ou une mise à jour des statistiques dans cette base de données, vous venez d'effacer vos données de test. Vous perdrez les statistiques d'origine, ce que vous vouliez probablement vraiment en premier lieu. Par exemple, si je vérifie les statistiques de l'index clusterisé sur SalesOrderHeader en ce moment, j'obtiens ceci :
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistiques originales pour SalesOrderHeader
Statistiques originales pour SalesOrderHeader
Maintenant, si je mets à jour les statistiques par rapport à cette table, j'obtiens ceci :
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistiques mises à jour (vides) pour SalesOrderHeader
Statistiques mises à jour (vides) pour SalesOrderHeader
Par mesure de sécurité supplémentaire, il est probablement judicieux de désactiver les mises à jour automatiques des statistiques :
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Si vous mettez à jour les statistiques par inadvertance, exécutez DBCC CLONEDATABASE et passer par le processus de sauvegarde et de restauration n'est pas si difficile, et vous l'aurez automatisé en un rien de temps.
Vous pouvez ajouter des données à la base de données. Cela peut être utile si vous souhaitez expérimenter des statistiques (par exemple, différents taux d'échantillonnage, statistiques filtrées) et que vous disposez de suffisamment d'espace de stockage pour conserver une copie des données de la table.
En l'absence de données dans la base de données, vous n'obtiendrez évidemment pas de données de durée et d'E/S représentatives de manière fiable. C'est bon. Si vous avez besoin de données sur l'utilisation réelle des ressources, vous avez besoin d'une copie de votre base de données avec toutes les données qu'elle contient. DBCC CLONEDATABASE consiste vraiment à tester les performances des requêtes ; c'est ça. Il ne remplace en aucun cas les tests de mise à niveau traditionnels, mais il s'agit d'une nouvelle option permettant de valider la façon dont SQL Server optimise une requête avec différentes versions et modes de compatibilité. Bon test !



