La mise en compartiments des données de date et d'heure implique l'organisation des données en groupes représentant des intervalles de temps fixes à des fins d'analyse. Souvent, l'entrée est constituée de données de séries chronologiques stockées dans une table où les lignes représentent des mesures prises à des intervalles de temps réguliers. Par exemple, les mesures peuvent être des lectures de température et d'humidité prises toutes les 5 minutes, et vous souhaitez regrouper les données à l'aide de seaux horaires et calculer des agrégats comme la moyenne par heure. Même si les données de séries chronologiques sont une source courante pour l'analyse basée sur les compartiments, le concept est tout aussi pertinent pour toutes les données qui impliquent des attributs de date et d'heure et des mesures associées. Par exemple, vous souhaiterez peut-être organiser les données de ventes en tranches d'exercices fiscaux et calculer des agrégats comme la valeur totale des ventes par exercice fiscal. Dans cet article, j'aborde deux méthodes de compartimentage des données de date et d'heure. L'une utilise une fonction appelée DATE_BUCKET, qui au moment de la rédaction n'est disponible que dans Azure SQL Edge. Une autre consiste à utiliser un calcul personnalisé qui émule la fonction DATE_BUCKET, que vous pouvez utiliser dans n'importe quelle version, édition et saveur de SQL Server et Azure SQL Database.
Dans mes exemples, j'utiliserai l'exemple de base de données TSQLV5. Vous pouvez trouver le script qui crée et remplit TSQLV5 ici et son diagramme ER ici.
DATE_BUCKET
Comme mentionné, la fonction DATE_BUCKET est actuellement disponible uniquement dans Azure SQL Edge. SQL Server Management Studio prend déjà en charge IntelliSense, comme illustré à la figure 1 :
 Figure 1 :Prise en charge d'Intellisence pour DATE_BUCKET dans SSMS
Figure 1 :Prise en charge d'Intellisence pour DATE_BUCKET dans SSMS
La syntaxe de la fonction est la suivante :
DATE_BUCKET (L'origine d'entrée représente un point d'ancrage sur la flèche du temps. Il peut s'agir de n'importe lequel des types de données de date et d'heure pris en charge. Si non spécifié, la valeur par défaut est 1900, 1er janvier, minuit. Vous pouvez ensuite imaginer que la chronologie est divisée en intervalles discrets en commençant par le point d'origine, où la longueur de chaque intervalle est basée sur les entrées largeur du seau et partie date . Le premier est la quantité et le second est l'unité. Par exemple, pour organiser la chronologie en unités de 2 mois, vous devez spécifier 2 comme la largeur du godet entrée et mois comme partie date saisie.
L'horodatage d'entrée est un point arbitraire dans le temps qui doit être associé à son compartiment contenant. Son type de données doit correspondre au type de données de l'origine d'entrée . L'horodatage d'entrée est la valeur de date et d'heure associée aux mesures que vous capturez.
La sortie de la fonction est alors le point de départ du bucket contenant. Le type de données de la sortie est celui de l'entrée timestamp .
Si ce n'était pas déjà évident, vous utiliseriez généralement la fonction DATE_BUCKET comme élément d'ensemble de regroupement dans la clause GROUP BY de la requête et la renverriez naturellement également dans la liste SELECT, avec des mesures agrégées.
Encore un peu confus sur la fonction, ses entrées et sa sortie ? Peut-être qu'un exemple spécifique avec une représentation visuelle de la logique de la fonction serait utile. Je commencerai par un exemple qui utilise des variables d'entrée et plus loin dans l'article, je montrerai la manière la plus typique de l'utiliser dans le cadre d'une requête sur une table d'entrée.
Prenons l'exemple suivant :
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Vous pouvez trouver une représentation visuelle de la logique de la fonction dans la figure 2.
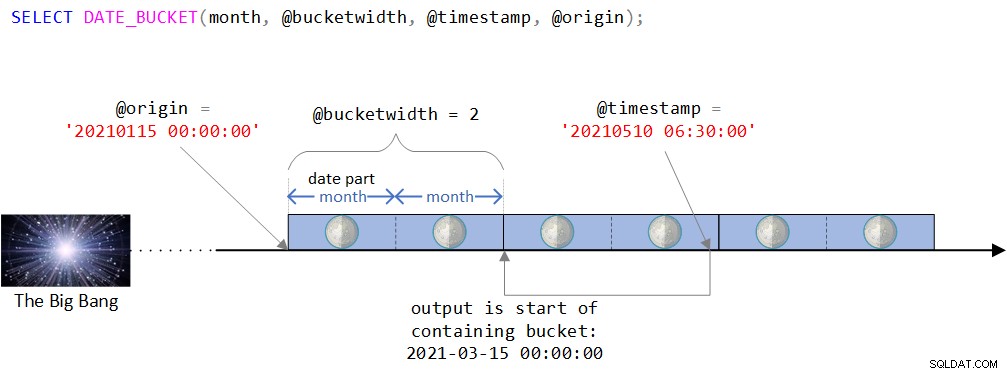 Figure 2 :Représentation visuelle de la logique de la fonction DATE_BUCKET
Figure 2 :Représentation visuelle de la logique de la fonction DATE_BUCKET
Comme vous pouvez le voir dans la figure 2, le point d'origine est la valeur DATETIME2 du 15 janvier 2021 à minuit. Si ce point d'origine semble un peu étrange, vous auriez raison de sentir intuitivement que normalement vous en utiliseriez un plus naturel comme le début d'une année ou le début d'un jour. En fait, vous seriez souvent satisfait de la valeur par défaut, qui, comme vous vous en souvenez, est le 1er janvier 1900 à minuit. J'ai intentionnellement voulu utiliser un point d'origine moins trivial pour pouvoir discuter de certaines complexités qui pourraient ne pas être pertinentes lors de l'utilisation d'un point d'origine plus naturel. Plus d'informations à ce sujet sous peu.
La chronologie est ensuite divisée en intervalles discrets de 2 mois en commençant par le point d'origine. L'horodatage d'entrée est la valeur DATETIME2 10 mai 2021, 6h30.
Notez que l'horodatage d'entrée fait partie du bucket qui commence le 15 mars 2021 à minuit. En effet, la fonction renvoie cette valeur sous la forme d'une valeur de type DATETIME2 :
--------------------------- 2021-03-15 00:00:00.0000000
Émulation DATE_BUCKET
À moins que vous n'utilisiez Azure SQL Edge, si vous souhaitez regrouper les données de date et d'heure, vous devez pour le moment créer votre propre solution personnalisée pour émuler ce que fait la fonction DATE_BUCKET. Faire cela n'est pas trop complexe, mais ce n'est pas trop simple non plus. Le traitement des données de date et d'heure implique souvent une logique délicate et des pièges auxquels vous devez faire attention.
Je vais construire le calcul par étapes et utiliser les mêmes entrées que celles que j'ai utilisées avec l'exemple DATE_BUCKET que j'ai montré plus tôt :
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Assurez-vous d'inclure cette partie avant chacun des exemples de code que je vais montrer si vous voulez réellement exécuter le code.
À l'étape 1, vous utilisez la fonction DATEDIFF pour calculer la différence dans la partie date unités entre origine et horodatage . J'appellerai cette différence diff1 . Cela se fait avec le code suivant :
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Avec nos exemples d'entrées, cette expression renvoie 4.
La partie délicate ici est que vous devez calculer combien d'unités entières de partie date exister entre origine et horodatage . Avec nos exemples d'entrées, il y a 3 mois entiers entre les deux et non 4. La raison pour laquelle la fonction DATEDIFF signale 4 est que, lorsqu'elle calcule la différence, elle ne regarde que la partie demandée des entrées et les parties supérieures mais pas les parties inférieures . Ainsi, lorsque vous demandez la différence en mois, la fonction ne se soucie que des parties année et mois des entrées et non des parties sous le mois (jour, heure, minute, seconde, etc.). En effet, il y a 4 mois entre janvier 2021 et mai 2021, mais seulement 3 mois entiers entre les saisies complètes.
Le but de l'étape 2 est alors de calculer combien d'unités entières de partie date exister entre origine et horodatage . J'appellerai cette différence diff2 . Pour ce faire, vous pouvez ajouter diff1 unités de partie de date à l'origine . Si le résultat est supérieur à timestamp , vous soustrayez 1 de diff1 pour calculer diff2 , sinon soustrayez 0 et utilisez donc diff1 comme diff2 . Cela peut être fait en utilisant une expression CASE, comme ceci :
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Cette expression renvoie 3, qui est le nombre de mois entiers entre les deux entrées.
Rappelez-vous que plus tôt j'ai mentionné que dans mon exemple j'ai intentionnellement utilisé un point d'origine qui n'est pas naturel comme un début rond d'une période afin que je puisse discuter de certaines complexités qui pourraient alors être pertinentes. Par exemple, si vous utilisez mois comme partie de date et le début exact d'un mois (1 d'un mois à minuit) comme origine, vous pouvez ignorer en toute sécurité l'étape 2 et utiliser diff1 comme diff2 . C'est parce que origine + diff1 ne peut jamais être> horodatage dans ce cas. Cependant, mon objectif est de fournir une alternative logiquement équivalente à la fonction DATE_BUCKET qui fonctionnerait correctement pour n'importe quel point d'origine, commun ou non. Donc, j'inclurai la logique de l'étape 2 dans mes exemples, mais n'oubliez pas que lorsque vous identifiez des cas où cette étape n'est pas pertinente, vous pouvez supprimer en toute sécurité la partie où vous soustrayez la sortie de l'expression CASE.
À l'étape 3, vous identifiez le nombre d'unités de partie de date il y a des buckets entiers qui existent entre origine et horodatage . Je désignerai cette valeur par diff3 . Cela peut être fait avec la formule suivante :
diff3 = diff2 / <bucket width> * <bucket width>
L'astuce ici est que lorsque vous utilisez l'opérateur de division / dans T-SQL avec des opérandes entiers, vous obtenez une division entière. Par exemple, 3/2 dans T-SQL est 1 et non 1,5. L'expression diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Cette expression renvoie 2, qui est le nombre de mois dans l'ensemble des tranches de 2 mois qui existent entre les deux entrées.
À l'étape 4, qui est la dernière étape, vous ajoutez diff3 unités de partie de date à l'origine pour calculer le début du compartiment conteneur. Voici le code pour y parvenir :
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ce code génère la sortie suivante :
--------------------------- 2021-03-15 00:00:00.0000000
Comme vous vous en souvenez, il s'agit de la même sortie produite par la fonction DATE_BUCKET pour les mêmes entrées.
Je vous suggère d'essayer cette expression avec différentes entrées et parties. Je vais montrer quelques exemples ici, mais n'hésitez pas à essayer les vôtres.
Voici un exemple où origine est juste légèrement en avance sur timestamp dans le mois :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ce code génère la sortie suivante :
--------------------------- 2021-03-10 06:30:01.0000000
Notez que le début du compartiment conteneur est en mars.
Voici un exemple où origine est au même point dans le mois que timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ce code génère la sortie suivante :
--------------------------- 2021-05-10 06:30:00.0000000
Notez que cette fois, le début du compartiment conteneur est en mai.
Voici un exemple avec des tranches de 4 semaines :
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Notez que le code utilise la semaine partie cette fois.
Ce code génère la sortie suivante :
--------------------------- 2021-02-12 00:00:00.0000000
Voici un exemple avec des périodes de 15 minutes :
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ce code génère la sortie suivante :
--------------------------- 2021-02-03 21:15:00.0000000
Notez que la partie est minute . Dans cet exemple, vous souhaitez utiliser des tranches de 15 minutes commençant au bas de l'heure, de sorte qu'un point d'origine situé au bas de n'importe quelle heure fonctionnerait. En fait, un point d'origine qui a une unité de minute de 00, 15, 30 ou 45 avec des zéros dans les parties inférieures, avec n'importe quelle date et heure fonctionnerait. Donc, la valeur par défaut que la fonction DATE_BUCKET utilise pour l'entrée origine travaillerait. Bien sûr, lorsque vous utilisez l'expression personnalisée, vous devez être explicite sur le point d'origine. Donc, pour sympathiser avec la fonction DATE_BUCKET, vous pouvez utiliser la date de base à minuit comme je le fais dans l'exemple ci-dessus.
Incidemment, pouvez-vous voir pourquoi ce serait un bon exemple où il est parfaitement sûr de sauter l'étape 2 de la solution ? Si vous avez effectivement choisi de sauter l'étape 2, vous obtenez le code suivant :
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); De toute évidence, le code devient beaucoup plus simple lorsque l'étape 2 n'est pas nécessaire.
Regroupement et agrégation de données par tranches de date et d'heure
Dans certains cas, vous devez regrouper des données de date et d'heure qui ne nécessitent pas de fonctions sophistiquées ou d'expressions peu maniables. Par exemple, supposons que vous souhaitiez interroger la vue Sales.OrderValues dans la base de données TSQLV5, regrouper les données annuellement et calculer le nombre total de commandes et les valeurs par an. Clairement, il suffit d'utiliser la fonction YEAR(orderdate) comme élément de groupement, comme ceci :
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Ce code génère la sortie suivante :
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Mais que se passe-t-il si vous souhaitez classer les données par exercice fiscal de votre organisation ? Certaines organisations utilisent une année fiscale à des fins de comptabilité, de budget et de reporting financier, non alignée sur l'année civile. Supposons, par exemple, que l'année fiscale de votre organisation fonctionne sur un calendrier fiscal d'octobre à septembre et qu'elle est indiquée par l'année civile au cours de laquelle l'année fiscale se termine. Ainsi, un événement qui a eu lieu le 3 octobre 2018 appartient à l'exercice qui a commencé le 1er octobre 2018, s'est terminé le 30 septembre 2019 et est désigné par l'année 2019.
C'est assez facile à réaliser avec la fonction DATE_BUCKET, comme ceci :
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Et voici le code utilisant l'équivalent logique personnalisé de la fonction DATE_BUCKET :
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Ce code génère la sortie suivante :
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
J'ai utilisé ici des variables pour la largeur du godet et le point d'origine afin de généraliser le code, mais vous pouvez les remplacer par des constantes si vous utilisez toujours les mêmes, puis simplifier le calcul selon les besoins.
Comme légère variation de ce qui précède, supposons que votre exercice fiscal s'étend du 15 juillet d'une année civile au 14 juillet de l'année civile suivante, et est désigné par l'année civile à laquelle appartient le début de l'exercice fiscal. Ainsi, un événement qui a eu lieu le 18 juillet 2018 appartient à l'exercice 2018. Un événement qui a eu lieu le 14 juillet 2018 appartient à l'exercice 2017. En utilisant la fonction DATE_BUCKET, vous obtiendrez ceci comme suit :
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Vous pouvez voir les changements par rapport à l'exemple précédent dans les commentaires.
Et voici le code utilisant l'équivalent logique personnalisé de la fonction DATE_BUCKET :
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Ce code génère la sortie suivante :
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Évidemment, il existe des méthodes alternatives que vous pouvez utiliser dans des cas spécifiques. Prenons l'exemple de l'avant-dernier, où l'année fiscale s'étend d'octobre à septembre et désignée par l'année civile au cours de laquelle l'année fiscale se termine. Dans ce cas, vous pouvez utiliser l'expression suivante, beaucoup plus simple :
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Et votre requête ressemblerait alors à ceci :
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Cependant, si vous voulez une solution généralisée qui fonctionnerait dans beaucoup plus de cas et que vous pourriez paramétrer, vous voudriez naturellement utiliser la forme la plus générale. Si vous avez accès à la fonction DATE_BUCKET, c'est parfait. Si vous ne le faites pas, vous pouvez utiliser l'équivalent logique personnalisé.
Conclusion
La fonction DATE_BUCKET est une fonction assez pratique qui vous permet de compartimenter les données de date et d'heure. Il est utile pour gérer les données de séries chronologiques, mais également pour compartimenter toutes les données qui impliquent des attributs de date et d'heure. Dans cet article, j'ai expliqué le fonctionnement de la fonction DATE_BUCKET et fourni un équivalent logique personnalisé au cas où la plate-forme que vous utilisez ne la prend pas en charge.