[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]
Dans la partie 3 de cette série, j'ai montré deux solutions de contournement pour éviter d'élargir une IDENTITY colonne - une qui vous fait simplement gagner du temps et une autre qui abandonne IDENTITY tout à fait. Le premier vous évite d'avoir à gérer des dépendances externes telles que les clés étrangères, mais le second ne résout toujours pas ce problème. Dans cet article, je voulais détailler l'approche que j'adopterais si j'avais absolument besoin de passer à bigint , avait besoin de minimiser les temps d'arrêt et disposait de suffisamment de temps pour la planification.
En raison de tous les bloqueurs potentiels et de la nécessité d'une perturbation minimale, l'approche peut être considérée comme un peu complexe, et elle ne le devient que si des fonctionnalités exotiques supplémentaires sont utilisées (par exemple, partitionnement, OLTP en mémoire ou réplication) .
À un niveau très élevé, l'approche consiste à créer un ensemble de tables fantômes, où toutes les insertions sont dirigées vers une nouvelle copie de la table (avec le plus grand type de données), et l'existence des deux ensembles de tables est aussi transparente que possible à l'application et à ses utilisateurs.
À un niveau plus précis, l'ensemble des étapes serait le suivant :
- Créer des clichés instantanés des tables, avec les bons types de données.
- Modifiez les procédures stockées (ou le code ad hoc) pour utiliser bigint pour les paramètres. (Cela peut nécessiter des modifications au-delà de la liste des paramètres, telles que des variables locales, des tables temporaires, etc., mais ce n'est pas le cas ici.)
- Renommer les anciennes tables et créer des vues avec ces noms qui unissent les anciennes et les nouvelles tables.
- Ces vues auront à la place des déclencheurs pour diriger correctement les opérations DML vers la ou les tables appropriées, afin que les données puissent toujours être modifiées pendant la migration.
- Cela nécessite également que SCHEMABINDING soit supprimé de toutes les vues indexées, que les vues existantes aient des unions entre les nouvelles et les anciennes tables, et que les procédures reposant sur SCOPE_IDENTITY() soient modifiées.
- Migrez les anciennes données vers les nouvelles tables par blocs.
- Nettoyage, composé de :
- Suppression des vues temporaires (ce qui supprimera les déclencheurs INSTEAD OF).
- Renommer les nouvelles tables avec les noms d'origine.
- Correction des procédures stockées pour revenir à SCOPE_IDENTITY().
- Suppression des anciennes tables désormais vides
- Remettre SCHEMABINDING sur les vues indexées et recréer les index clusterisés.
Vous pouvez probablement éviter une grande partie des vues et des déclencheurs si vous pouvez contrôler tous les accès aux données via des procédures stockées, mais comme ce scénario est rare (et impossible à faire confiance à 100 %), je vais vous montrer la voie la plus difficile.
Schéma initial
Dans un effort pour garder cette approche aussi simple que possible, tout en traitant de nombreux bloqueurs que j'ai mentionnés plus tôt dans la série, supposons que nous ayons ce schéma :
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Ainsi, une simple table personnel, avec une colonne IDENTITY clusterisée, un index non clusterisé, une colonne calculée basée sur la colonne IDENTITY, une vue indexée et une table HR/dirt séparée qui a une clé étrangère vers la table personnel (I n'encourage pas nécessairement cette conception, je l'utilise simplement pour cet exemple). Ce sont toutes des choses qui rendent ce problème plus compliqué qu'il ne le serait si nous avions une table autonome et indépendante.
Avec ce schéma en place, nous avons probablement des procédures stockées qui font des choses comme CRUD. Ce sont plus pour la documentation qu'autre chose; Je vais apporter des modifications au schéma sous-jacent de sorte que la modification de ces procédures devrait être minime. Il s'agit de simuler le fait que la modification de SQL ad hoc à partir de vos applications peut ne pas être possible et peut ne pas être nécessaire (enfin, tant que vous n'utilisez pas un ORM capable de détecter une table par rapport à une vue).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Ajoutons maintenant 5 lignes de données aux tables d'origine :
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Étape 1 :nouveaux tableaux
Ici, nous allons créer une nouvelle paire de tables, reflétant les originaux à l'exception du type de données des colonnes EmployeeID, de la graine initiale de la colonne IDENTITY et d'un suffixe temporaire sur les noms :
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Étape 2 – Fixer les paramètres de la procédure
Les procédures ici (et potentiellement votre code ad hoc, à moins qu'il n'utilise déjà le type entier plus grand) nécessiteront une modification très mineure afin qu'à l'avenir, elles puissent accepter les valeurs EmployeeID au-delà des limites supérieures d'un entier. Bien que vous puissiez dire que si vous modifiez ces procédures, vous pouvez simplement les pointer vers les nouvelles tables, j'essaie de faire valoir que vous pouvez atteindre l'objectif ultime avec une intrusion * minimale * dans l'existant, permanent code.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Étape 3 :vues et déclencheurs
Malheureusement, cela ne peut pas *tout* se faire en silence. Nous pouvons effectuer la plupart des opérations en parallèle et sans affecter l'utilisation simultanée, mais à cause du SCHEMABINDING, la vue indexée doit être modifiée et l'index recréé ultérieurement.
Cela est vrai pour tous les autres objets qui utilisent SCHEMABINDING et font référence à l'une de nos tables. Je recommande de le changer pour qu'il soit une vue non indexée au début de l'opération, et de reconstruire l'index une fois que toutes les données ont été migrées, plutôt que plusieurs fois dans le processus (puisque les tables seront renommées plusieurs fois). En fait, ce que je vais faire, c'est changer la vue pour unir les nouvelles et anciennes versions de la table Employés pendant la durée du processus.
Une autre chose que nous devons faire est de modifier temporairement la procédure stockée Employee_Add pour utiliser @@IDENTITY au lieu de SCOPE_IDENTITY(). En effet, le déclencheur INSTEAD OF qui gérera les nouvelles mises à jour des "Employés" n'aura pas la visibilité de la valeur SCOPE_IDENTITY(). Ceci, bien sûr, suppose que les tables n'ont pas de déclencheurs après qui affecteront @@IDENTITY. J'espère que vous pouvez soit modifier ces requêtes dans une procédure stockée (où vous pouvez simplement pointer l'INSERT vers la nouvelle table), soit votre code d'application n'a pas besoin de s'appuyer sur SCOPE_IDENTITY() en premier lieu.
Nous allons le faire sous SERIALIZABLE afin qu'aucune transaction n'essaie de se faufiler pendant que les objets sont en flux. Il s'agit d'un ensemble d'opérations en grande partie uniquement sur les métadonnées, donc cela devrait être rapide.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Étape 4 :Migrer les anciennes données vers une nouvelle table
Nous allons migrer les données en morceaux pour minimiser l'impact à la fois sur la concurrence et sur le journal des transactions, en empruntant la technique de base d'un de mes anciens articles, "Décomposer les opérations de suppression volumineuses en morceaux". Nous allons également exécuter ces lots en SERIALIZABLE, ce qui signifie que vous devrez faire attention à la taille des lots, et j'ai omis la gestion des erreurs par souci de concision.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Résultats :
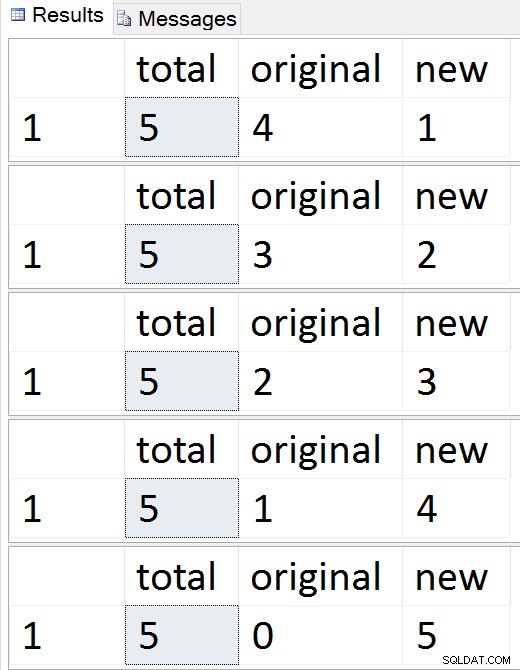 Voir les lignes migrer une par une
Voir les lignes migrer une par une
À tout moment au cours de cette séquence, vous pouvez tester les insertions, les mises à jour et les suppressions, et elles doivent être gérées de manière appropriée. Une fois la migration terminée, vous pouvez passer au reste du processus.
Étape 5 - Nettoyer
Une série d'étapes est nécessaire pour nettoyer les objets qui ont été créés temporairement et pour restaurer Employees / EmployeeFile en tant que citoyens de première classe. La plupart de ces commandes sont simplement des opérations de métadonnées - à l'exception de la création de l'index clusterisé sur la vue indexée, elles devraient toutes être instantanées.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO À ce stade, tout devrait revenir à un fonctionnement normal, bien que vous souhaitiez peut-être envisager des activités de maintenance typiques après des modifications majeures du schéma, telles que la mise à jour des statistiques, la reconstruction des index ou la suppression de plans du cache.
Conclusion
C'est une solution assez complexe à ce qui devrait être un problème simple. J'espère qu'à un moment donné, SQL Server permettra de faire des choses comme ajouter/supprimer la propriété IDENTITY, reconstruire les index avec de nouveaux types de données cibles et modifier les colonnes des deux côtés d'une relation sans sacrifier la relation. En attendant, j'aimerais savoir si cette solution vous aide ou si vous avez une approche différente.
Un grand bravo à James Lupolt (@jlupoltsql) pour avoir aidé la santé mentale à vérifier mon approche et à la mettre à l'épreuve ultime sur l'une de ses propres tables réelles. (Ça s'est bien passé. Merci James !)
—
[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]