Cet article fait partie d'une série sur les objectifs de ligne. Vous pouvez trouver les autres parties ici :
- Partie 1 :Définir et identifier des objectifs de ligne
- Partie 2 :Semi-jointures
- Partie 3 :Anti-jointures
Appliquer l'anti-jointure avec un opérateur supérieur
Vous verrez souvent un opérateur Top (1) interne dans appliquer l'anti-jointure plans d'exécution. Par exemple, en utilisant la base de données AdventureWorks :
SELECT P.ProductID FROM Production.Product AS PWHERE NOT EXISTS ( SELECT 1 FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Le plan montre un opérateur supérieur (1) à l'intérieur de l'anti-jointure d'application (références externes) :
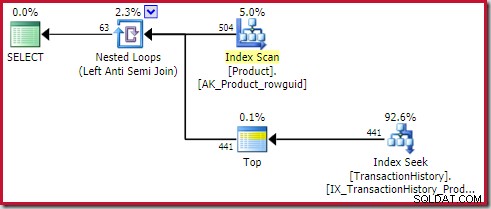
Cet opérateur Top est complètement redondant . Il n'est pas nécessaire pour l'exactitude, l'efficacité ou pour s'assurer qu'un objectif de ligne est défini.
L'opérateur d'application anti-jointure arrête de vérifier les lignes du côté intérieur (pour l'itération en cours) dès qu'une ligne est vue à la jointure. Il est parfaitement possible de générer un plan d'application anti jointure sans le Top. Alors pourquoi y a-t-il un opérateur Top dans ce plan ?
Source du meilleur opérateur
Pour comprendre d'où vient cet opérateur Top inutile, nous devons suivre les principales étapes suivies lors de la compilation et de l'optimisation de notre exemple de requête.
Comme d'habitude, la requête est d'abord analysée dans un arbre. Cela comporte un opérateur logique "n'existe pas" avec une sous-requête, qui correspond étroitement à la forme écrite de la requête dans ce cas :

La sous-requête inexistante est déroulée dans une application anti-jointure :

Ceci est ensuite transformé en une jointure anti-semi gauche logique. L'arborescence résultante transmise à l'optimisation basée sur les coûts ressemble à ceci :

La première exploration effectuée par l'optimiseur basé sur les coûts consiste à introduire une distinction logique opération sur l'entrée anti-jointure inférieure, pour produire des valeurs uniques pour la clé anti-jointure. L'idée générale est qu'au lieu de tester les valeurs dupliquées à la jointure, le plan pourrait bénéficier du regroupement de ces valeurs à l'avance.
La règle d'exploration responsable s'appelle LASJNtoLASJNonDist (anti-semi-jointure gauche à anti-semi-jointure gauche sur distinct). Aucune implémentation physique ou évaluation des coûts n'a encore été effectuée, il ne s'agit donc que de l'optimiseur explorant une équivalence logique, basée sur la présence d'un ProductID en double valeurs. La nouvelle arborescence avec l'opération de regroupement ajoutée est illustrée ci-dessous :

La prochaine transformation logique envisagée consiste à réécrire la jointure en tant que appliquer . Ceci est exploré à l'aide de la règle LASJNtoApply (gauche anti semi jointure à appliquer avec sélection relationnelle). Comme mentionné précédemment dans la série, la transformation précédente de l'application à la jointure visait à activer les transformations qui fonctionnent spécifiquement sur les jointures. Il est toujours possible de réécrire une jointure en tant qu'application, ce qui élargit la gamme d'optimisations disponibles.
Maintenant, l'optimiseur ne fait pas toujours envisager une réécriture d'application dans le cadre d'une optimisation basée sur les coûts. Il doit y avoir quelque chose dans l'arbre logique pour qu'il soit intéressant de pousser le prédicat de jointure vers le bas. En règle générale, ce sera l'existence d'un indice d'appariement, mais il existe d'autres cibles prometteuses. Dans ce cas, il s'agit de la clé logique sur ProductID créé par l'opération d'agrégation.
Le résultat de cette règle est une anti-jointure corrélée avec sélection sur le côté interne :

Ensuite, l'optimiseur envisage de déplacer la sélection relationnelle (le prédicat de jointure corrélé) plus bas vers l'intérieur, au-delà du distinct (groupe par agrégat) introduit précédemment par l'optimiseur. Ceci est fait par la règle SelOnGbAgg , qui déplace autant d'une sélection (prédicat) au-delà d'un groupe approprié par agrégat que possible (une partie de la sélection peut être laissée de côté). Cette activité aide à pousser les sélections aussi près que possible des opérateurs d'accès aux données au niveau feuille, pour éliminer les lignes plus tôt et faciliter la correspondance d'index ultérieure.
Dans ce cas, le filtre est sur la même colonne que l'opération de regroupement, donc la transformation est valide. Il en résulte que toute la sélection est poussée sous l'agrégat :

L'opération finale d'intérêt est effectuée par la règle GbAggToConstScanOrTop . Cette transformation semble remplacer un groupe par agrégat avec un Constant Scan ou Top opération logique. Cette règle correspond à notre arbre car la colonne de regroupement est constante pour chaque ligne passant par la sélection poussée vers le bas. Toutes les lignes sont garanties d'avoir le même ProductID . Le regroupement sur cette valeur unique produira toujours une ligne. Par conséquent, il est valide de transformer l'agrégat en un Top (1). C'est donc de là que vient le sommet.
Mise en œuvre et établissement des coûts
L'optimiseur exécute maintenant une série de règles d'implémentation pour trouver des opérateurs physiques pour chacune des alternatives logiques prometteuses qu'il a envisagées jusqu'à présent (stockées efficacement dans une structure mémo). Les options physiques anti-jointure de hachage et de fusion proviennent de l'arborescence initiale avec l'agrégat introduit (avec l'aimable autorisation de la règle LASJNtoLASJNonDist rappelles toi). L'application a besoin d'un peu plus de travail pour créer un top physique et faire correspondre la sélection à une recherche d'index.
Le meilleur anti-jointure de hachage la solution trouvée est chiffrée à 0,362143 unités :
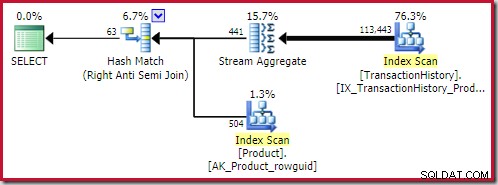
Le meilleur fusion anti-jointure la solution arrive à 0.353479 unités (un peu moins cher) :
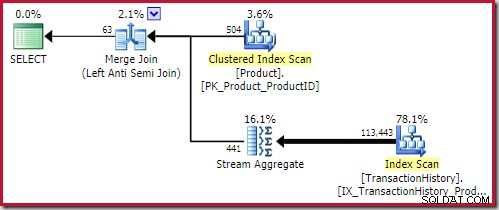
Le bouton appliquer l'anti-jointure coûte 0,091823 unités (moins cher par une large marge):
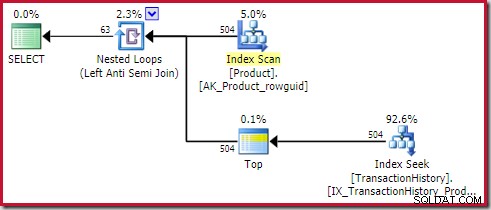
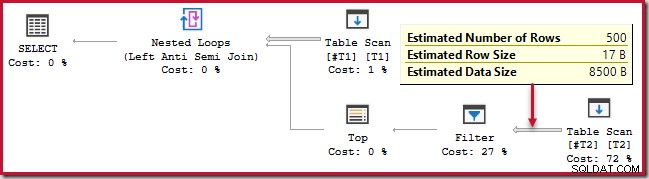
Le lecteur avisé peut remarquer que le nombre de lignes sur le côté intérieur de l'application anti-jointure (504) diffère de la capture d'écran précédente du même plan. En effet, il s'agit d'un plan estimé, alors que le plan précédent était post-exécution. Lorsque ce plan est exécuté, seules 441 lignes au total se trouvent du côté intérieur sur toutes les itérations. Cela met en évidence l'une des difficultés d'affichage lors de l'application de plans de semi/anti-jointure :l'estimation minimale de l'optimiseur est d'une ligne, mais une semi- ou anti-jointure localisera toujours une ligne ou aucune ligne à chaque itération. Les 504 lignes présentées ci-dessus représentent 1 ligne sur chacune des 504 itérations. Pour que les chiffres correspondent, l'estimation devrait être de 441/504 =0,875 lignes à chaque fois, ce qui confondrait probablement tout autant les gens.
Quoi qu'il en soit, le plan ci-dessus est assez "chanceux" pour se qualifier pour un objectif de ligne sur le côté intérieur de l'application anti-jointure pour deux raisons :
- L'anti-jointure est transformée d'une jointure en une application dans l'optimiseur basé sur les coûts. Cela définit un objectif de ligne (tel qu'établi dans la troisième partie).
- L'opérateur Top(1) définit également un objectif de ligne sur son sous-arbre.
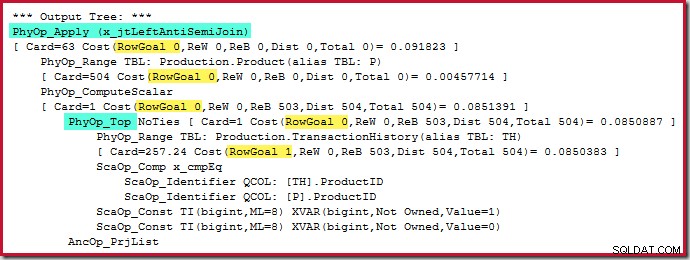
L'opérateur Top lui-même n'a pas d'objectif de ligne (à partir de l'application) puisque l'objectif de ligne de 1 ne serait pas inférieur que l'estimation régulière, qui est également de 1 ligne (Card=1 pour le PhyOp_Top ci-dessous) :
Le modèle anti-jointure
La forme de plan générale suivante est celle que je considère comme un anti-modèle :
Tous les plans d'exécution contenant une application anti-jointure avec un opérateur Top (1) sur son côté intérieur ne seront pas problématiques. Néanmoins, c'est un modèle à reconnaître et qui nécessite presque toujours une enquête plus approfondie.
Les quatre principaux éléments à surveiller sont :
- Une boucle imbriquée corrélée (appliquer ) anti-jointure
- Un haut (1) opérateur immédiatement sur le côté intérieur
- Un nombre important de lignes sur l'entrée externe (la partie interne sera donc exécutée plusieurs fois)
- Un potentiellement coûteux sous-arborescence sous le haut
Le sous-arbre "$$$" est celui qui est potentiellement coûteux à l'exécution . Cela peut être difficile à reconnaître. Si nous avons de la chance, il y aura quelque chose d'évident comme une table complète ou une analyse d'index. Dans les cas plus difficiles, le sous-arbre semblera parfaitement innocent à première vue, mais contiendra quelque chose de coûteux lorsqu'il sera examiné de plus près. Pour donner un exemple assez courant, vous pourriez voir un Index Seek qui est censé renvoyer un petit nombre de lignes, mais qui contient un prédicat résiduel coûteux qui teste un très grand nombre de lignes pour trouver les quelques-unes qui se qualifient.
L'exemple de code AdventureWorks précédent n'avait pas de sous-arborescence "potentiellement coûteuse". La recherche d'index (sans prédicat résiduel) serait une méthode d'accès optimale indépendamment des considérations d'objectif de ligne. C'est un point important :fournir à l'optimiseur une solution toujours efficace chemin d'accès aux données sur le côté interne d'une jointure corrélée est toujours une bonne idée. Cela est encore plus vrai lorsque l'application s'exécute en mode anti-jointure avec un opérateur Top (1) sur le côté intérieur.
Regardons maintenant un exemple qui a des performances d'exécution assez lamentables en raison de cet anti-modèle.
Exemple
Le script suivant crée deux tables temporaires de tas. Le premier comporte 500 lignes contenant les entiers de 1 à 500 inclus. La deuxième table contient 500 copies de chaque ligne de la première table, pour un total de 250 000 lignes. Les deux tables utilisent le sql_variant type de données.
SUPPRIMER TABLE SI EXISTE #T1, #T2 ; CREATE TABLE #T1 (c1 sql_variant NOT NULL);CREATE TABLE #T2 (c1 sql_variant NOT NULL); -- Nombres 1 à 500 inclus -- Stocké sous sql_variantINSERT #T1 (c1)SELECT CONVERT(sql_variant, SV.number)FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 ET numéro SV <=500 ; -- 500 copies de chaque ligne du tableau #T1INSERT #T2 (c1)SELECT T1.c1FROM #T1 AS T1CROSS JOIN #T1 AS T2 ; -- Assurez-vous d'avoir les meilleures informations statistiques possiblesPerformances
Nous exécutons maintenant une requête à la recherche de lignes dans la petite table qui ne sont pas présentes dans la grande table (bien sûr, il n'y en a pas) :
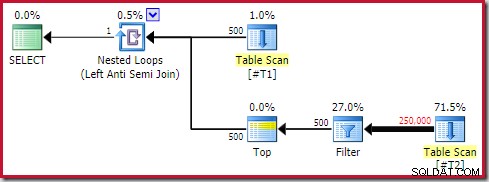
SELECT T1.c1 FROM #T1 AS T1WHERE NOT EXISTS ( SELECT 1 FROM #T2 AS T2 WHERE T2.c1 =T1.c1 );Cette requête s'exécute pendant environ 20 secondes , ce qui est terriblement long pour comparer 500 lignes à 250 000. Le plan estimé de SSMS rend difficile de comprendre pourquoi les performances pourraient être si médiocres :
L'observateur doit être conscient que les plans estimés SSMS affichent des estimations internes par itération de la jointure de boucle imbriquée. De manière confuse, les plans réels SSMS affichent le nombre de lignes sur toutes les itérations . Plan Explorer effectue automatiquement les calculs simples nécessaires aux plans estimés pour afficher également le nombre total de lignes attendues :
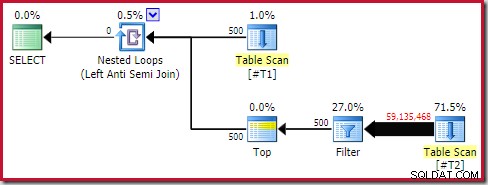
Même ainsi, les performances d'exécution sont bien pires que prévu. Le plan d'exécution post-exécution (réel) est :
Notez le filtre séparé, qui serait normalement enfoncé dans l'analyse en tant que prédicat résiduel. C'est la raison de l'utilisation du
sql_variantType de données; cela empêche de pousser le prédicat, ce qui rend le grand nombre de lignes de l'analyse plus facile à voir.Analyse
La raison de l'écart réside dans la façon dont l'optimiseur estime le nombre de lignes qu'il devra lire à partir de l'analyse de table pour atteindre l'objectif d'une ligne défini au niveau du filtre. L'hypothèse simple est que les valeurs sont uniformément réparties dans la table, donc pour rencontrer 1 des 500 valeurs uniques présentes, SQL Server devra lire 250 000/500 =500 lignes. Plus de 500 itérations, soit 250 000 lignes.
L'hypothèse d'uniformité de l'optimiseur est générale, mais elle ne fonctionne pas bien ici. Vous pouvez en savoir plus à ce sujet dans A Row Goal Request de Joe Obbish et voter pour sa suggestion sur le forum de commentaires sur le remplacement de Connect à Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop with TOP.
Mon point de vue sur cet aspect spécifique est que l'optimiseur devrait rapidement s'éloigner d'une simple hypothèse d'uniformité lorsque l'opérateur se trouve du côté intérieur d'une jointure de boucles imbriquées (c'est-à-dire que les rembobinages estimés plus les reliures sont supérieurs à un). C'est une chose de supposer que nous devons lire 500 lignes pour trouver une correspondance à la première itération de la boucle. Supposer cela à chaque itération semble terriblement improbable d'être exact; cela signifie que les 500 premières lignes rencontrées doivent contenir une de chaque valeur distincte. Il est très peu probable que ce soit le cas dans la pratique.
Une série d'événements malheureux
Indépendamment de la façon dont les opérateurs Top répétés sont facturés, il me semble que toute la situation devrait être évitée en premier lieu . Rappelez-vous comment le Top de ce plan a été créé :
- L'optimiseur a introduit un agrégat distinct du côté interne en tant qu'optimisation des performances .
- Cet agrégat fournit une clé sur la colonne de jointure par définition (il produit l'unicité).
- Cette clé construite fournit une cible pour la conversion d'une jointure en une application.
- Le prédicat (sélection) associé à l'application est poussé au-delà de l'agrégat.
- L'agrégat est désormais garanti de fonctionner sur une seule valeur distincte par itération (puisqu'il s'agit d'une valeur de corrélation).
- L'agrégat est remplacé par un Top (1).
Toutes ces transformations sont valables individuellement. Ils font partie des opérations normales de l'optimiseur car il recherche un plan d'exécution raisonnable. Malheureusement, le résultat ici est que l'agrégat spéculatif introduit par l'optimiseur finit par être transformé en un Top (1) avec un objectif de ligne associé . L'objectif de ligne conduit à un calcul des coûts inexact basé sur l'hypothèse d'uniformité, puis à la sélection d'un plan qui a très peu de chances de bien fonctionner.
Maintenant, on pourrait objecter que l'application anti-jointure aurait de toute façon un objectif de ligne - sans la séquence de transformation ci-dessus. Le contre-argument est que l'optimiseur ne tiendrait pas compte transformation d'anti-joindre à appliquer anti-joindre (définir l'objectif de ligne) sans l'agrégat introduit par l'optimiseur donnant le LASJNtoApply règle quelque chose à lier. De plus, nous avons vu (dans la troisième partie) que si l'anti-joindre avait saisi l'optimisation basée sur les coûts en tant qu'application (au lieu d'une jointure), il n'y aurait à nouveau pas d'objectif de ligne .
En bref, l'objectif de ligne dans le plan final est entièrement artificiel et n'a aucun fondement dans la spécification de requête d'origine. Le problème avec l'objectif Haut et ligne est un effet secondaire de cet aspect plus fondamental.
Solutions de contournement
Il existe de nombreuses solutions potentielles à ce problème. La suppression de l'une des étapes de la séquence d'optimisation ci-dessus garantira que l'optimiseur ne produit pas une implémentation d'application anti-jointure avec des coûts considérablement (et artificiellement) réduits. Espérons que ce problème sera résolu dans SQL Server le plus tôt possible.
En attendant, mon conseil est de faire attention au motif anti-jointure. Assurez-vous que le côté interne d'une application anti-jointure dispose toujours d'un chemin d'accès efficace pour toutes les conditions d'exécution. Si cela n'est pas possible, vous devrez peut-être utiliser des astuces, désactiver les objectifs de ligne, utiliser un guide de plan ou forcer un plan de magasin de requêtes pour obtenir des performances stables à partir des requêtes anti-jointure.
Résumé de la série
Nous avons couvert beaucoup de terrain au cours des quatre épisodes, voici donc un résumé de haut niveau :
- Partie 1 – Définir et identifier les objectifs de ligne
- La syntaxe de la requête ne détermine pas la présence ou l'absence d'un objectif de ligne.
- Un objectif de ligne n'est défini que lorsqu'il est inférieur à l'estimation normale.
- Les opérateurs Top physiques (y compris ceux introduits par l'optimiseur) ajoutent un objectif de ligne à leur sous-arborescence.
- Un
FASTouSET ROWCOUNTdéfinit un objectif de ligne à la racine du plan. - La semi-jointure et l'anti-jointure peuvent ajouter un objectif de ligne.
- SQL Server 2017 CU3 ajoute l'attribut showplan EstimateRowsWithoutRowGoal pour les opérateurs concernés par un objectif de ligne
- Les informations sur l'objectif de ligne peuvent être révélées par les indicateurs de trace non documentés 8607 et 8612.
- Partie 2 – Semi-jointures
- Il n'est pas possible d'exprimer une semi-jointure directement dans T-SQL, nous utilisons donc une syntaxe indirecte, par ex.
IN,EXISTS, ouINTERSECT. - Ces syntaxes sont analysées dans un arbre contenant une application (jointure corrélée).
- L'optimiseur tente de transformer l'application en une jointure normale (pas toujours possible).
- Le hachage, la fusion et la semi-jointure de boucles imbriquées régulières ne définissent pas d'objectif de ligne.
- Appliquer une semi-jointure définit toujours un objectif de ligne.
- Appliquer une semi-jointure peut être reconnu en ayant des références externes sur l'opérateur de jointure de boucles imbriquées.
- Appliquer une semi-jointure n'utilise pas d'opérateur Top (1) sur le côté intérieur.
- Partie 3 :Anti-jointures
- Également analysé dans une application, avec une tentative de réécriture en tant que jointure (pas toujours possible).
- Le hachage, la fusion et l'anti-jointure des boucles imbriquées régulières ne définissent pas d'objectif de ligne.
- Appliquer l'anti-jointure ne définit pas toujours un objectif de ligne.
- Seules les règles d'optimisation basée sur les coûts (CBO) qui transforment l'anti-jointure en application définissent un objectif de ligne.
- L'anti-jointure doit saisir CBO en tant que jointure (ne pas appliquer). Sinon, la jointure pour appliquer la transformation ne peut pas se produire.
- Pour saisir CBO en tant que jointure, la réécriture pré-CBO de l'application à la jointure doit avoir réussi.
- CBO n'explore la réécriture d'une anti-jointure à une application que dans les cas prometteurs.
- Les simplifications pré-CBO peuvent être visualisées avec l'indicateur de trace non documenté 8621.
- Partie 4 – Anti-Join Anti Pattern
- L'optimiseur ne définit un objectif de ligne pour appliquer l'anti-jointure que lorsqu'il existe une raison prometteuse de le faire.
- Malheureusement, plusieurs transformations d'optimisation interactives ajoutent un opérateur Top (1) à l'intérieur d'une application anti-jointure.
- L'opérateur Top est redondant ; il n'est pas nécessaire pour l'exactitude ou l'efficacité.
- Le Top définit toujours un objectif de ligne (contrairement à l'application, qui a besoin d'une bonne raison).
- L'objectif de ligne injustifié peut entraîner des performances extrêmement médiocres.
- Attention au sous-arbre potentiellement coûteux sous le sommet artificiel (1).