En grandissant, j'adorais les jeux qui testaient la mémoire et les compétences en correspondance de motifs. Plusieurs de mes amis avaient Simon, alors que j'avais une contrefaçon appelée Einstein. D'autres avaient un Atari Touch Me, ce qui, même à l'époque, je savais que c'était une décision de nommage discutable. De nos jours, la correspondance de modèles signifie quelque chose de très différent pour moi et peut être une partie coûteuse des requêtes de base de données quotidiennes.
En grandissant, j'adorais les jeux qui testaient la mémoire et les compétences en correspondance de motifs. Plusieurs de mes amis avaient Simon, alors que j'avais une contrefaçon appelée Einstein. D'autres avaient un Atari Touch Me, ce qui, même à l'époque, je savais que c'était une décision de nommage discutable. De nos jours, la correspondance de modèles signifie quelque chose de très différent pour moi et peut être une partie coûteuse des requêtes de base de données quotidiennes.
Je suis récemment tombé sur quelques commentaires sur Stack Overflow où un utilisateur déclarait, comme si c'était un fait, que CHARINDEX fonctionne mieux que LEFT ou LIKE . Dans un cas, la personne a cité un article de David Lozinski, "SQL :LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Oui, l'article montre que, dans l'exemple artificiel, CHARINDEX a le mieux performé. Cependant, étant donné que je suis toujours sceptique à propos de déclarations générales comme celle-ci, et que je ne pouvais pas penser à une raison logique pour laquelle une fonction de chaîne serait toujours faire mieux qu'un autre, toutes choses étant égales par ailleurs , j'ai couru ses tests. Effectivement, j'ai eu des résultats différents de manière répétée sur ma machine (cliquez pour agrandir) :
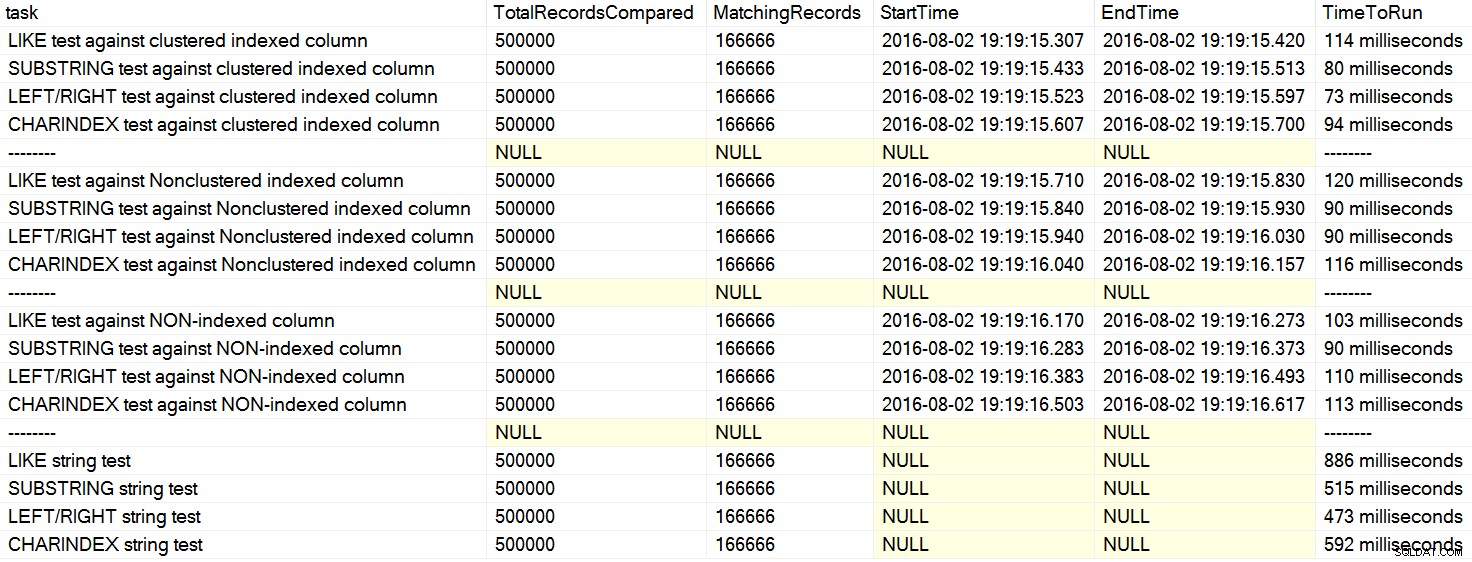 Sur ma machine, CHARINDEX était plus lent que GAUCHE/DROITE/SOUS-CHAÎNE.
Sur ma machine, CHARINDEX était plus lent que GAUCHE/DROITE/SOUS-CHAÎNE.
Les tests de David comparaient essentiellement ces structures de requête - recherchant un modèle de chaîne au début ou à la fin d'une valeur de colonne - en termes de durée brute :
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern ; WHERE SUBSTRING(Column, 1, LEN(@pattern)) =@pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) =@pattern; WHERE LEFT(Column, LEN(@pattern)) =@pattern OR RIGHT(Column, LEN(@pattern)) =@pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern )), 0)> 0 ;
En regardant simplement ces clauses, vous pouvez voir pourquoi CHARINDEX peut être moins efficace - il effectue plusieurs appels fonctionnels supplémentaires que les autres approches n'ont pas à effectuer. Pourquoi cette approche a mieux fonctionné sur la machine de David, je ne suis pas sûr ; peut-être a-t-il exécuté le code exactement tel qu'il a été publié et n'a pas vraiment supprimé les tampons entre les tests, de sorte que ces derniers tests ont bénéficié des données mises en cache.
En théorie, CHARINDEX aurait pu être exprimé plus simplement, par exemple :
WHERE CHARINDEX(@pattern, Column) =1 OR CHARINDEX(@pattern, Column) =LEN(Column) - LEN(@pattern) + 1 ;
(Mais cela a en fait été encore pire lors de mes tests occasionnels.)
Et pourquoi ce sont même OR conditions, je ne suis pas sûr. De manière réaliste, la plupart du temps, vous effectuez l'un des deux types de recherche de modèles :commence par ou contient (il est beaucoup moins courant de chercher se termine par ). Et dans la plupart de ces cas, l'utilisateur a tendance à indiquer à l'avance s'il veut commence par ou contient , du moins dans toutes les candidatures auxquelles j'ai participé au cours de ma carrière.
Il est logique de les séparer en tant que types de requêtes distincts, au lieu d'utiliser un OU conditionnel, puisque commence par peut utiliser un index (s'il en existe un qui convient suffisamment pour une recherche ou qui est plus fin que l'index clusterisé), tandis que se termine par ne peut pas (et OU conditions ont tendance à jeter des clés sur l'optimiseur en général). Si je peux faire confiance à LIKE pour utiliser un index quand il le peut, et pour fonctionner aussi bien ou mieux que les autres solutions ci-dessus dans la plupart ou dans tous les cas, alors je peux rendre cette logique très simple. Une procédure stockée peut prendre deux paramètres :le modèle recherché et le type de recherche à effectuer (il existe généralement quatre types de correspondance de chaînes :commence par, se termine par, contient ou correspond exactement).
CREATE PROCEDURE dbo.Search @pattern nvarchar(100), @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains' -- les deux derniers sont pris en charge mais ne seront pas testés hereASBEGIN SET NOCOUNT ON ; SELECT ... WHERE Colonne LIKE -- si contient ou se termine par, nécessite un caractère générique de tête CASE WHEN @option IN ('Contient','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- if contient ou commence par, nécessite un caractère générique de fin CASE WHEN @option IN ('Contient','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO
Cela gère chaque cas potentiel sans utiliser SQL dynamique ; l'OPTION (RECOMPILE) est là parce que vous ne voudriez pas qu'un plan optimisé pour "se termine par" (qui devra presque certainement analyser) soit réutilisé pour une requête "commence par", ou vice-versa ; cela garantira également que les estimations sont correctes ("commence par S" a probablement une cardinalité très différente de "commence par QX"). Même si vous avez un scénario où les utilisateurs choisissent un type de recherche 99 % du temps, vous pouvez utiliser SQL dynamique ici au lieu de recompiler, mais dans ce cas, vous seriez toujours vulnérable au reniflage de paramètres. Dans de nombreuses requêtes logiques conditionnelles, la recompilation et/ou le SQL dynamique complet sont souvent l'approche la plus sensée (voir mon article sur "l'évier de cuisine").
Les épreuves
Depuis que j'ai récemment commencé à regarder la nouvelle base de données d'exemples WideWorldImporters, j'ai décidé d'y exécuter mes propres tests. Il était difficile de trouver une table de taille décente sans un index ColumnStore ou une table d'historique temporel, mais Sales.Invoices , qui a 70 510 lignes, a un simple nvarchar(20) colonne appelée CustomerPurchaseOrderNumber que j'ai décidé d'utiliser pour les tests. (Pourquoi c'est nvarchar(20) lorsque chaque valeur est un nombre à 5 chiffres, je n'en ai aucune idée, mais la correspondance de modèle ne se soucie pas vraiment de savoir si les octets en dessous représentent des nombres ou des chaînes.)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Modèle | Nombre de lignes | % du tableau |
| Commence par "1" | 70 505 | 99,993 % |
| Commence par "2" | 5 | 0,007 % |
| Se termine par "5" | 6 897 | 9,782 % |
| Se termine par "30" | 749 | 1,062 % |
J'ai fouillé les valeurs du tableau pour trouver plusieurs critères de recherche qui produiraient des nombres de lignes très différents, dans l'espoir de révéler tout comportement de point de basculement avec une approche donnée. À droite se trouvent les requêtes de recherche sur lesquelles j'ai atterri.
Je voulais me prouver que la procédure ci-dessus était indéniablement meilleure dans l'ensemble pour toutes les recherches possibles que n'importe laquelle des requêtes utilisant OR conditionnels, qu'ils utilisent ou non LIKE , LEFT/RIGHT , SUBSTRING , ou CHARINDEX . J'ai pris les structures de requête de base de David et les ai mises dans des procédures stockées (avec la mise en garde que je ne peux pas vraiment tester "contient" sans son entrée, et que j'ai dû faire son OR logique un peu plus flexible pour obtenir le même nombre de lignes), ainsi qu'une version de ma logique. J'ai également prévu de tester les procédures avec et sans index que je créerais sur la colonne de recherche, et sous un cache chaud et froid.
Les procédures :
CREATE PROCEDURE dbo.David_LIKE @pattern nvarchar(10), @option varchar(10) -- StartsWith ou EndsWithASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CustomerPurchaseOrderNumber LIKE @pattern + N'%') OU (@option ='EndsWith' AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING @pattern nvarchar(10), @option varchar(10) -- StartsWith ou EndsWithASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern) OU (@option ='EndsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)) =@pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT @pattern nvarchar(10), @option varchar(10) -- StartsWith ou EndsWithASBEGIN SET NOCOUNT SUR; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) OU (@option ='EndsWith' AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX @pattern nvarchar(10), @option varchar(10) -- StartsWith ou EndsWithASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0) OU (@option ='EndsWith' AND CHARINDEX (@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)), 0)> 0) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.Aaron_Conditional @pattern nvarchar(10) , @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contient'ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE -- si contient ou se termine par, besoin d'un caractère générique au début CASE WHEN @option IN ('Contient','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- si contient ou commence par, besoin d'un caractère générique de fin CASE WHEN @option IN ('Contient','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO
J'ai également créé des versions des procédures de David fidèles à son intention initiale, en supposant que l'exigence est vraiment de trouver toutes les lignes où le modèle de recherche se trouve au début *ou* à la fin de la chaîne. Je l'ai fait simplement pour pouvoir comparer les performances des différentes approches, exactement comme il les a écrites, pour voir si sur cet ensemble de données mes résultats correspondraient à mes tests de son script original sur mon système. Dans ce cas, il n'y avait aucune raison d'introduire une version de moi-même, car elle correspondrait simplement à son LIKE % + @pattern OR LIKE @pattern + % variation.
CREATE PROCEDURE dbo.David_LIKE_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON ; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%' OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern OR SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)) =@ pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX_Original @pattern nvarchar (10) COMMENCEZ À NE PAS DÉCOMPTER ; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern ) + 1, LEN(@pattern)), 0)> 0 OPTION (RECOMPILE);ENDGO
Avec les procédures en place, j'ai pu générer le code de test - ce qui est souvent aussi amusant que le problème d'origine. Tout d'abord, une table de journalisation :
DOP TABLE IF EXISTS dbo.LoggingTable;GOSET NOCOUNT ON; CREATE TABLE dbo.LoggingTable( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME());Ensuite, le code qui effectuerait les opérations de sélection en utilisant les différentes procédures et arguments :
SET NOCOUNT ON ;;WITH prc(nom) AS ( SELECT nom FROM sys.procedures WHERE LEFT(nom,5) IN (N'David', N'Aaron')),args(opt,pattern) AS ( SELECT 'StartsWith', N' 1' UNION ALL SELECT 'StartsWith', N'2' UNION ALL SELECT 'EndsWith', N'5' UNION ALL SELECT 'EndsWith', N'30'),frame(w) AS ( SELECT 'BeforeIndex' UNION ALL SELECT 'AfterIndex'),y AS( -- commentez les lignes 2 à 4 ici si nous voulons un cache chaud SELECT cmd ='GO DBCC FREEPROCCACHE() WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS; GO DECLARE @d datetime2, @delta int; SET @d =SYSUTCDATETIME(); EXEC dbo.' + prc.name + ' @pattern =N''' + args.pattern + '''' + CASE WHEN prc.name LIKE N'%_Original' THEN '' SINON ', @option =''' + args.opt + '''' FIN + '; SET @delta =DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME()); INSERT dbo.LoggingTable(prc,opt,pattern,frame ,durée) SELECT N''' + prc.name + ''',''' + args.opt + ''',N''' + args.pattern + ''',''' + frame.w + ''',@delta; ', *, rn =ROW_NUMBER() SUR (PARTITION N BY frame.w ORDER BY frame.w DESC, LEN(prc.name), args.opt DESC, args.pattern) FROM prc CROSS JOIN args CROSS JOIN frame)SELECT cmd =cmd + CASE WHEN rn =36 THEN CASE WHEN w ='BeforeIndex' THEN 'CREATE INDEX testing ON '+ 'Sales.Invoices(CustomerPurchaseOrderNumber); ' ELSE 'DROP INDEX Sales.Invoices.testing;' END ELSE '' END--, name, opt, pattern, w, rn FROM yORDER BY w DESC, rn;Résultats
J'ai exécuté ces tests sur une machine virtuelle, exécutant Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), avec 4 CPU et 32 Go de RAM. J'ai exécuté chaque ensemble de tests 11 fois; pour les tests de cache à chaud, j'ai rejeté le premier ensemble de résultats car certains d'entre eux étaient vraiment des tests de cache à froid.
J'ai eu du mal à représenter graphiquement les résultats pour montrer des modèles, principalement parce qu'il n'y avait tout simplement pas de modèles. Presque toutes les méthodes étaient les meilleures dans un scénario et les pires dans un autre. Dans les tableaux suivants, j'ai mis en évidence la procédure la plus et la moins performante pour chaque colonne, et vous pouvez voir que les résultats sont loin d'être concluants :
Dans ces tests, parfois CHARINDEX a gagné, et parfois non.
Ce que j'ai appris, c'est que, dans l'ensemble, si vous allez être confronté à de nombreuses situations différentes (différents types de correspondance de motifs, avec un index de support ou non, les données ne peuvent pas toujours être en mémoire), il n'y a vraiment pas gagnant clair, et la gamme de performances en moyenne est assez petite (en fait, comme un cache chaud n'a pas toujours aidé, je soupçonnerais que les résultats étaient davantage affectés par le coût de rendu des résultats que par leur récupération). Pour les scénarios individuels, ne vous fiez pas à mes tests ; exécutez vous-même des tests de performance en fonction de votre matériel, de votre configuration, de vos données et de vos habitudes d'utilisation.
Mises en garde
Certaines choses que je n'ai pas prises en compte pour ces tests :
- En cluster ou non en cluster . Étant donné qu'il est peu probable que votre index clusterisé se trouve sur une colonne où vous effectuez des recherches de correspondance de modèle par rapport au début ou à la fin de la chaîne, et qu'une recherche sera en grande partie la même dans les deux cas (et que les différences entre les analyses seront en grande partie être fonction de la largeur de l'index par rapport à la largeur de la table), j'ai uniquement testé les performances en utilisant un index non clusterisé. Si vous avez des scénarios spécifiques où cette différence à elle seule fait une différence profonde sur la correspondance de modèles, veuillez m'en informer.
- Types MAX . Si vous recherchez des chaînes dans
varchar(max)/nvarchar(max), ceux-ci ne peuvent pas être indexés, donc à moins que vous n'utilisiez des colonnes calculées pour représenter des parties de la valeur, une analyse sera nécessaire - que vous recherchiez commence par, se termine par ou contient. Que la surcharge de performances soit corrélée à la taille de la chaîne ou qu'une surcharge supplémentaire soit introduite simplement en raison du type, je n'ai pas testé.
- Recherche plein texte . J'ai joué avec cette fonctionnalité ici et là, et je peux l'épeler, mais si ma compréhension est correcte, cela ne peut être utile que si vous recherchez des mots entiers non-stop, et que vous ne vous souciez pas de savoir où ils se trouvaient dans la chaîne. trouvé. Cela ne serait pas utile si vous stockiez des paragraphes de texte et vouliez trouver tous ceux qui commencent par "Y", contiennent le mot "le" ou se terminent par un point d'interrogation.
Résumé
La seule déclaration générale que je puisse faire en m'éloignant de ce test est qu'il n'y a pas de déclaration générale sur le moyen le plus efficace d'effectuer une correspondance de modèle de chaîne. Bien que je sois biaisé envers mon approche conditionnelle pour la flexibilité et la maintenabilité, ce n'était pas le gagnant des performances dans tous les scénarios. Pour moi, à moins que je ne rencontre un goulot d'étranglement de performance et que je poursuive toutes les voies, je continuerai à utiliser mon approche pour plus de cohérence. Comme je l'ai suggéré ci-dessus, si vous avez un scénario très étroit et que vous êtes très sensible aux petites différences de durée, vous voudrez exécuter vos propres tests pour déterminer quelle méthode est toujours la plus performante pour vous.