Un développeur Oracle qui utilise souvent des expressions régulières dans le code tôt ou tard peut faire face à un phénomène qui est en effet mystique. La recherche à long terme de la racine du problème peut entraîner une perte de poids, de l'appétit et provoquer divers types de troubles psychosomatiques - tout cela peut être évité à l'aide de la fonction regexp_replace. Il peut avoir jusqu'à 6 arguments :
REGEXP_REPLACE (
- chaîne_source,
- modèle,
- substituting_string,
- la position de départ de la recherche de correspondance avec un modèle (1 par défaut),
- une position d'occurrence du modèle dans une chaîne source (par défaut 0 équivaut à toutes les occurrences),
- modificateur (jusqu'à présent, c'est un cheval noir)
)
Renvoie la chaîne_source modifiée dans laquelle toutes les occurrences du modèle sont remplacées par la valeur passée dans le paramètre chaîne_substituante. Souvent, une version courte de la fonction est utilisée, où les 3 premiers arguments sont spécifiés, ce qui est suffisant pour résoudre de nombreux problèmes. Je vais faire la même chose. Supposons que nous ayons besoin de masquer tous les caractères de la chaîne avec des astérisques dans la chaîne "MASQUE :minuscules". Pour spécifier la plage de caractères minuscules, le modèle "[a-z]" doit convenir.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Attente
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Réalité
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Si cet événement n'a pas été reproduit dans votre base de données, alors vous avez de la chance jusqu'à présent. Mais le plus souvent, vous commencez à creuser dans le code, convertissez des chaînes d'un ensemble de caractères à un autre et finalement, le désespoir survient.
Définir un problème
La question se pose :qu'y a-t-il de si spécial dans la lettre « A » pour qu'elle n'ait pas été remplacée, car le reste des caractères majuscules n'étaient pas censés être remplacés également ? Peut-être y a-t-il d'autres lettres correctes à part celle-ci. Il faut regarder tout l'alphabet des majuscules.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Cependant
Si le 6ème argument de la fonction n'est pas explicitement spécifié, par exemple, 'i' est insensible à la casse ou 'c' est sensible à la casse lors de la comparaison d'une chaîne source à un modèle, le L'expression régulière utilise le paramètre NLS_SORT de la session/base de données par défaut. Par exemple :
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Ce paramètre spécifie la méthode de tri dans ORDER BY. Si nous parlons de trier des caractères individuels simples, alors un certain nombre binaire (code NLSSORT) correspond à chacun d'eux et le tri s'effectue en fait par la valeur de ces nombres.
Pour illustrer cela, prenons les premiers et les derniers caractères de l'alphabet, en minuscules et en majuscules, et plaçons-les dans un ensemble de tableaux conditionnellement non ordonnés et appelons-le ABC. Ensuite, trions cet ensemble par le champ SYMBOL et affichons son code NLSSORT au format HEX à côté de chaque symbole.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
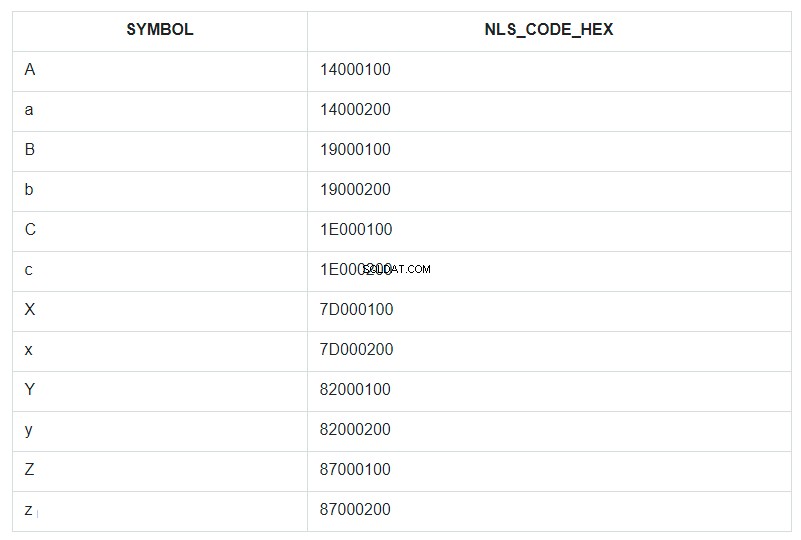
Dans la requête, ORDER BY est spécifié pour le champ SYMBOL, mais en fait, dans la base de données, le tri s'est effectué sur les valeurs du champ NLS_CODE_HEX.
Maintenant, revenez à la plage du modèle et regardez le tableau :qu'y a-t-il de vertical entre le symbole « a » (code 14000200) et « z » (code 87000200) ? Tout sauf la lettre majuscule « A ». C'est tout ce qui a été remplacé par un astérisque. Et le code 14000100 de la lettre "A" n'est pas inclus dans la plage de remplacement de 14000200 à 87000200.
Remède
Spécifiez explicitement le modificateur de sensibilité à la casse
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Certaines sources disent que le modificateur "c" est défini par défaut, mais nous venons de voir que ce n'est pas tout à fait vrai. Et si quelqu'un ne l'a pas vu, alors le paramètre NLS_SORT de sa session/base de données est très probablement défini sur BINARY et le tri est effectué en correspondance avec les codes réels des caractères. En effet, si vous modifiez le paramètre de session, le problème sera résolu.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Les tests ont été effectués dans Oracle 12c.
N'hésitez pas à laisser vos commentaires et prenez soin de vous.



