Plus tôt ce mois-ci, j'ai publié une astuce sur quelque chose que nous souhaiterions probablement tous ne pas avoir à faire :trier ou supprimer les doublons de chaînes délimitées, impliquant généralement des fonctions définies par l'utilisateur (UDF). Parfois, vous devez réassembler la liste (sans les doublons) dans l'ordre alphabétique, et parfois vous devrez peut-être conserver l'ordre d'origine (il peut s'agir de la liste des colonnes clés dans un mauvais index, par exemple).
Pour ma solution, qui traite les deux scénarios, j'ai utilisé une table de nombres, ainsi qu'une paire de fonctions définies par l'utilisateur (UDF) - l'une pour diviser la chaîne, l'autre pour la réassembler. Vous pouvez voir cette astuce ici :
- Suppression des doublons des chaînes dans SQL Server
Bien sûr, il existe plusieurs façons de résoudre ce problème; Je fournissais simplement une méthode à essayer si vous êtes coincé avec ces données de structure. @Phil_Factor de Red-Gate a suivi avec un post rapide montrant son approche, qui évite les fonctions et le tableau des nombres, optant à la place pour la manipulation XML en ligne. Il dit qu'il préfère avoir des requêtes à instruction unique et éviter à la fois les fonctions et le traitement ligne par ligne :
- Déduplication des listes délimitées dans SQL Server
Puis un lecteur, Steve Mangiameli, a posté une solution en boucle en commentaire de l'astuce. Son raisonnement était que l'utilisation d'une table de nombres lui semblait trop technique.
Nous n'avons pas tous les trois réussi à aborder un aspect de cela qui sera généralement assez important si vous effectuez la tâche assez souvent ou à n'importe quel niveau :performance .
Test
Curieux de voir à quel point les approches XML en ligne et en boucle fonctionneraient par rapport à ma solution basée sur une table de nombres, j'ai construit une table fictive pour effectuer des tests ; mon objectif était de 5 000 lignes, avec une longueur de chaîne moyenne supérieure à 250 caractères et au moins 10 éléments dans chaque chaîne. Avec un cycle d'expériences très court, j'ai pu réaliser quelque chose de très proche de cela avec le code suivant :
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Cela a produit un tableau avec des exemples de lignes ressemblant à ceci (valeurs tronquées) :
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Les données dans leur ensemble avaient le profil suivant, qui devrait être suffisamment bon pour découvrir d'éventuels problèmes de performances :
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Notez que je suis passé à varchar ici depuis nvarchar dans l'article d'origine, car les exemples fournis par Phil et Steve supposaient varchar , des chaînes ne dépassant pas 255 ou 8 000 caractères, des délimiteurs à un seul caractère, etc. possible - idéalement rien. En réalité, j'utiliserais toujours nvarchar et ne supposez rien sur la chaîne la plus longue possible. Dans ce cas, je savais que je ne perdais aucune donnée car la chaîne la plus longue ne comporte que 2 905 caractères et, dans cette base de données, je n'ai aucune table ou colonne utilisant des caractères Unicode.
Ensuite, j'ai créé mes fonctions (qui nécessitent une table de nombres). Un lecteur a repéré un problème dans la fonction dans mon conseil, où j'ai supposé que le délimiteur serait toujours un seul caractère, et j'ai corrigé cela ici. J'ai également converti à peu près tout en varchar(8000) pour uniformiser les règles du jeu en termes de types et de longueurs de cordes.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Ensuite, j'ai créé une seule fonction table en ligne qui combinait les deux fonctions ci-dessus, ce que j'aurais aimé faire dans l'article d'origine, afin d'éviter complètement la fonction scalaire. (Bien qu'il soit vrai que tous les fonctions scalaires sont terribles à grande échelle, il y a très peu d'exceptions.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
J'ai également créé des versions distinctes du TVF en ligne dédiées à chacun des deux choix de tri, afin d'éviter la volatilité du CASE expression, mais il s'est avéré qu'elle n'avait pas du tout d'impact dramatique.
Ensuite, j'ai créé les deux fonctions de Steve :
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Ensuite, j'ai mis les requêtes directes de Phil dans mon banc de test (notez que ses requêtes encodent < comme < pour les protéger des erreurs d'analyse XML, mais ils n'encodent pas > ou & - J'ai ajouté des espaces réservés au cas où vous auriez besoin de vous prémunir contre les chaînes susceptibles de contenir ces caractères problématiques) :
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Le banc d'essai était essentiellement ces deux requêtes, ainsi que les appels de fonction suivants. Une fois que j'ai validé qu'ils renvoyaient tous les mêmes données, j'ai intercalé le script avec DATEDIFF résultat et l'a consigné dans une table :
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Et puis j'ai effectué des tests de performances sur deux systèmes différents (un quadricœur avec 8 Go et une machine virtuelle à 8 cœurs avec 32 Go), et dans chaque cas, sur SQL Server 2012 et SQL Server 2016 CTP 3.2 (13.0.900.73).
Résultats
Les résultats que j'ai observés sont résumés dans le tableau suivant, qui montre la durée en millisecondes de chaque type de requête, en moyenne sur l'ordre alphabétique et d'origine, les quatre combinaisons serveur/version et une série de 15 exécutions pour chaque permutation. Cliquez pour agrandir :
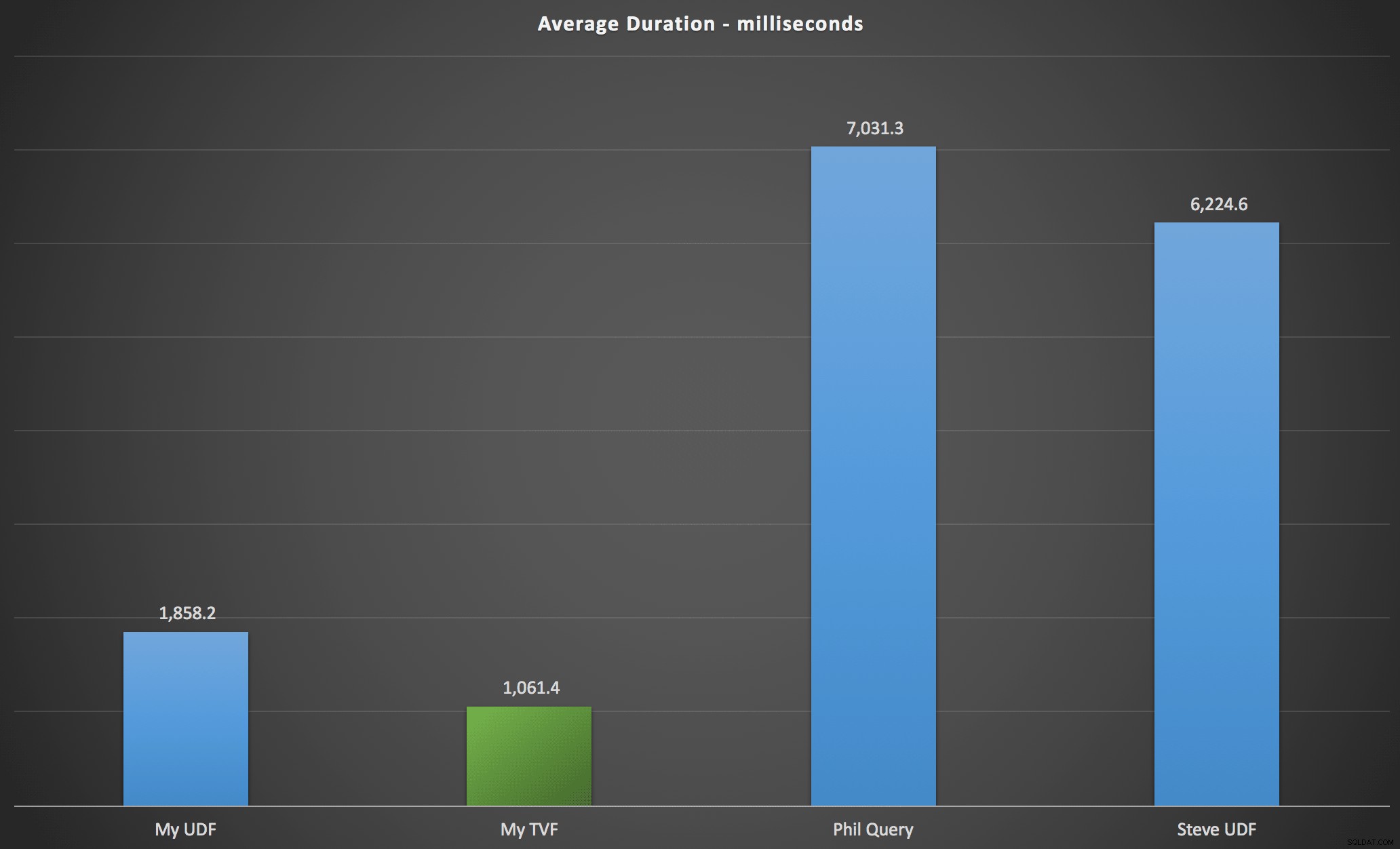
Cela montre que la table des nombres, bien que jugée sur-conçue, a en fait donné la solution la plus efficace (au moins en termes de durée). C'était mieux, bien sûr, avec le TVF unique que j'ai implémenté plus récemment qu'avec les fonctions imbriquées de l'article original, mais les deux solutions tournent en rond autour des deux alternatives.
Pour entrer plus en détail, voici les répartitions pour chaque machine, version et type de requête, pour maintenir l'ordre d'origine :
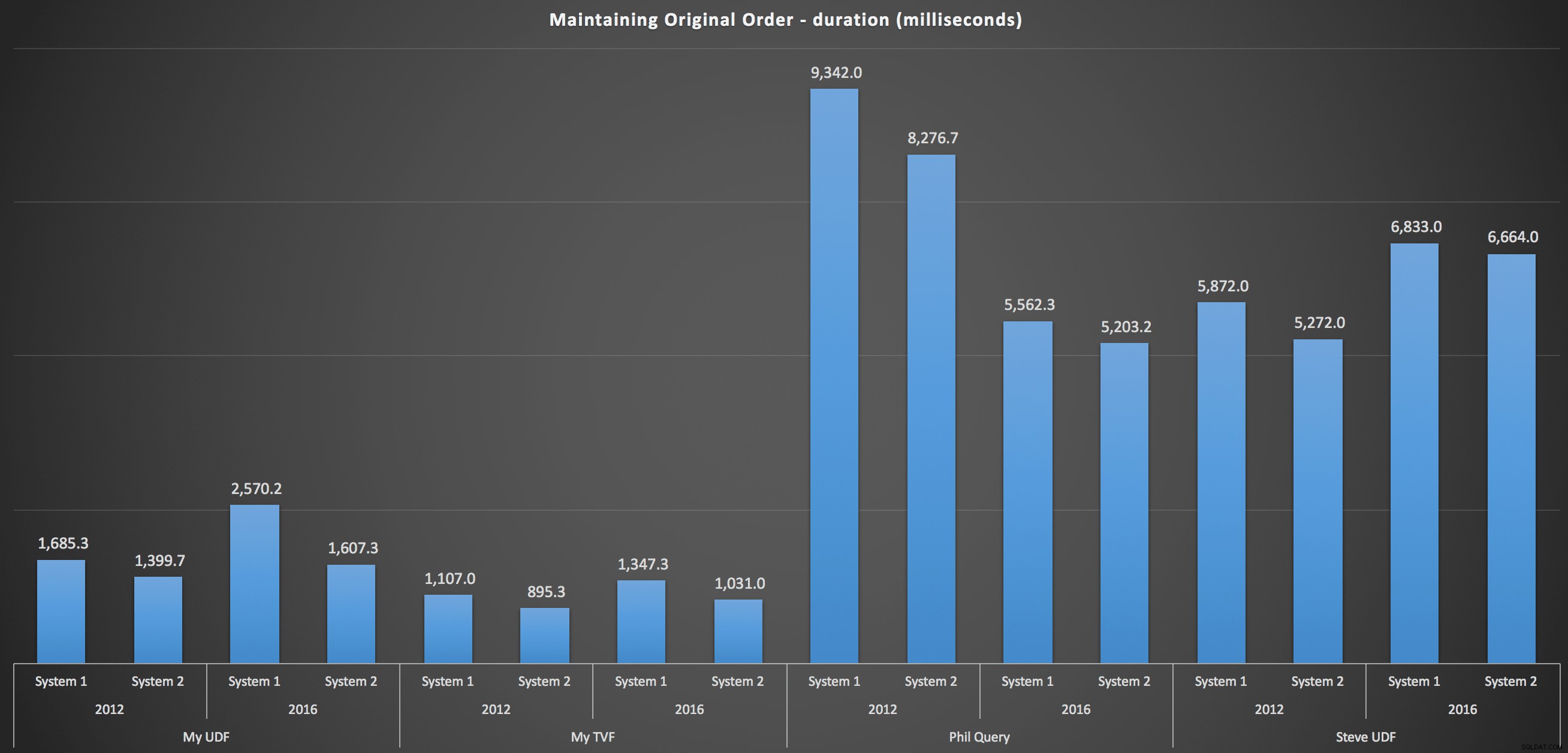
…et pour remonter la liste par ordre alphabétique :
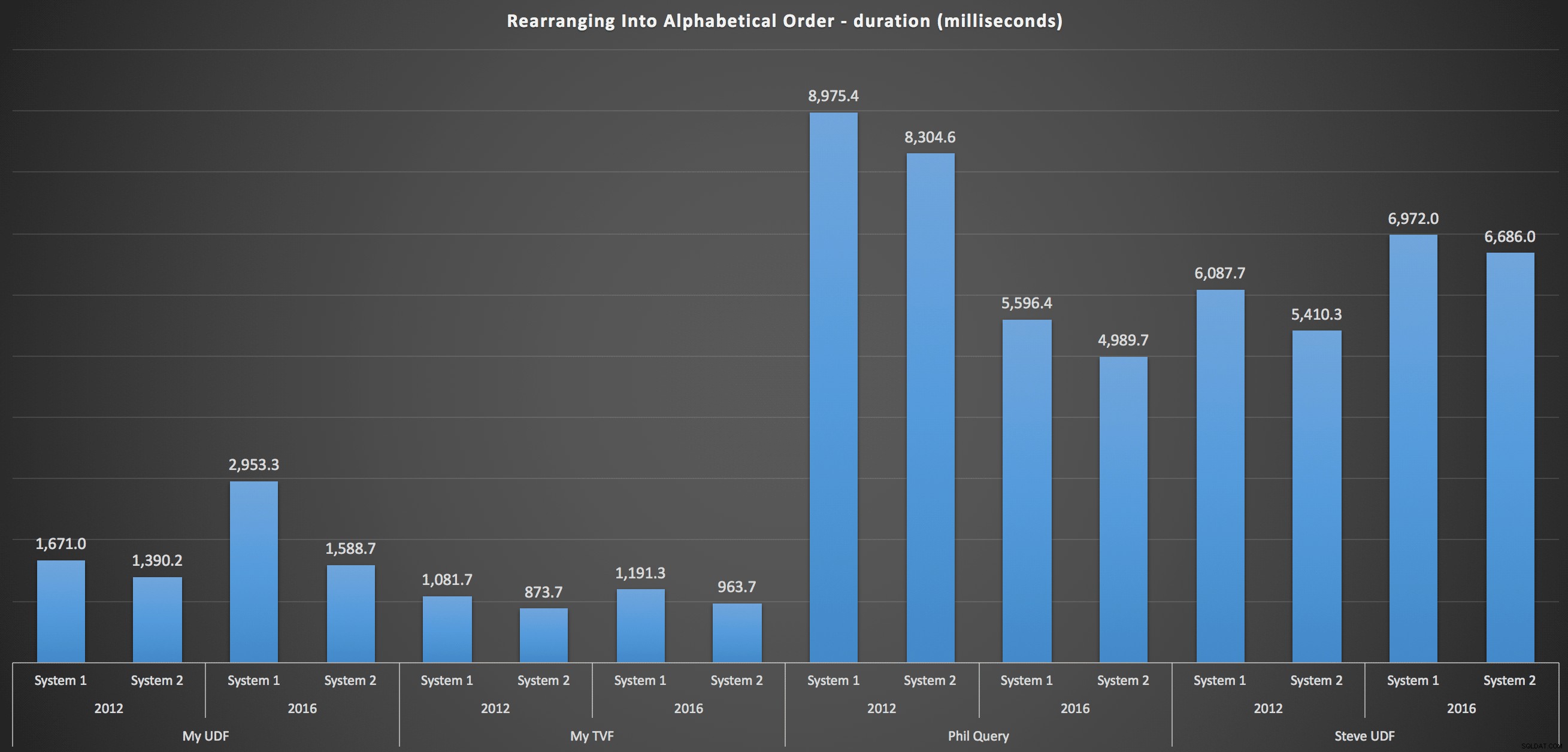
Ceux-ci montrent que le choix de tri a peu d'impact sur le résultat - les deux graphiques sont pratiquement identiques. Et cela a du sens car, compte tenu de la forme des données d'entrée, je ne peux imaginer aucun index qui rendrait le tri plus efficace - c'est une approche itérative, peu importe comment vous les découpez ou comment vous renvoyez les données. Mais il est clair que certaines approches itératives peuvent être généralement pires que d'autres, et ce n'est pas nécessairement l'utilisation d'une FDU (ou d'une table de nombres) qui les rend ainsi.
Conclusion
Jusqu'à ce que nous ayons une fonctionnalité native de fractionnement et de concaténation dans SQL Server, nous allons utiliser toutes sortes de méthodes non intuitives pour faire le travail, y compris des fonctions définies par l'utilisateur. Si vous manipulez une seule chaîne à la fois, vous ne verrez pas beaucoup de différence. Mais à mesure que vos données évoluent, il vaudra la peine de tester différentes approches (et je ne suggère en aucun cas que les méthodes ci-dessus sont les meilleures que vous trouverez - je n'ai même pas regardé CLR, par exemple, ou autres approches T-SQL de cette série).