La demande croissante de systèmes à haute disponibilité et de SLA stricts nous pousse à remplacer les procédures manuelles par des solutions automatisées. Mais avez-vous le temps et les ressources nécessaires pour gérer vous-même la complexité des opérations de basculement ? Allez-vous sacrifier les temps d'arrêt de la base de données de production pour l'apprendre à la dure ?
ClusterControl fournit un support avancé pour la détection et la gestion des pannes. Il est utilisé par de nombreuses organisations d'entreprise, gardant les systèmes de production les plus critiques opérationnels en mode 24h/24 et 7j/7.
Cette solution de gestion de base de données vous accompagne également dans le déploiement de différents proxys de charge. Ces proxys jouent un rôle clé dans la pile HA, il n'est donc pas nécessaire d'ajuster la chaîne de connexion de l'application ou l'entrée DNS pour rediriger les connexions de l'application vers le nouveau nœud maître.
Lorsqu'une panne est détectée, ClusterControl effectue tout le travail de fond pour élire un nouveau maître, déployer des serveurs esclaves de basculement et configurer les équilibreurs de charge. Dans ce blog, vous apprendrez comment réaliser le basculement automatique de TimescaleDB dans vos systèmes de production.
Déployer des topologies de réplication entières
À partir de ClusterControl 1.7.2, vous pouvez déployer une configuration de réplication TimescaleDB complète de la même manière que vous déploieriez PostgreSQL :vous pouvez utiliser le menu "Déployer le cluster" pour déployer un serveur principal et un ou plusieurs serveurs de secours TimescaleDB. Voyons à quoi ça ressemble.
Tout d'abord, vous devez définir les détails d'accès lors du déploiement de nouveaux clusters à l'aide de ClusterControl. Il nécessite un accès par mot de passe root ou sudo à tous les nœuds sur lesquels votre nouveau cluster sera déployé.
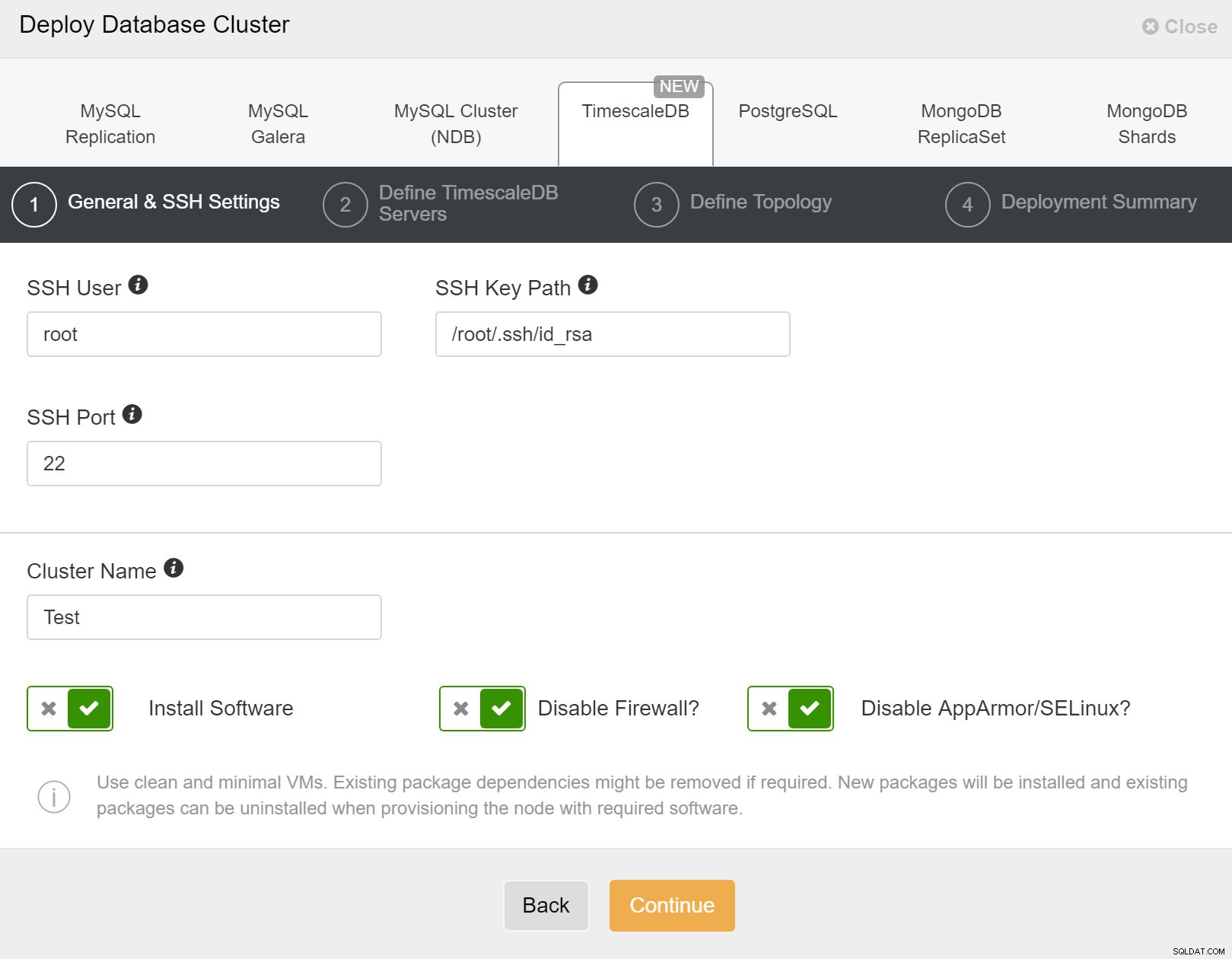 ClusterControl :Déployer un nouveau cluster
ClusterControl :Déployer un nouveau cluster Ensuite, nous devons définir l'utilisateur et le mot de passe de l'utilisateur TimescaleDB.
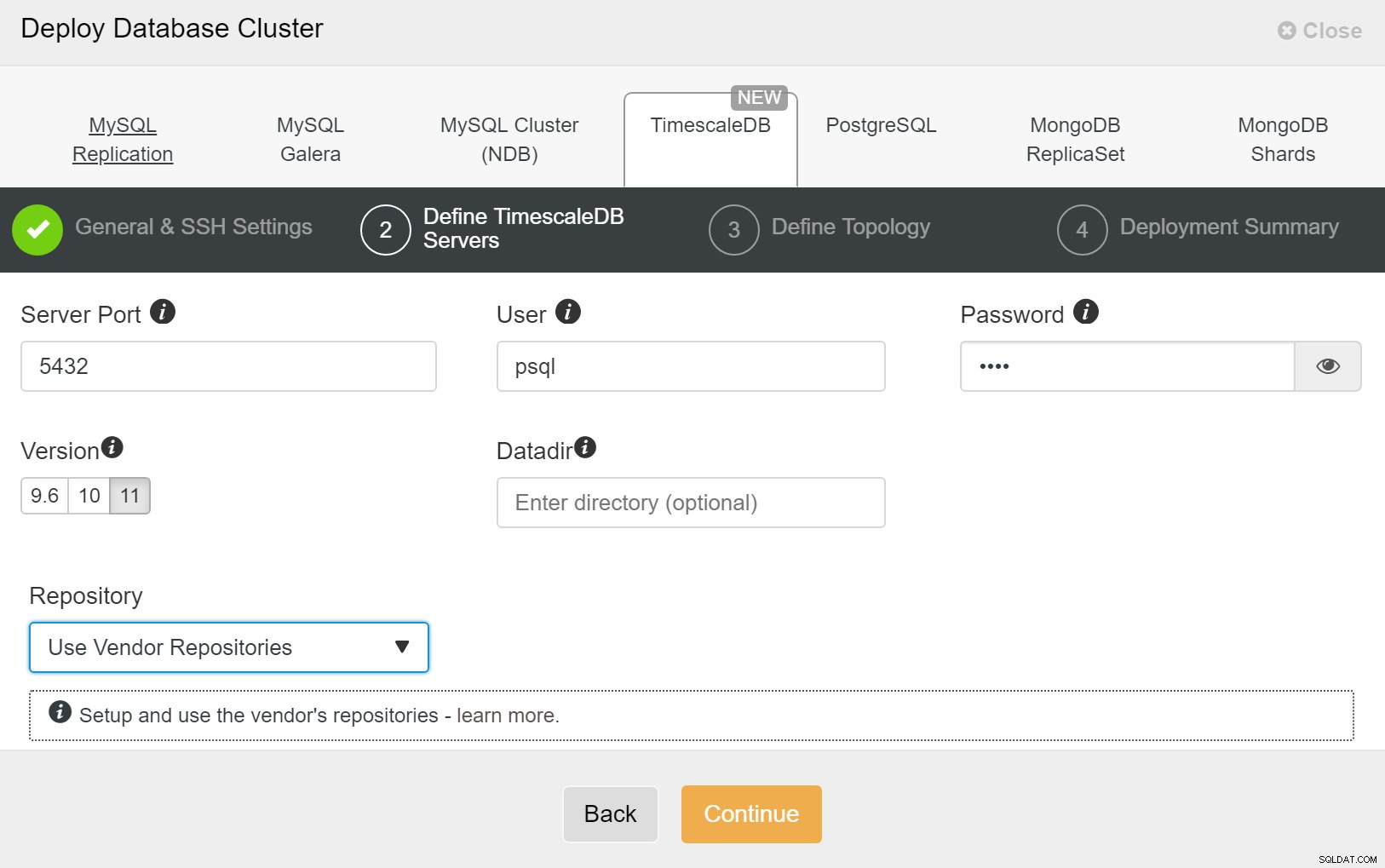 ClusterControl :Déployer le cluster de bases de données
ClusterControl :Déployer le cluster de bases de données Enfin, vous souhaitez définir la topologie - quel hôte doit être le principal et quels hôtes doivent être configurés en veille. Pendant que vous définissez les hôtes dans la topologie, ClusterControl vérifiera si l'accès ssh fonctionne comme prévu - cela vous permet de détecter rapidement tout problème de connectivité. Sur le dernier écran, il vous sera demandé le type de réplication synchrone ou asynchrone.
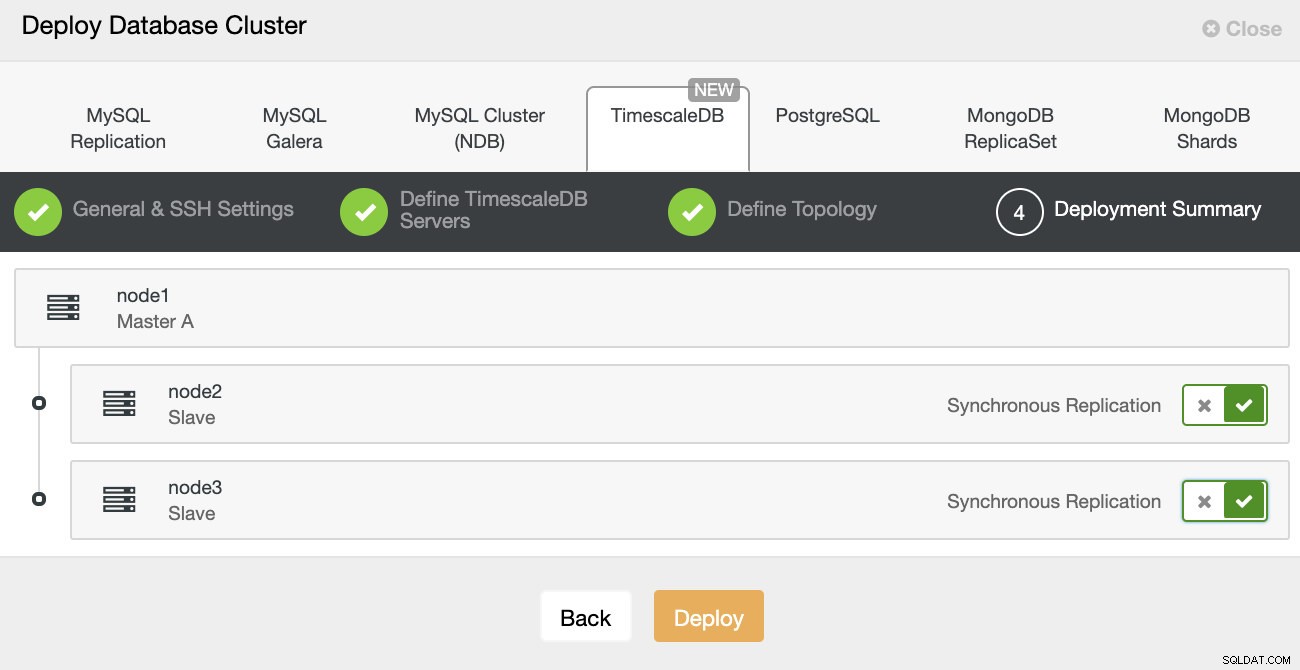 Déploiement de ClusterControl
Déploiement de ClusterControl Ça y est, il s'agit alors de lancer le déploiement. Une tâche est créée dans ClusterControl, et vous pourrez suivre sa progression.
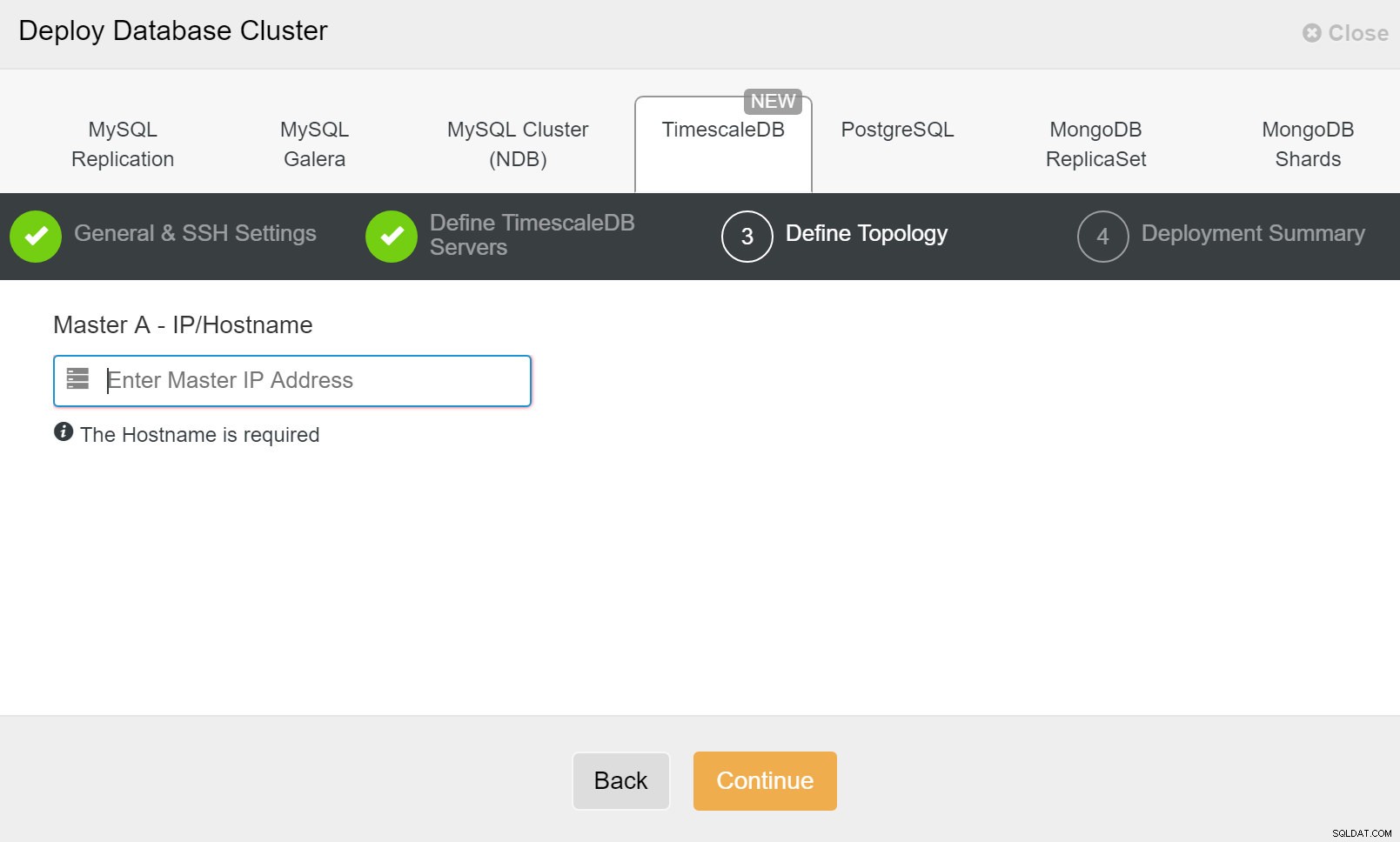 ClusterControl :définir la topologie pour le cluster TimescleDb
ClusterControl :définir la topologie pour le cluster TimescleDb Une fois que vous avez terminé, vous verrez la configuration de la topologie avec des rôles dans le cluster. Notez que nous avons également ajouté un équilibreur de charge (HAProxy) devant les instances de base de données afin que le basculement automatique ne nécessite pas de modifications des paramètres de connexion à la base de données.
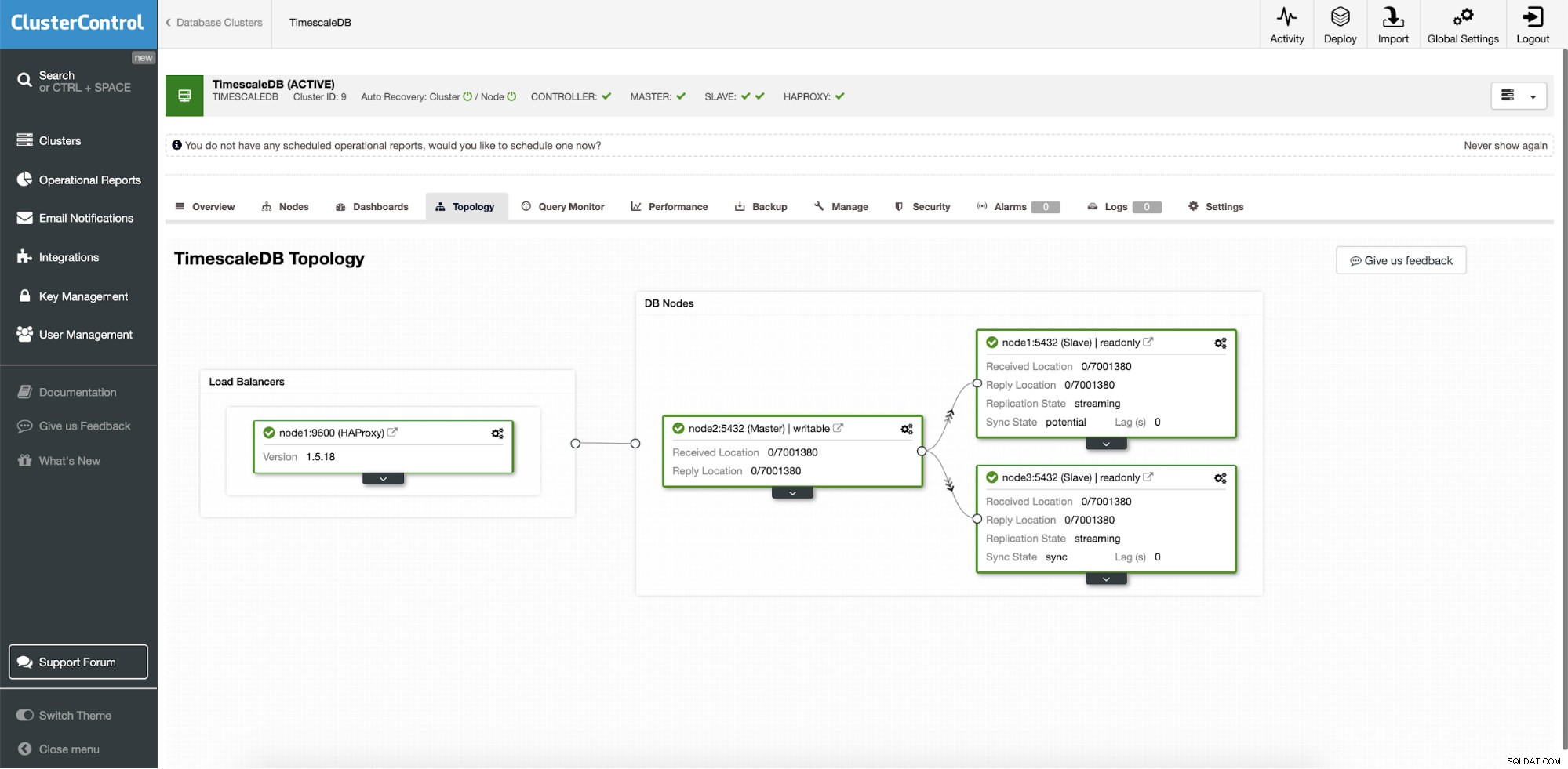 ClusterControl :Topologie
ClusterControl :Topologie Lorsque Timescale est déployé par ClusterControl, la récupération automatique est activée par défaut. L'état peut être vérifié dans la barre de cluster.
 ClusterControl :Récupération automatique de l'état du cluster et du nœud
ClusterControl :Récupération automatique de l'état du cluster et du nœud Configuration du basculement
Une fois la configuration de la réplication déployée, ClusterControl est capable de surveiller la configuration et de récupérer automatiquement tous les serveurs défaillants. Il peut également orchestrer des changements de topologie.
Le basculement automatique de ClusterControl a été conçu selon les principes suivants :
- Assurez-vous que le maître est vraiment mort avant de basculer
- Basculement une seule fois
- Ne pas basculer vers un esclave incohérent
- N'écrire qu'au maître
- Ne récupère pas automatiquement le maître défaillant
Grâce aux algorithmes intégrés, le basculement peut souvent être effectué assez rapidement afin que vous puissiez garantir les SLA les plus élevés pour votre environnement de base de données.
Le processus est paramétrable. Il est livré avec plusieurs paramètres que vous pouvez utiliser pour adapter la récupération aux spécificités de votre environnement.
| max_replication_lag | Délai de réplication maximal autorisé en secondes avant |
| replication_stop_on_error | Les procédures de basculement/basculement échoueront en cas d'erreurs susceptibles d'entraîner une perte de données. Activé par défaut. 0 signifie désactiver, |
| replication_auto_rebuild_slave | Si le SQL THREAD est arrêté et que le code d'erreur est différent de zéro, l'esclave sera automatiquement reconstruit. 1 signifie activer, 0 signifie désactiver (par défaut). |
| replication_failover_blacklist | Liste séparée par des virgules des paires hostname:port. Les serveurs sur liste noire ne seront pas considérés comme candidats lors du basculement. replication_failover_blacklist est ignoré si replication_failover_whitelist est défini. |
| replication_failover_whitelist | Liste séparée par des virgules des paires nom d'hôte :port. Seuls les serveurs en liste blanche seront considérés comme candidats lors du basculement. Si aucun serveur de la liste blanche n'est disponible (actif/connecté), le basculement échouera. replication_failover_blacklist est ignoré si replication_failover_whitelist est défini. |
Gestion du basculement
Lorsqu'une panne de maître est détectée, une liste de candidats maîtres est créée et l'un d'entre eux est choisi pour être le nouveau maître. Il est possible d'avoir une liste blanche de serveurs à promouvoir en primaire, ainsi qu'une liste noire de serveurs qui ne peuvent pas être promus en primaire. Les esclaves restants sont maintenant esclaves du nouveau primaire et l'ancien primaire n'est pas redémarré.
Ci-dessous, nous pouvons voir une simulation de défaillance de nœud.
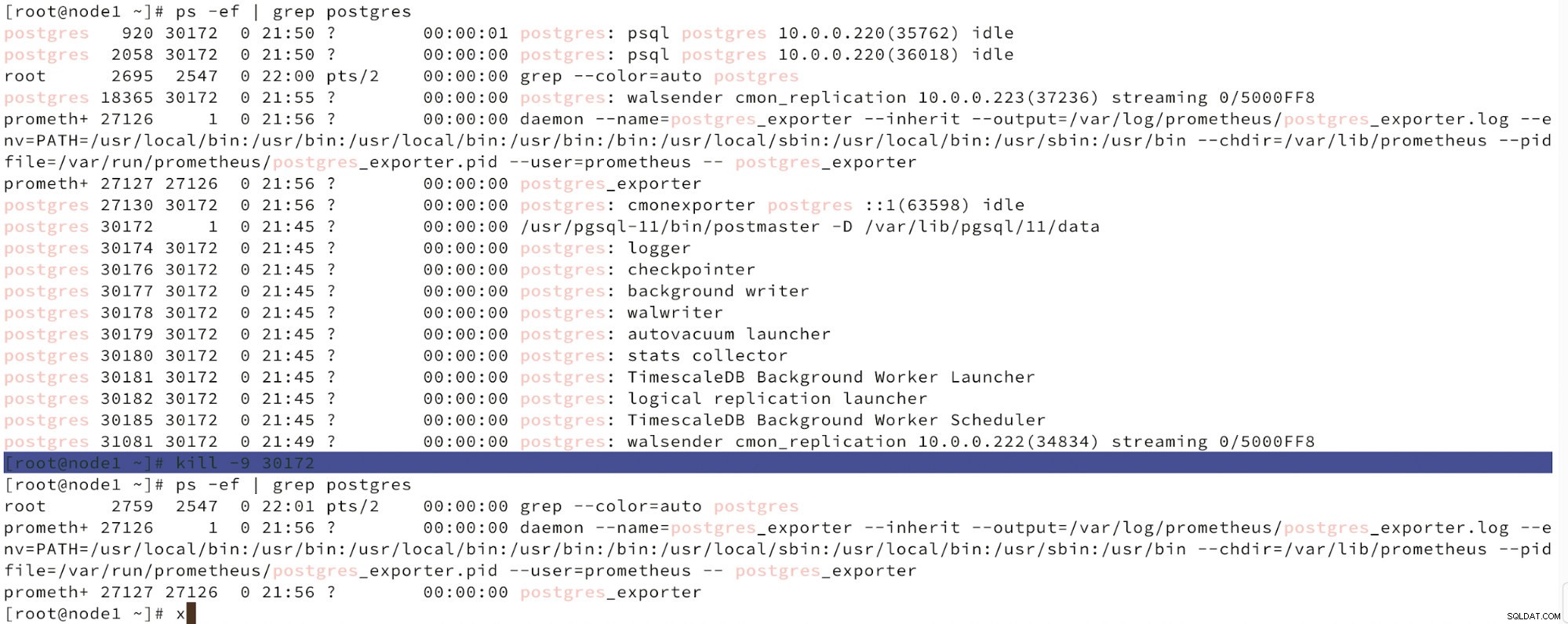 Simuler une panne de nœud maître avec kill
Simuler une panne de nœud maître avec kill Lorsqu'un dysfonctionnement des nœuds est détecté et que la récupération automatique est détectée, ClusterControl déclenche une tâche pour effectuer un basculement. Ci-dessous, nous pouvons voir les actions entreprises pour récupérer le cluster.
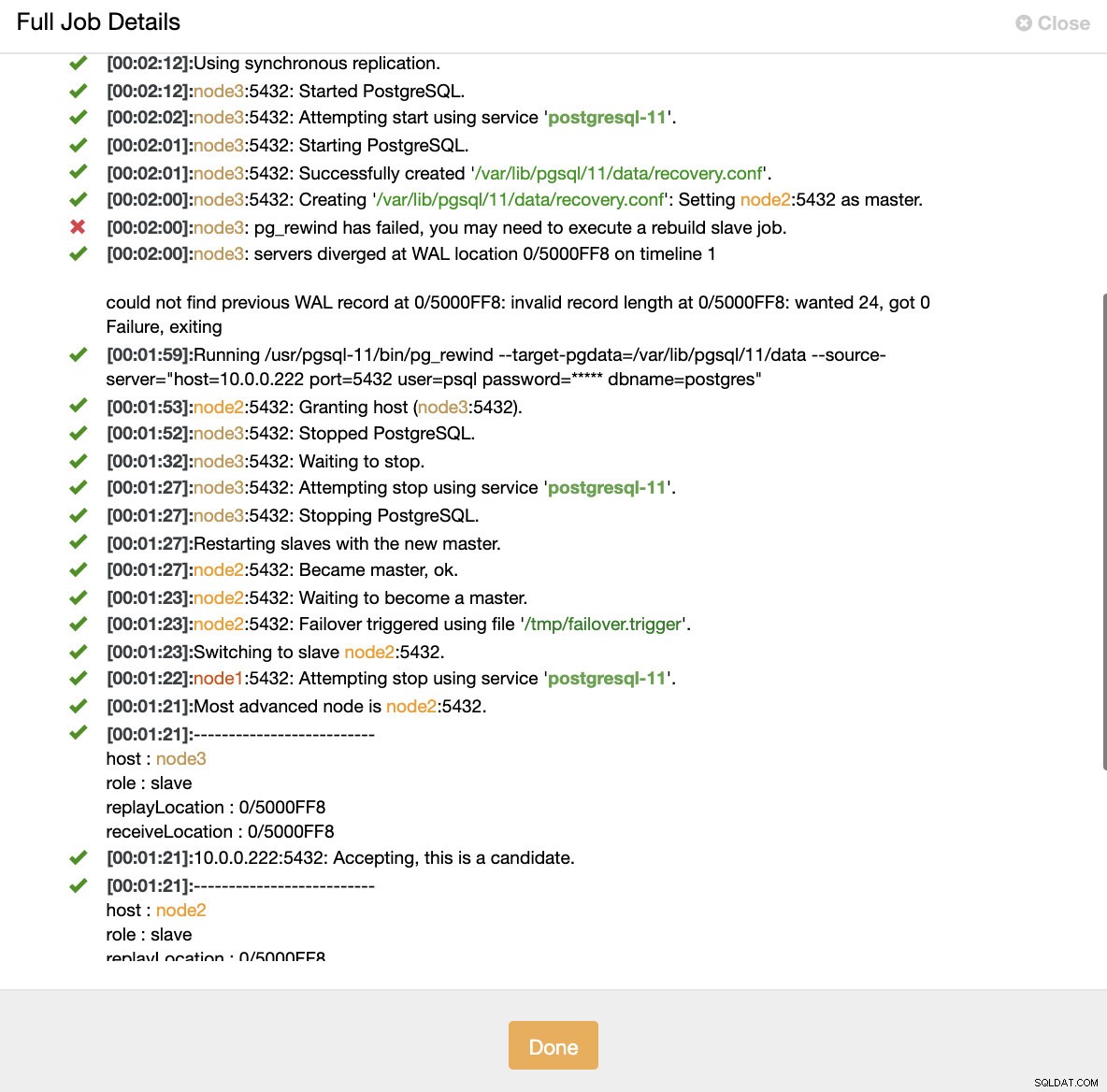 ClusterControl :tâche déclenchée pour reconstruire le cluster
ClusterControl :tâche déclenchée pour reconstruire le cluster ClusterControl maintient intentionnellement l'ancien serveur principal hors ligne car il peut arriver que certaines données n'aient pas été transférées vers les serveurs de secours. Dans ce cas, le serveur principal est le seul hôte contenant ces données et vous souhaiterez peut-être récupérer manuellement les données manquantes. Pour ceux qui souhaitent reconstruire automatiquement le primaire défaillant, il existe une option dans le fichier de configuration cmon :replication_auto_rebuild_slave. Par défaut, il est désactivé mais lorsque l'utilisateur l'active, le primaire défaillant sera reconstruit en tant qu'esclave du nouveau primaire. Bien sûr, s'il manque des données qui n'existent que sur le primaire défaillant, ces données seront perdues.
Reconstruction des serveurs de secours
La fonction différente est la tâche "Reconstruire l'esclave de réplication" qui est disponible pour tous les esclaves (ou serveurs de secours) dans la configuration de la réplication. Ceci doit être utilisé par exemple lorsque vous souhaitez effacer les données sur le standby et les reconstruire à nouveau avec une nouvelle copie des données du primaire. Cela peut être avantageux si un serveur de secours n'est pas en mesure de se connecter et de répliquer à partir du serveur principal pour une raison quelconque.
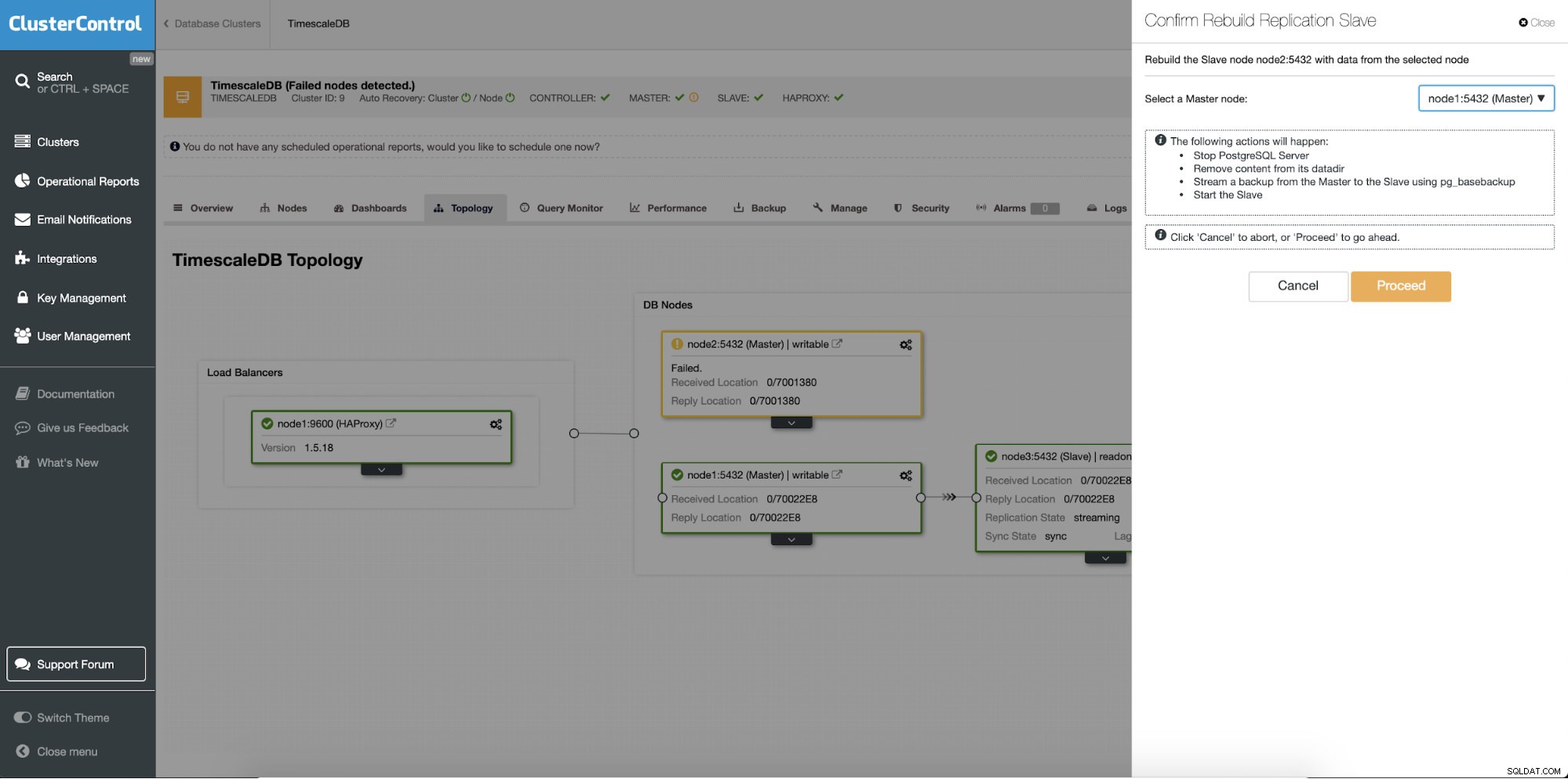 ClusterControl :reconstruire l'esclave de réplication
ClusterControl :reconstruire l'esclave de réplication 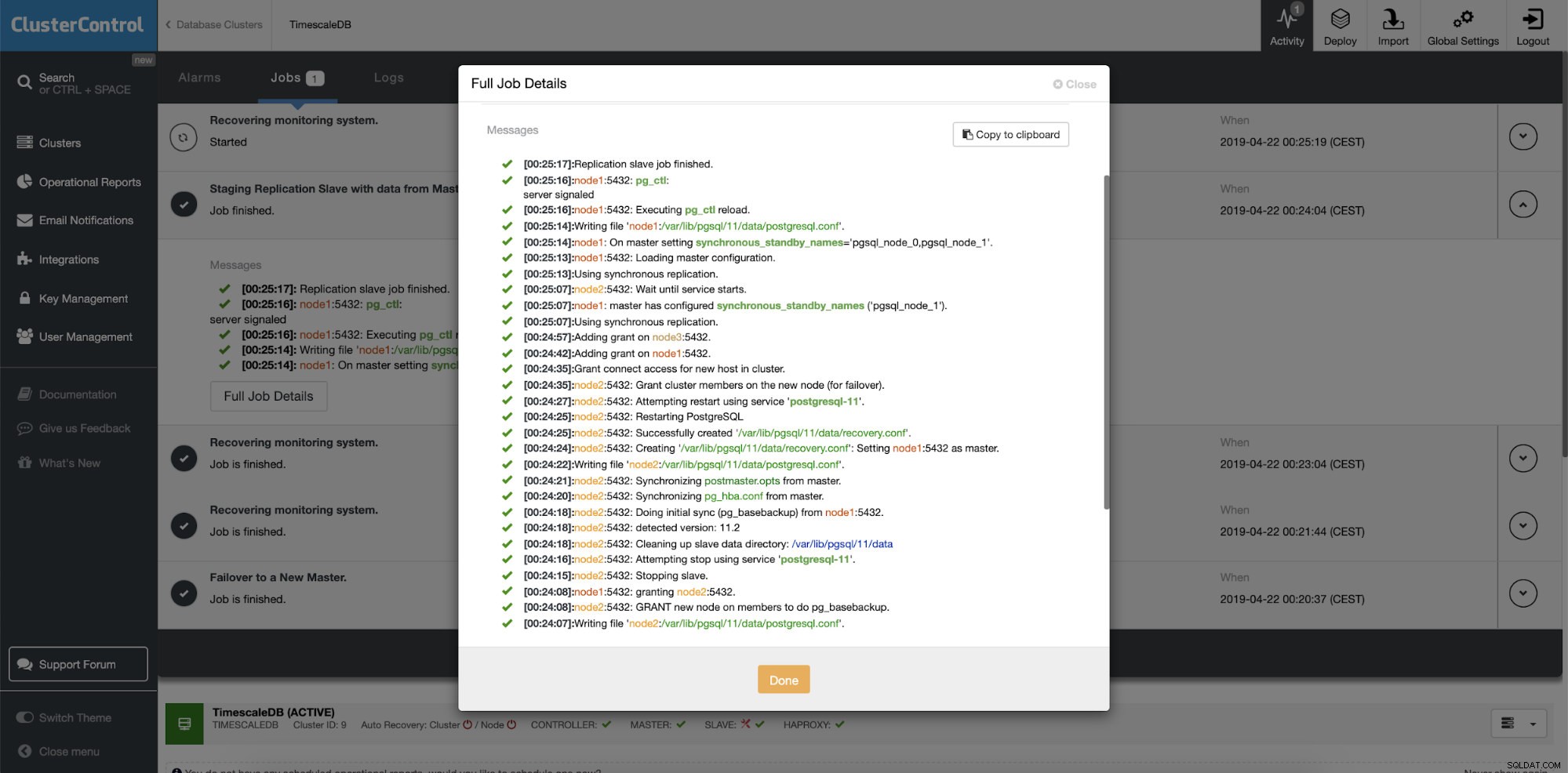 ClusterControl :reconstruire l'esclave
ClusterControl :reconstruire l'esclave