Remarque :Cet article a été initialement publié uniquement dans notre eBook, Techniques de haute performance pour SQL Server, Volume 4. Vous pouvez en savoir plus sur nos eBooks ici.
On me pose régulièrement la question :"Par où commencer lorsqu'il s'agit d'essayer de régler une instance SQL Server ?" Ma première réponse est de les interroger sur la configuration de leur instance. Si certaines choses ne sont pas configurées correctement, commencer immédiatement à examiner les requêtes longues ou coûteuses pourrait être un effort inutile.
J'ai blogué sur des choses courantes que les administrateurs manquent où je partage de nombreux paramètres que les administrateurs doivent modifier à partir d'une installation par défaut de SQL Server. Pour les éléments liés aux performances, je leur dis qu'ils doivent vérifier les éléments suivants :
- Paramètres de mémoire
- Mise à jour des statistiques
- Maintenance de l'index
- MAXDOP et seuil de coût pour le parallélisme
- bonnes pratiques tempdb
- Optimiser pour les charges de travail ad hoc
Une fois que j'ai dépassé les éléments de configuration, je demande s'ils ont examiné les statistiques de fichiers et d'attente ainsi que les requêtes coûteuses. La plupart du temps, la réponse est "non" - avec une explication indiquant qu'ils ne savent pas comment trouver cette information.
Généralement, le problème courant lorsque quelqu'un déclare qu'il doit régler un serveur SQL est qu'il fonctionne lentement. Que signifie lent ? Est-ce un certain rapport, une application spécifique ou tout ? Cela vient-il de se produire ou cela s'est-il aggravé avec le temps? Je commence par poser les questions de triage habituelles sur l'utilisation de la mémoire, du processeur et du disque par rapport à la situation normale, le problème vient-il de se produire et ce qui a changé récemment. À moins que le client ne capture une ligne de base, il n'a pas de mesures à comparer pour savoir si les statistiques actuelles sont anormales.
Presque tous les serveurs SQL sur lesquels je travaille hébergent plusieurs bases de données utilisateur. Lorsqu'un client signale que SQL Server est lent, la plupart du temps, il s'inquiète d'une application spécifique qui cause des problèmes à ses clients. Une réaction instinctive consiste à se concentrer immédiatement sur cette base de données particulière, mais souvent un autre processus peut consommer des ressources précieuses et la base de données de l'application est affectée. Par exemple, si vous disposez d'une grande base de données de rapports et que quelqu'un lance un rapport volumineux qui sature le disque, augmente le CPU et vide le cache du plan, vous pouvez parier que les autres bases de données utilisateur ralentiront pendant la génération de ce rapport.
J'aime toujours commencer par regarder les statistiques du fichier. Pour SQL Server 2005 et versions ultérieures, vous pouvez interroger la DMV sys.dm_io_virtual_file_stats pour obtenir des statistiques d'E/S pour chaque fichier de données et journal. Ce DMV a remplacé la fonction fn_virtualfilestats. Pour capturer les statistiques du fichier, j'aime utiliser un script que Paul Randal a mis en place :capturer les latences d'E/S pendant un certain temps. Ce script capturera une ligne de base et, 30 minutes plus tard (sauf si vous modifiez la durée dans la section WAITFOR DELAY), capturera les statistiques et calculera les deltas entre elles. Le script de Paul fait également un peu de calcul pour déterminer les latences de lecture et d'écriture, ce qui facilite grandement la lecture et la compréhension.
Sur mon ordinateur portable, j'ai restauré une copie de la base de données AdventureWorks2014 sur une clé USB afin d'avoir des vitesses de disque plus lentes. J'ai ensuite lancé un processus pour générer une charge contre lui. Vous pouvez voir les résultats ci-dessous où ma latence d'écriture pour mon fichier de données est de 240 ms et la latence d'écriture pour mon fichier journal est de 46 ms. Des latences aussi élevées sont gênantes.
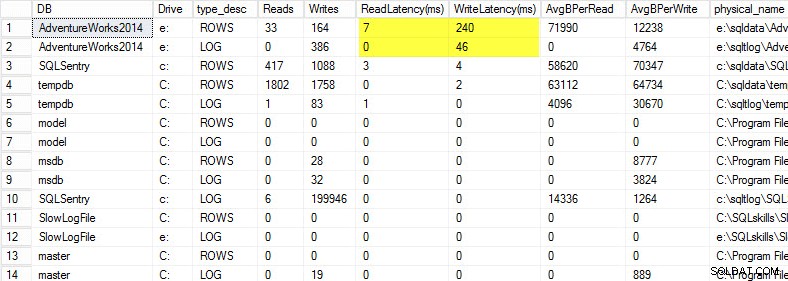
Tout ce qui dépasse 20 ms doit être considéré comme mauvais, comme je l'ai partagé dans un post précédent :surveillance de la latence de lecture/écriture. Ma latence de lecture est correcte, mais la base de données AdventureWorks2014 souffre d'écritures lentes. Dans ce cas, j'examinerais ce qui génère les écritures ainsi que les performances de mon sous-système d'E/S. S'il s'agissait de latences de lecture excessivement élevées, je commencerais à étudier les performances des requêtes (pourquoi fait-il autant de lectures, par exemple à partir d'index manquants), ainsi que les performances globales du sous-système d'E / S.
Il est important de connaître les performances globales de votre sous-système d'E/S, et la meilleure façon de savoir de quoi il est capable est de le comparer. Glenn Berry en parle dans son article analysant les performances d'E/S pour SQL Server. Glenn explique la latence, les IOPS et le débit et présente CrystalDiskMark, un outil gratuit que vous pouvez utiliser pour référencer votre stockage.
Après avoir découvert les performances des statistiques de fichiers, j'aime consulter les statistiques d'attente en utilisant le DMV sys.dm_os_wait_stats, qui renvoie des informations sur toutes les attentes qui se sont produites. Pour cela, je me tourne vers un autre script que Paul Randal fournit dans son article de blog sur la capture de statistiques d'attente pour une période de temps. Le script de Paul fait encore un peu de calcul pour nous mais, plus important encore, il exclut une grande partie des attentes bénignes dont nous ne nous soucions généralement pas. Ce script a également un WAITFOR DELAY et est défini sur 30 minutes. La lecture des statistiques d'attente peut être un peu plus délicate :vous pouvez avoir des attentes qui semblent élevées en fonction du pourcentage, mais l'attente moyenne est si faible qu'il n'y a pas lieu de s'inquiéter.
J'ai lancé le même processus de chargement et capturé mes statistiques d'attente, que j'ai montrées ci-dessous. Pour des explications sur bon nombre de ces types d'attente, vous pouvez lire un autre des articles de blog de Paul, des statistiques d'attente ou, s'il vous plaît, dites-moi où ça fait mal, ainsi que certains de ses articles sur ce blog.
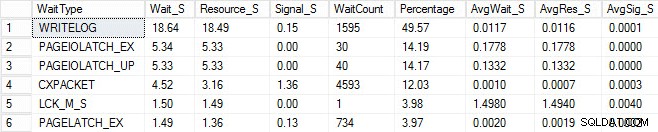
Dans cette sortie artificielle, les attentes PAGEIOLATCH pourraient indiquer un goulot d'étranglement avec mon sous-système d'E / S, mais pourraient également être un problème de mémoire, des analyses de table à la place ou une foule d'autres problèmes. Dans mon cas, nous savons qu'il s'agit d'un problème de disque, car je stocke la base de données sur une clé USB. Le temps d'attente LCK_M_S est très élevé, cependant il n'y a qu'une seule instance de l'attente. Mon WRITELOG est également plus élevé que je ne le souhaiterais, mais c'est compréhensible compte tenu des problèmes de latence avec la clé USB. Cela montre également les attentes de CXPACKET, et il serait facile d'avoir une réaction instinctive et de penser que vous avez un problème de parallélisme/MAXDOP, mais le compteur AvgWait_S est très bas. Soyez prudent lorsque vous utilisez des attentes pour le dépannage. Laissez-le être un guide pour vous dire les choses qui ne sont pas le problème ainsi que vous donner une direction où chercher les problèmes. Un dépannage approprié consiste à corréler les comportements de plusieurs domaines pour réduire le problème.
Après avoir examiné le fichier et les statistiques d'attente, je commence à creuser dans les requêtes à coût élevé en fonction des problèmes que j'ai trouvés. Pour cela, je me tourne vers les requêtes d'informations de diagnostic de Glenn Berry. Ces ensembles de requêtes sont les scripts de référence que de nombreux consultants utilisent. Glenn et la communauté fournissent constamment des mises à jour pour les rendre aussi informatives et robustes que possible. L'une de mes requêtes préférées est le top des requêtes mises en cache par nombre d'exécutions. J'aime trouver des requêtes ou des procédures stockées qui ont un nombre élevé d'exécutions associées à un nombre élevé de lectures_logiques. Si ces requêtes ont des opportunités de réglage, vous pouvez rapidement faire une grande différence pour le serveur. Les scripts incluent également les meilleurs SP mis en cache par nombre total de lectures logiques et les meilleurs SP mis en cache par nombre total de lectures physiques. Les deux sont bons pour rechercher des lectures élevées avec un nombre d'exécutions élevé afin que vous puissiez réduire le nombre d'E/S.
En plus des scripts de Glenn, j'aime utiliser sp_whoisactive d'Adam Machanic pour voir ce qui est en cours d'exécution.
Le réglage des performances ne se limite pas à regarder les statistiques de fichiers et d'attente et les requêtes coûteuses, mais c'est par là que j'aime commencer. C'est un moyen de trier rapidement un environnement pour commencer à déterminer la cause du problème. Il n'y a pas de moyen totalement infaillible de régler :ce dont chaque DBA de production a besoin, c'est d'une liste de contrôle des éléments à éliminer et d'une très bonne collection de scripts à exécuter pour analyser la santé du système. Avoir une ligne de base est essentiel pour exclure rapidement un comportement normal ou anormal. Ma bonne amie Erin Stellato a un cours complet sur Pluralsight appelé SQL Server :Benchmarking and Baselining si vous avez besoin d'aide pour configurer et capturer votre ligne de base.
Mieux encore, obtenez un outil de pointe comme SQL Sentry Performance Advisor qui non seulement collectera et stockera des informations historiques pour le profilage et les tendances, et donnera un accès facile à tous les détails mentionnés ci-dessus et plus encore, mais il donne également la possibilité de comparer l'activité aux lignes de base intégrées ou définies par l'utilisateur, de maintenir efficacement les index sans lever le petit doigt et d'alerter ou d'automatiser les réponses basées sur une architecture de conditions personnalisées très robuste. La capture d'écran suivante illustre la vue historique du tableau de bord Performance Advisor, avec les attentes de disque en orange, les E/S de base de données en bas à droite et les lignes de base comparant la période actuelle et précédente sur chaque graphique (cliquez pour agrandir) :
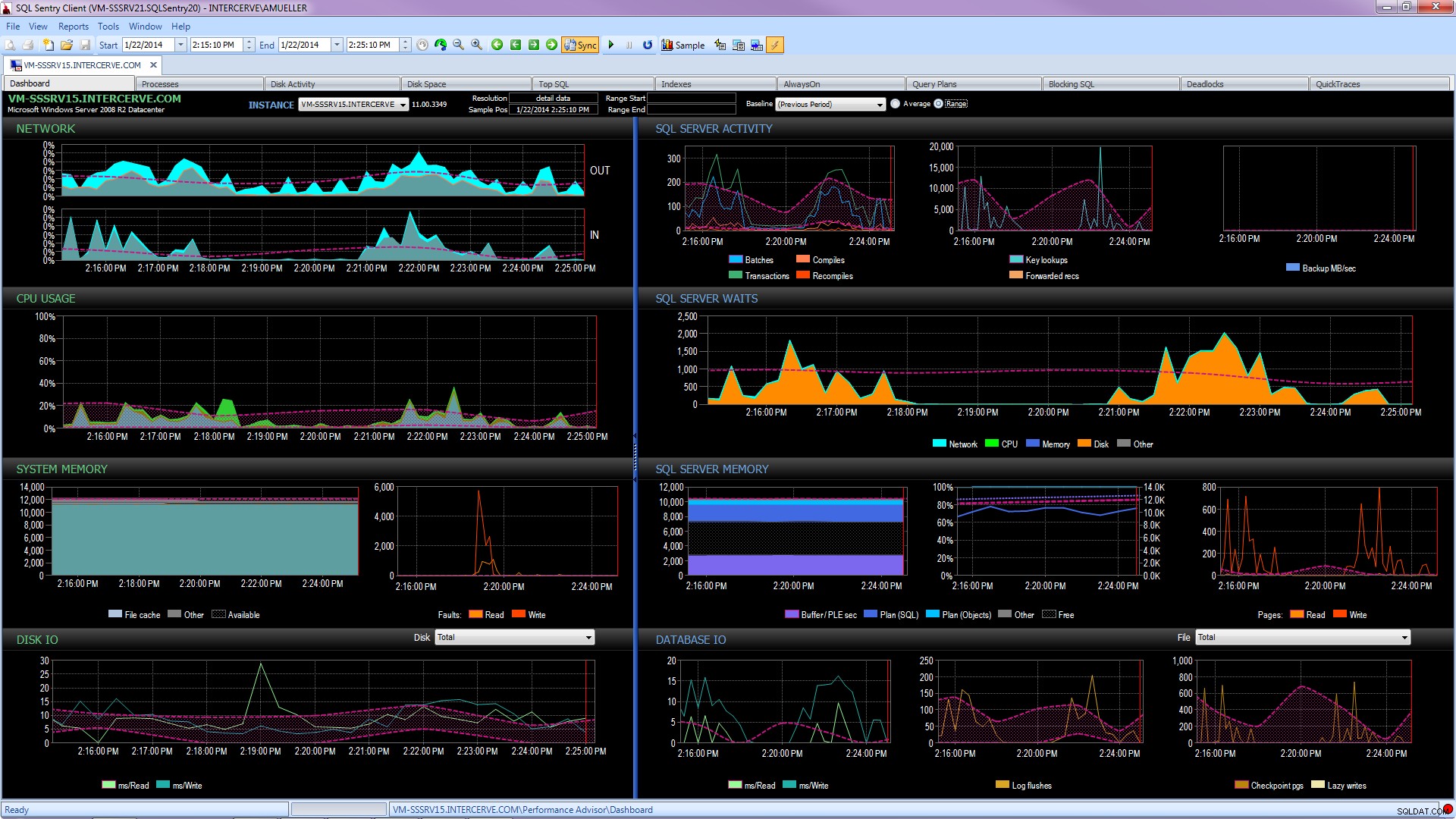
Les outils de surveillance de qualité ne sont pas gratuits, mais ils fournissent une tonne de fonctionnalités et de support qui vous permettent de vous concentrer sur les problèmes de performances de vos serveurs, au lieu de vous concentrer sur les requêtes, les travaux et les alertes qui peuvent vous permettent de vous concentrer sur vos problèmes de performances, mais seulement une fois que vous les avez résolus. Il est souvent très utile de ne pas réinventer la roue.