Le moyen le plus rapide de calculer une médiane utilise le SQL Server 2012 OFFSET extension au ORDER BY clause. En seconde position, la solution la plus rapide suivante utilise un curseur dynamique (éventuellement imbriqué) qui fonctionne sur toutes les versions. Cet article examine un ROW_NUMBER pré-2012 courant solution au problème de calcul médian pour voir pourquoi il fonctionne moins bien et ce qui peut être fait pour le faire aller plus vite.
Test médian unique
L'exemple de données pour ce test consiste en une seule table de dix millions de lignes (reproduite à partir de l'article original d'Aaron Bertrand) :
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); La solution OFFSET
Pour définir la référence, voici la solution SQL Server 2012 (ou version ultérieure) OFFSET créée par Peter Larsson :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); La requête pour compter les lignes de la table est commentée et remplacée par une valeur codée en dur afin de se concentrer sur les performances du code principal. Avec un cache à chaud et une collecte de plans d'exécution désactivés, cette requête s'exécute pendant 910 ms en moyenne sur ma machine de test. Le plan d'exécution est présenté ci-dessous :

En passant, il est intéressant de noter que cette requête modérément complexe se qualifie pour un plan trivial :
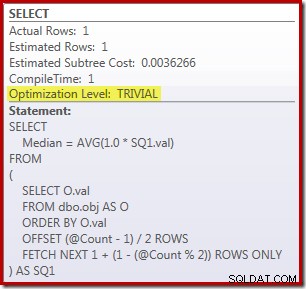
La solution ROW_NUMBER
Pour les systèmes exécutant SQL Server 2008 R2 ou une version antérieure, la solution alternative la plus performante utilise un curseur dynamique, comme mentionné précédemment. Si vous ne pouvez pas (ou ne voulez pas) considérer cela comme une option, il est naturel de penser à émuler le 2012 OFFSET plan d'exécution utilisant ROW_NUMBER .
L'idée de base est de numéroter les lignes dans l'ordre approprié, puis de filtrer uniquement la ou les deux lignes nécessaires pour calculer la médiane. Il existe plusieurs façons d'écrire ceci dans Transact SQL; une version compacte qui capture tous les éléments clés est la suivante :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
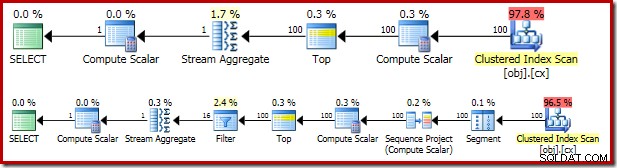
Le plan d'exécution résultant est assez similaire au OFFSET version :

Il vaut la peine d'examiner tour à tour chacun des opérateurs du plan pour bien les comprendre :
- L'opérateur de segment est redondant dans ce plan. Il serait nécessaire si le
ROW_NUMBERla fonction de classement avait unePARTITION BYclause, mais ce n'est pas le cas. Même ainsi, cela reste dans le plan final. - Le projet de séquence ajoute un numéro de ligne calculé au flux de lignes.
- Le Compute Scalar définit une expression associée à la nécessité de convertir implicitement le
valcolonne en numérique afin qu'elle puisse être multipliée par la constante littérale1.0dans la requête. Ce calcul est différé jusqu'à ce qu'il soit requis par un opérateur ultérieur (qui se trouve être le Stream Aggregate). Cette optimisation de l'exécution signifie que la conversion implicite n'est effectuée que pour les deux lignes traitées par le Stream Aggregate, et non pour les 5 000 001 lignes indiquées pour le Compute Scalar. - L'opérateur Top est introduit par l'optimiseur de requête. Il reconnaît qu'au plus, seul le premier
(@Count + 2) / 2lignes sont nécessaires à la requête. On aurait pu ajouter unTOP ... ORDER BYdans la sous-requête pour rendre cela explicite, mais cette optimisation rend cela largement inutile. - Le filtre implémente la condition dans
WHEREclause, filtrant toutes les lignes sauf les deux « intermédiaires » nécessaires pour calculer la médiane (le Top introduit est également basé sur cette condition). - Le Stream Aggregate calcule le
SUMetCOUNTdes deux rangées médianes. - Le scalaire de calcul final calcule la moyenne à partir de la somme et du nombre.
Performances brutes
Par rapport au OFFSET plan, nous pourrions nous attendre à ce que les opérateurs Segment, Sequence Project et Filter supplémentaires aient un effet négatif sur les performances. Cela vaut la peine de prendre un moment pour comparer les estimations coûts des deux plans :
Le OFFSET le plan a un coût estimé à 0,0036266 unités, tandis que le ROW_NUMBER le forfait est estimé à 0,0036744 unités. Ce sont de très petits nombres et il y a peu de différence entre les deux.
Il est donc peut-être surprenant que le ROW_NUMBER la requête s'exécute en fait pendant 4 000 ms en moyenne, contre 910 ms moyenne pour le OFFSET Solution. Une partie de cette augmentation peut sûrement s'expliquer par les frais généraux des opérateurs du plan supplémentaire, mais un facteur de quatre semble excessif. Il doit y avoir plus.
Vous avez probablement également remarqué que les estimations de cardinalité pour les deux plans estimés ci-dessus sont assez désespérément fausses. Cela est dû à l'effet des opérateurs Top, qui ont une expression faisant référence à une variable comme limite de nombre de lignes. L'optimiseur de requête ne peut pas voir le contenu des variables au moment de la compilation, il a donc recours à son estimation par défaut de 100 lignes. Les deux plans rencontrent en fait 5 000 001 lignes lors de l'exécution.
Tout cela est très intéressant, mais cela n'explique pas directement pourquoi le ROW_NUMBER la requête est plus de quatre fois plus lente que le OFFSET version. Après tout, l'estimation de la cardinalité sur 100 lignes est tout aussi erronée dans les deux cas.
Amélioration des performances de la solution ROW_NUMBER
Dans mon article précédent, nous avons vu comment la performance de la médiane groupée OFFSET le test pourrait être presque doublé en ajoutant simplement un PAGLOCK indice. Cet indice remplace la décision normale du moteur de stockage d'acquérir et de libérer des verrous partagés au niveau de la granularité des lignes (en raison de la faible cardinalité attendue).
Pour rappel, le PAGLOCK l'indice n'était pas nécessaire dans la médiane unique OFFSET test en raison d'une optimisation interne distincte qui peut ignorer les verrous partagés au niveau de la ligne, ce qui entraîne la prise d'un petit nombre de verrous partagés d'intention au niveau de la page.
Nous pourrions nous attendre à ce que le ROW_NUMBER solution médiane unique pour bénéficier de la même optimisation interne, mais ce n'est pas le cas. Surveillance de l'activité de verrouillage pendant le ROW_NUMBER requête s'exécute, nous voyons plus d'un demi-million de verrous partagés individuels au niveau de la ligne être pris et relâché.
Donc, maintenant que nous savons quel est le problème, nous pouvons améliorer les performances de verrouillage de la même manière que nous l'avons fait précédemment :soit avec un PAGLOCK verrouiller l'indice de granularité, ou en augmentant l'estimation de cardinalité à l'aide de l'indicateur de trace documenté 4138.
La désactivation du "row goal" à l'aide de l'indicateur de trace est la solution la moins satisfaisante pour plusieurs raisons. Premièrement, il n'est efficace que dans SQL Server 2008 R2 ou version ultérieure. Nous préférerions probablement le OFFSET solution dans SQL Server 2012, ce qui limite efficacement le correctif de l'indicateur de trace à SQL Server 2008 R2 uniquement. Deuxièmement, l'application de l'indicateur de trace nécessite des autorisations de niveau administrateur, sauf si elle est appliquée via un guide de plan. Une troisième raison est que la désactivation des objectifs de ligne pour l'ensemble de la requête peut avoir d'autres effets indésirables, en particulier dans les plans plus complexes.
En revanche, le PAGLOCK astuce est efficace, disponible dans toutes les versions de SQL Server sans aucune autorisation spéciale et n'a pas d'effets secondaires majeurs au-delà du verrouillage de la granularité.
Application du PAGLOCK allusion au ROW_NUMBER la requête augmente considérablement les performances :à partir de 4 000 ms à 1 500 ms :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Les 1 500 ms le résultat est toujours nettement plus lent que les 910 ms pour le OFFSET solution, mais au moins c'est maintenant dans le même stade. Le différentiel de performances restant est simplement dû au travail supplémentaire dans le plan d'exécution :

Dans le OFFSET plan, cinq millions de lignes sont traitées jusqu'au sommet (avec les expressions définies au Compute Scalar différées comme indiqué précédemment). Dans le ROW_NUMBER plan, le même nombre de lignes doit être traité par le segment, le projet de séquence, le haut et le filtre.