La stratégie générale utilisée par le moteur de base de données SQL Server pour maintenir une vue indexée synchronisée avec ses tables de base - que j'ai décrite plus en détail dans mon dernier article - consiste à effectuer une maintenance incrémentielle de la vue chaque fois qu'une opération de modification de données se produit sur l'une des tables référencées dans la vue. En gros, l'idée est de :
- Collecter des informations sur les modifications de la table de base
- Appliquez les projections, les filtres et les jointures définis dans la vue
- Agrégez les modifications par clé groupée de vue indexée
- Décidez si chaque modification doit entraîner une insertion, une mise à jour ou une suppression par rapport à la vue
- Calculer les valeurs à modifier, ajouter ou supprimer dans la vue
- Appliquer les modifications d'affichage
Ou, encore plus succinctement (mais au risque d'une grossière simplification) :
- Calculer les effets de vue incrémentiels des modifications de données d'origine ;
- Appliquer ces modifications à la vue
Il s'agit généralement d'une stratégie beaucoup plus efficace que de reconstruire la vue entière après chaque modification de données sous-jacente (l'option sûre mais lente), mais elle repose sur la logique de mise à jour incrémentielle correcte pour chaque modification de données imaginable, par rapport à chaque définition de vue indexée possible.
Comme le titre l'indique, cet article traite d'un cas intéressant où la logique de mise à jour incrémentielle tombe en panne, ce qui entraîne une vue indexée corrompue qui ne correspond plus aux données sous-jacentes. Avant d'aborder le bogue lui-même, nous devons examiner rapidement les agrégats scalaires et vectoriels.
Agrégats scalaires et vectoriels
Au cas où vous ne seriez pas familier avec le terme, il existe deux types d'agrégats. Un agrégat associé à une clause GROUP BY (même si la liste group by est vide) est appelé agrégat vectoriel . Un agrégat sans clause GROUP BY est appelé agrégat scalaire .
Alors qu'un agrégat vectoriel est garanti pour produire une seule ligne de sortie pour chaque groupe présent dans l'ensemble de données, les agrégats scalaires sont un peu différents. Agrégats scalaires toujours produire une seule ligne de sortie, même si le jeu d'entrée est vide.
Exemple d'agrégat vectoriel
L'exemple AdventureWorks suivant calcule deux agrégats vectoriels (une somme et un compte) sur un ensemble d'entrées vide :
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Ces requêtes produisent le résultat suivant (aucune ligne) :

Le résultat est le même si nous remplaçons la clause GROUP BY par un ensemble vide (nécessite SQL Server 2008 ou version ultérieure) :
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Les plans d'exécution sont également identiques dans les deux cas. Voici le plan d'exécution de la requête de comptage :
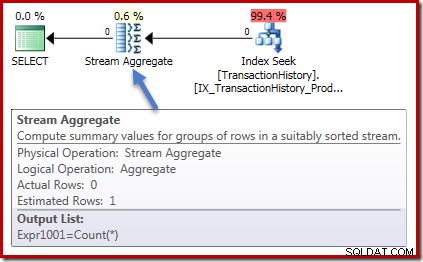
Aucune entrée de lignes dans le Stream Aggregate et aucune ligne en sortie. Le plan d'exécution de la somme ressemble à ceci :

Encore une fois, zéro ligne dans l'agrégat et zéro ligne en sortie. Toutes les bonnes choses simples jusqu'à présent.
Agrégats scalaires
Maintenant, regardez ce qui se passe si nous supprimons complètement la clause GROUP BY des requêtes :
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Au lieu d'un résultat vide, l'agrégat COUNT produit un zéro et SUM renvoie un NULL :
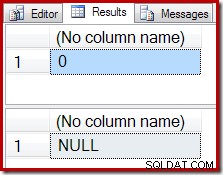
Le plan d'exécution du comptage confirme que zéro ligne d'entrée produit une seule ligne de sortie à partir du Stream Aggregate :
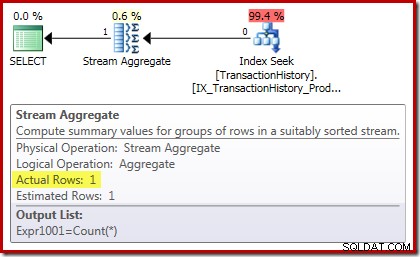
Le plan d'exécution somme est encore plus intéressant :
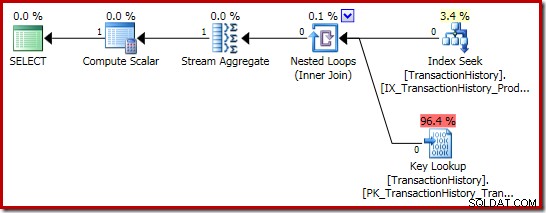
Les propriétés Stream Aggregate affichent un agrégat de comptage en cours de calcul en plus de la somme que nous avons demandée :
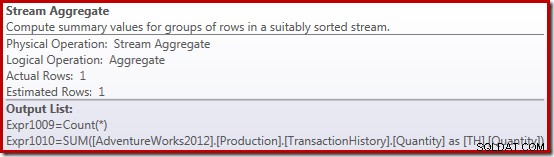
Le nouvel opérateur Compute Scalar permet de renvoyer NULL si le nombre de lignes reçues par le Stream Aggregate est nul, sinon il renvoie la somme des données rencontrées :
Tout cela peut sembler un peu étrange, mais voici comment cela fonctionne :
- Un agrégat vectoriel de zéro ligne renvoie zéro ligne ;
- Un agrégat scalaire produit toujours exactement une ligne de sortie, même pour une entrée vide ;
- Le nombre scalaire de zéro lignes est zéro ; et
- La somme scalaire de zéro lignes est NULL (pas zéro).
Le point important pour nos objectifs actuels est que les agrégats scalaires produisent toujours une seule ligne de sortie, même si cela signifie en créer une à partir de rien. De plus, la somme scalaire de zéro lignes est NULL, pas zéro.
Ces comportements sont tous "corrects" d'ailleurs. Les choses sont comme elles sont parce que le standard SQL n'a pas défini à l'origine le comportement des agrégats scalaires, le laissant à l'implémentation. SQL Server conserve son implémentation d'origine pour des raisons de compatibilité descendante. Les agrégats de vecteurs ont toujours eu des comportements bien définis.
Vues indexées et agrégation vectorielle
Considérons maintenant une vue indexée simple incorporant quelques agrégats (vectoriels) :
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Les requêtes suivantes affichent le contenu de la table de base, le résultat de l'interrogation de la vue indexée et le résultat de l'exécution de la requête de vue sur la table sous-jacente à la vue :
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Les résultats sont :
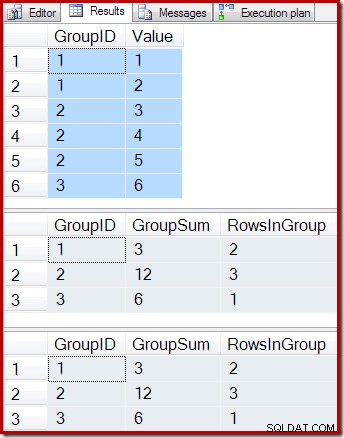
Comme prévu, la vue indexée et la requête sous-jacente renvoient exactement les mêmes résultats. Les résultats resteront synchronisés après toutes les modifications possibles de la table de base T1. Pour nous rappeler comment tout cela fonctionne, considérons le cas simple de l'ajout d'une seule nouvelle ligne à la table de base :
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Le plan d'exécution de cet insert contient toute la logique nécessaire pour maintenir la vue indexée synchronisée :
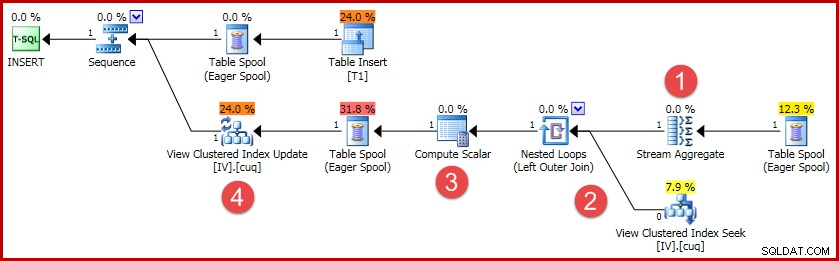
Les principales activités du plan sont :
- Le Stream Aggregate calcule les changements par clé de vue indexée
- La jointure externe à la vue relie le résumé des modifications à la ligne de la vue cible, le cas échéant
- Le scalaire de calcul décide si chaque modification nécessite une insertion, une mise à jour ou une suppression par rapport à la vue, et calcule les valeurs nécessaires.
- L'opérateur de mise à jour de la vue effectue physiquement chaque modification de l'index clusterisé de la vue.
Il existe des différences de plan pour différentes opérations de modification par rapport à la table de base (par exemple, les mises à jour et les suppressions), mais l'idée générale derrière la synchronisation de la vue reste la même :regrouper les modifications par clé de vue, rechercher la ligne de vue si elle existe, puis effectuer une combinaison d'opérations d'insertion, de mise à jour et de suppression sur l'index de vue si nécessaire.
Quelles que soient les modifications que vous apportez à la table de base dans cet exemple, la vue indexée restera correctement synchronisée - les requêtes NOEXPAND et EXPAND VIEWS ci-dessus renverront toujours le même jeu de résultats. C'est ainsi que les choses devraient toujours fonctionner.
Vues indexées et agrégation scalaire
Essayez maintenant cet exemple, où la vue indexée utilise l'agrégation scalaire (pas de clause GROUP BY dans la vue) :
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Il s'agit d'une vue indexée parfaitement légale; aucune erreur n'est rencontrée lors de sa création. Il y a un indice que nous pourrions faire quelque chose d'un peu étrange, cependant :quand vient le temps de matérialiser la vue en créant l'index cluster unique requis, il n'y a pas de colonne évidente à choisir comme clé. Normalement, nous choisirions les colonnes de regroupement à partir de la clause GROUP BY de la vue, bien sûr.
Le script ci-dessus choisit arbitrairement la colonne NumRows. Ce choix n'est pas important. N'hésitez pas à créer l'index clusterisé unique comme vous le souhaitez. La vue contiendra toujours exactement une ligne à cause des agrégats scalaires, il n'y a donc aucune chance de violation de clé unique. En ce sens, le choix de la clé d'index de vue est redondant, mais néanmoins nécessaire.
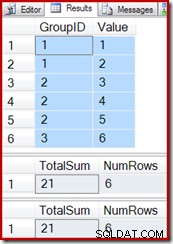
En réutilisant les requêtes de test de l'exemple précédent, on constate que la vue indexée fonctionne correctement :
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
L'insertion d'une nouvelle ligne dans la table de base (comme nous l'avons fait avec la vue indexée vectorielle agrégée) continue également de fonctionner correctement :
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Le plan d'exécution est similaire, mais pas tout à fait identique :
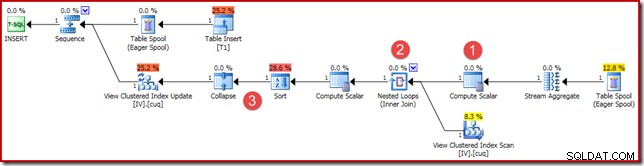
Les principales différences sont :
- Ce nouveau Compute Scalar est là pour les mêmes raisons que lorsque nous avons comparé les résultats d'agrégation vectoriels et scalaires plus tôt :il garantit qu'une somme NULL est renvoyée (au lieu de zéro) si l'agrégat fonctionne sur un ensemble vide. Il s'agit du comportement requis pour une somme scalaire sans ligne.
- La jointure externe vue précédemment a été remplacée par une jointure interne. Il y aura toujours exactement une ligne dans la vue indexée (en raison de l'agrégation scalaire), il n'est donc pas question d'avoir besoin d'une jointure externe pour tester si une ligne de vue correspond ou non. La seule ligne présente dans la vue représente toujours l'ensemble complet de données. Cette jointure interne n'a pas de prédicat, il s'agit donc techniquement d'une jointure croisée (vers une table avec une seule ligne garantie).
- Les opérateurs Trier et Réduire sont présents pour des raisons techniques abordées dans mon précédent article sur la maintenance des vues indexées. Ils n'affectent pas le bon fonctionnement de la maintenance des vues indexées ici.
En fait, de nombreux types différents d'opérations de modification de données peuvent être exécutés avec succès sur la table de base T1 dans cet exemple ; les effets seront correctement reflétés dans la vue indexée. Les opérations de modification suivantes sur la table de base peuvent toutes être effectuées tout en conservant la vue indexée correcte :
- Supprimer les lignes existantes
- Mettre à jour les lignes existantes
- Insérer de nouvelles lignes
Cela peut sembler être une liste exhaustive, mais ce n'est pas le cas.
Le bogue révélé
Le problème est plutôt subtil et concerne (comme vous devriez vous y attendre) les différents comportements des agrégats vectoriels et scalaires. Les points clés sont qu'un agrégat scalaire produira toujours une ligne de sortie, même s'il ne reçoit aucune ligne sur son entrée, et la somme scalaire d'un ensemble vide est NULL, pas zéro.
Pour causer un problème, il suffit d'insérer ou de supprimer aucune ligne dans la table de base.
Cette déclaration n'est pas aussi folle qu'elle pourrait sembler à première vue.
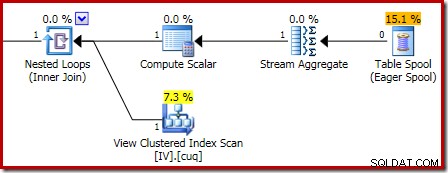
Le fait est qu'une requête d'insertion ou de suppression qui n'affecte aucune ligne de la table de base mettra toujours à jour la vue, car le Stream Aggregate scalaire dans la partie de maintenance de la vue indexée du plan de requête produira une ligne de sortie même lorsqu'il est présenté sans entrée. Le Compute Scalar qui suit le Stream Aggregate générera également une somme NULL lorsque le nombre de lignes est égal à zéro.
Le script suivant illustre le bogue en action :
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
La sortie de ce script est illustrée ci-dessous :
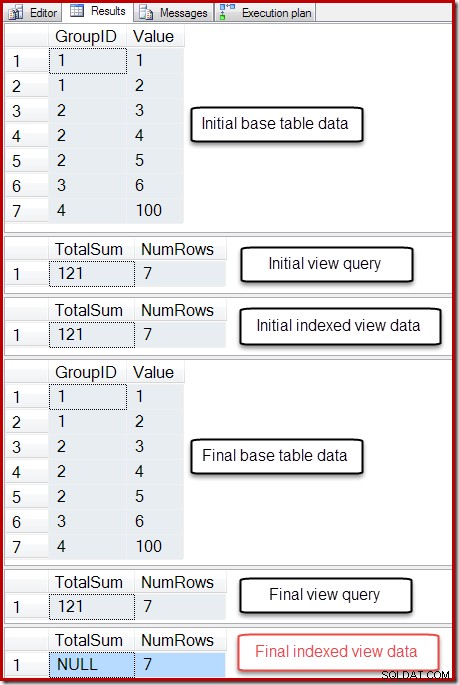
L'état final de la colonne Somme totale de la vue indexée ne correspond pas à la requête de vue sous-jacente ou aux données de la table de base. La somme NULL a corrompu la vue, ce qui peut être confirmé en exécutant DBCC CHECKTABLE (sur la vue indexée).
Le plan d'exécution responsable de la corruption est présenté ci-dessous :
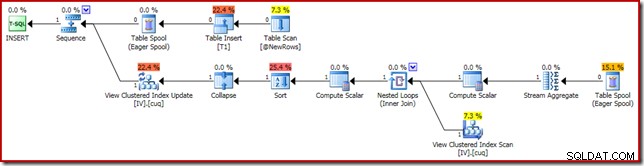
Un zoom avant affiche l'entrée de zéro ligne dans le Stream Aggregate et la sortie d'une ligne :
Si vous voulez essayer le script de corruption ci-dessus avec une suppression au lieu d'une insertion, voici un exemple :
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
La suppression n'affecte aucune ligne de la table de base, mais change toujours la colonne de somme de la vue indexée en NULL.
Généraliser le bogue
Vous pouvez probablement créer n'importe quel nombre de requêtes d'insertion et de suppression de table de base qui n'affectent aucune ligne et provoquent la corruption de cette vue indexée. Cependant, le même problème de base s'applique à une classe de problèmes plus large que les simples insertions et suppressions qui n'affectent aucune ligne de table de base.
Il est possible, par exemple, de produire la même corruption en utilisant un insert qui fait ajouter des lignes à la table de base. L'ingrédient essentiel est qu'aucune ligne ajoutée ne doit se qualifier pour la vue . Cela se traduira par une entrée vide dans le Stream Aggregate et la sortie de ligne NULL causant la corruption du scalaire de calcul suivant.
Une façon d'y parvenir est d'inclure une clause WHERE dans la vue qui rejette certaines des lignes de la table de base :
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Compte tenu de la nouvelle restriction sur les ID de groupe inclus dans la vue, l'insertion suivante ajoutera des lignes à la table de base, mais corrompra toujours la vue indexée avec une somme NULL :
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; La sortie montre la corruption d'index désormais familière :
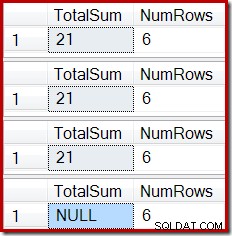
Un effet similaire peut être produit à l'aide d'une vue qui contient une ou plusieurs jointures internes. Tant que les lignes ajoutées à la table de base sont rejetées (par exemple en échouant à se joindre), le Stream Aggregate ne recevra aucune ligne, le Compute Scalar générera une somme NULL et la vue indexée sera probablement corrompue.
Réflexions finales
Ce problème ne se produit pas pour les requêtes de mise à jour (du moins pour autant que je sache), mais cela semble être plus un accident que la conception - le Stream Aggregate problématique est toujours présent dans les plans de mise à jour potentiellement vulnérables, mais le Compute Scalar qui génère la somme NULL n'est pas ajoutée (ou peut-être optimisée). Veuillez me faire savoir si vous parvenez à reproduire le bogue en utilisant une requête de mise à jour.
Jusqu'à ce que ce bogue soit corrigé (ou, peut-être, que les agrégats scalaires soient interdits dans les vues indexées), soyez très prudent lorsque vous utilisez des agrégats dans une vue indexée sans clause GROUP BY.
Cet article a été inspiré par un élément Connect soumis par Vladimir Moldovanenko, qui a eu la gentillesse de laisser un commentaire sur un ancien article de mon blog (qui concerne une autre corruption de vue indexée causée par l'instruction MERGE). Vladimir utilisait des agrégats scalaires dans une vue indexée pour des raisons valables, alors ne soyez pas trop rapide pour juger ce bogue comme un cas limite que vous ne rencontrerez jamais dans un environnement de production ! Mes remerciements à Vladimir pour m'avoir alerté sur son article Connect.