Dans mon dernier message, j'ai commencé une série pour couvrir les vérifications de santé proactives qui sont vitales pour votre serveur SQL. Nous avons commencé avec l'espace disque, et dans cet article, nous discuterons des tâches de maintenance. L'une des responsabilités fondamentales d'un administrateur de base de données est de s'assurer que les tâches de maintenance suivantes s'exécutent régulièrement :
- Sauvegardes
- Contrôles d'intégrité
- Maintenance de l'index
- Mises à jour des statistiques
Je parie que vous avez déjà des emplois en place pour gérer ces tâches. Et je parierais également que vous avez des notifications configurées pour vous envoyer un e-mail à vous et à votre équipe si un travail échoue. Si les deux sont vrais, alors vous êtes déjà proactif en matière de maintenance. Et si vous ne faites pas les deux, c'est quelque chose à corriger maintenant - comme dans, arrêtez de lire ceci, téléchargez les scripts d'Ola Hallengren, planifiez-les et assurez-vous de configurer les notifications. (Une autre alternative spécifique à la maintenance des index, que nous recommandons également aux clients, est SQL Sentry Fragmentation Manager.)
Si vous ne savez pas si vos tâches sont configurées pour vous envoyer un e-mail en cas d'échec, utilisez cette requête :
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Cependant, être proactif en matière de maintenance va encore plus loin. Au-delà de la simple vérification de l'exécution de vos tâches, vous devez savoir combien de temps elles prennent. Vous pouvez utiliser les tables système dans msdb pour surveiller ceci :
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Ou, si vous utilisez les scripts et les informations de journalisation d'Ola, vous pouvez interroger sa table CommandLog :
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Le script ci-dessus répertorie la durée de sauvegarde pour chaque sauvegarde complète de la base de données AdventureWorks2014. Vous pouvez vous attendre à ce que les durées des tâches de maintenance augmentent lentement au fil du temps, à mesure que les bases de données grossissent. En tant que tel, vous recherchez des augmentations importantes ou des diminutions inattendues de la durée. Par exemple, j'avais un client avec une durée de sauvegarde moyenne inférieure à 30 minutes. Tout à coup, les sauvegardes commencent à prendre plus d'une heure. La taille de la base de données n'avait pas changé de manière significative, aucun paramètre n'avait changé pour l'instance ou la base de données, rien n'avait changé avec la configuration du matériel ou du disque. Quelques semaines plus tard, la durée de la sauvegarde est redescendue à moins d'une demi-heure. Un mois plus tard, ils sont remontés. Nous avons finalement corrélé la modification de la durée de sauvegarde aux basculements entre les nœuds de cluster. Sur un nœud, les sauvegardes ont pris moins d'une demi-heure. De l'autre, ils ont pris plus d'une heure. Une petite enquête sur la configuration des NIC et de la structure SAN et nous avons pu identifier le problème.
Comprendre le temps moyen d'exécution des opérations CHECKDB est également important. C'est quelque chose dont Paul parle dans notre événement d'immersion sur la haute disponibilité et la reprise après sinistre :vous devez savoir combien de temps CHECKDB prend normalement pour s'exécuter, de sorte que si vous trouvez une corruption et que vous exécutez une vérification sur l'ensemble de la base de données, vous savez combien de temps il faut prendre pour que CHECKDB se termine. Lorsque votre patron vous demande :"Combien de temps avant de connaître l'étendue du problème ?" vous serez en mesure de fournir une réponse quantitative sur le temps minimum que vous devrez attendre. Si CHECKDB prend plus de temps que d'habitude, alors vous savez qu'il a trouvé quelque chose (ce qui n'est pas nécessairement une corruption ; vous devez toujours laisser la vérification se terminer).
Maintenant, si vous gérez des centaines de bases de données, vous ne voulez pas exécuter la requête ci-dessus pour chaque base de données ou chaque tâche. Au lieu de cela, vous souhaiterez peut-être simplement rechercher des emplois qui se situent en dehors de la durée moyenne d'un certain pourcentage, ce que vous pouvez obtenir à l'aide de cette requête :
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Cette requête répertorie les travaux qui ont pris 25 % de plus que la moyenne. La requête nécessitera quelques ajustements pour fournir les informations spécifiques que vous souhaitez - certaines tâches d'une courte durée (par exemple, moins de 5 minutes) apparaîtront si elles ne prennent que quelques minutes supplémentaires - cela pourrait ne pas être un problème. Néanmoins, cette requête est un bon début, et réalisez qu'il existe de nombreuses façons de trouver des déviations - vous pouvez également comparer chaque exécution à la précédente et rechercher les travaux qui ont pris un certain pourcentage de plus que le précédent.
Évidemment, la durée du travail est l'identifiant le plus logique à utiliser pour les problèmes potentiels - qu'il s'agisse d'un travail de sauvegarde, d'un contrôle d'intégrité ou du travail qui supprime la fragmentation et met à jour les statistiques. J'ai constaté que la plus grande variation de durée se situe généralement dans les tâches de suppression de la fragmentation et de mise à jour des statistiques. En fonction de vos seuils de réorganisation par rapport à la reconstruction et de la volatilité de vos données, vous pouvez passer des jours avec principalement des réorganisations, puis avoir soudainement quelques reconstructions d'index pour les grandes tables, où ces reconstructions modifient complètement la durée moyenne. Vous souhaiterez peut-être modifier vos seuils pour certains index ou ajuster le facteur de remplissage afin que les reconstructions se produisent plus souvent ou moins souvent, en fonction de l'index et du niveau de fragmentation. Pour effectuer ces ajustements, vous devez examiner la fréquence à laquelle chaque index est reconstruit ou réorganisé, ce que vous ne pouvez faire que si vous utilisez les scripts d'Ola et que vous vous connectez à la table CommandLog, ou si vous avez déployé votre propre solution et que vous vous connectez. chaque réorganisation ou reconstruction. Pour voir cela à l'aide de la table CommandLog, vous pouvez commencer par vérifier quels index sont le plus souvent modifiés :
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
À partir de cette sortie, vous pouvez commencer à voir quelles tables (et donc les index) ont le plus de volatilité, puis déterminer si le seuil de réorganisation par rapport à la reconstruction doit être ajusté, ou le facteur de remplissage modifié.
Simplifier la vie
Maintenant, il existe une solution plus simple que d'écrire vos propres requêtes, tant que vous utilisez SQL Sentry Event Manager (EM). L'outil surveille toutes les tâches d'agent configurées sur une instance et, à l'aide de la vue du calendrier, vous pouvez rapidement voir quelles tâches ont échoué, ont été annulées ou ont duré plus longtemps que d'habitude :
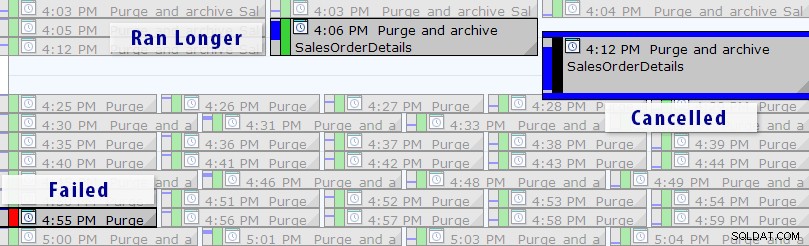 Vue du calendrier de SQL Sentry Event Manager (avec étiquettes ajoutées dans Photoshop)
Vue du calendrier de SQL Sentry Event Manager (avec étiquettes ajoutées dans Photoshop)
Vous pouvez également explorer les exécutions individuelles pour voir combien de temps il a fallu à une tâche pour s'exécuter, et il existe également des graphiques d'exécution pratiques vous permettant de visualiser rapidement tous les modèles d'anomalies de durée ou de conditions de défaillance. Dans ce cas, je constate qu'environ toutes les 15 minutes, la durée d'exécution de cette tâche spécifique a bondi de près de 400 % :
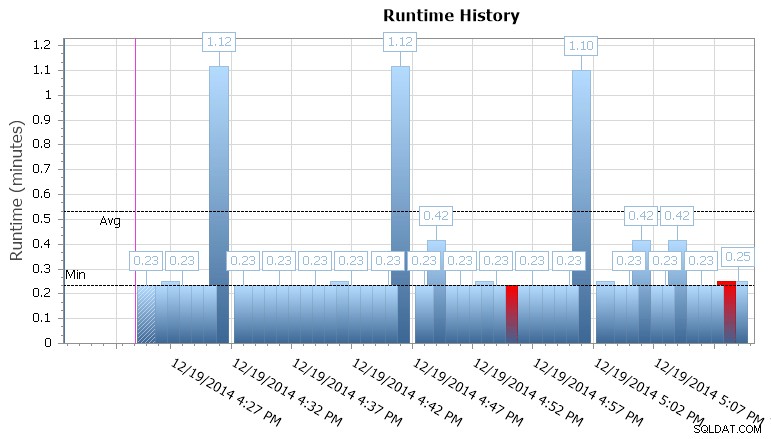 Graphique d'exécution du gestionnaire d'événements SQL Sentry
Graphique d'exécution du gestionnaire d'événements SQL Sentry
Cela me donne un indice que je devrais examiner d'autres tâches planifiées qui peuvent causer des problèmes de concurrence ici. Je pourrais à nouveau effectuer un zoom arrière sur le calendrier pour voir quels autres travaux s'exécutent à peu près au même moment, ou je n'aurais peut-être même pas besoin de regarder pour reconnaître qu'il s'agit d'un travail de création de rapports ou de sauvegarde qui s'exécute sur cette base de données.
Résumé
Je parierais que la plupart d'entre vous ont déjà mis en place les travaux de maintenance nécessaires et que vous avez également configuré des notifications pour les échecs de travail. Si vous n'êtes pas familier avec les durées moyennes de vos travaux, alors c'est votre prochaine étape pour être proactif. Remarque :vous devrez peut-être également vérifier combien de temps vous conservez l'historique des tâches. Lorsque je recherche des écarts dans la durée d'un emploi, je préfère examiner quelques mois de données plutôt que quelques semaines. Vous n'avez pas besoin de mémoriser ces durées d'exécution, mais une fois que vous avez vérifié que vous conservez suffisamment de données pour avoir l'historique à utiliser pour la recherche, commencez à rechercher régulièrement des variations. Dans un scénario idéal, l'augmentation du temps d'exécution peut vous alerter d'un problème potentiel, vous permettant de le résoudre avant qu'un problème ne se produise dans votre environnement de production.