Cet article est le deuxième d'une série sur les bogues, les pièges et les meilleures pratiques de T-SQL. Cette fois, je me concentre sur les bogues classiques impliquant des sous-requêtes. En particulier, je couvre les erreurs de substitution et les problèmes de logique à trois valeurs. Plusieurs des sujets que je couvre dans la série ont été suggérés par d'autres MVP lors d'une discussion que nous avons eue sur le sujet. Merci à Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man et Paul White pour vos suggestions !
Erreur de substitution
Pour illustrer l'erreur de substitution classique, j'utiliserai un scénario simple de commandes clients. Exécutez le code suivant pour créer une fonction d'assistance appelée GetNums, et pour créer et remplir les tables Customers et Orders :
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Actuellement, la table Customers compte 100 clients avec des ID client consécutifs compris entre 1 et 100. 98 de ces clients ont des commandes correspondantes dans la table Orders. Les clients avec les ID 17 et 59 n'ont pas encore passé de commande et n'ont donc aucune présence dans le tableau Commandes.
Vous recherchez uniquement les clients qui ont passé des commandes, et vous essayez d'y parvenir en utilisant la requête suivante (appelez-la Requête 1) :
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Vous êtes censé récupérer 98 clients, mais à la place, vous récupérez les 100 clients, y compris ceux dont les ID sont 17 et 59 :
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Pouvez-vous comprendre ce qui ne va pas ?
Pour ajouter à la confusion, examinez le plan de la requête 1 comme illustré à la figure 1.
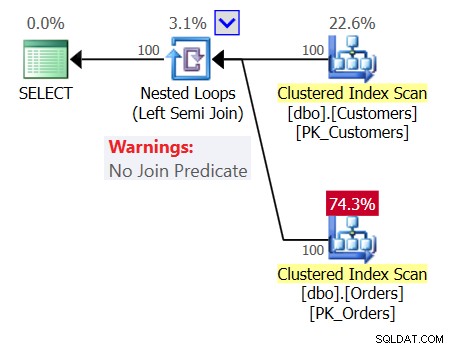 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
Le plan montre un opérateur Nested Loops (Left Semi Join) sans prédicat de jointure, ce qui signifie que la seule condition pour renvoyer un client est d'avoir une table Orders non vide, comme si la requête que vous avez écrite était la suivante :
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Vous vous attendiez probablement à un plan similaire à celui illustré à la figure 2.
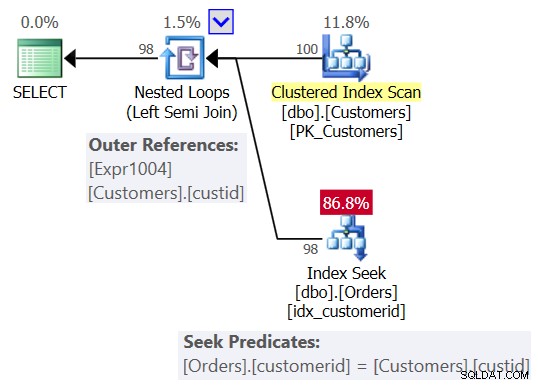 Figure 2 :Plan attendu pour la requête 1
Figure 2 :Plan attendu pour la requête 1
Dans ce plan, vous voyez un opérateur Nested Loops (Left Semi Join), avec une analyse de l'index clusterisé sur Customers comme entrée externe et une recherche dans l'index sur la colonne customerid dans Orders comme entrée interne. Vous voyez également une référence externe (paramètre corrélé) basée sur la colonne custid dans Customers et le prédicat de recherche Orders.customerid =Customers.custid.
Alors pourquoi obtenez-vous le plan de la figure 1 et non celui de la figure 2 ? Si vous ne l'avez pas encore compris, examinez attentivement les définitions des deux tables, en particulier les noms de colonne, et les noms de colonne utilisés dans la requête. Vous remarquerez que la table Customers contient les ID client dans une colonne appelée custid et que la table Orders contient les ID client dans une colonne appelée customerid. Cependant, le code utilise custid dans les requêtes externes et internes. Étant donné que la référence à custid dans la requête interne n'est pas qualifiée, SQL Server doit déterminer de quelle table provient la colonne. Selon la norme SQL, SQL Server est censé rechercher d'abord la colonne de la table qui est interrogée dans la même portée, mais comme il n'y a pas de colonne appelée custid dans Orders, il est ensuite censé la rechercher dans la table à l'extérieur. portée, et cette fois il y a correspondance. Ainsi, involontairement, la référence à custid devient implicitement une référence corrélée, comme si vous écriviez la requête suivante :
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
À condition que Orders ne soit pas vide et que la valeur custid externe ne soit pas NULL (cela ne peut pas être le cas dans notre cas puisque la colonne est définie comme NOT NULL), vous obtiendrez toujours une correspondance car vous comparez la valeur à elle-même . La requête 1 devient donc l'équivalent de :
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Si la table externe supportait les valeurs NULL dans la colonne custid, la requête 1 aurait été équivalente à :
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Vous comprenez maintenant pourquoi la requête 1 a été optimisée avec le plan de la figure 1 et pourquoi vous avez récupéré les 100 clients.
Il y a quelque temps, j'ai rendu visite à un client qui avait un bogue similaire, mais malheureusement avec une instruction DELETE. Réfléchissez un instant à ce que cela signifie. Toutes les lignes du tableau ont été effacées et pas seulement celles qu'ils avaient initialement l'intention de supprimer !
Quant aux meilleures pratiques qui peuvent vous aider à éviter de tels bogues, il y en a deux principales. Tout d'abord, autant que vous pouvez le contrôler, assurez-vous d'utiliser des noms de colonne cohérents dans les tables pour les attributs qui représentent la même chose. Deuxièmement, assurez-vous que les références de colonne sont qualifiées dans les tables dans les sous-requêtes, y compris dans les requêtes autonomes où ce n'est pas une pratique courante. Bien sûr, vous pouvez utiliser un alias de table si vous préférez ne pas utiliser les noms de table complets. En appliquant cette pratique à notre requête, supposons que votre tentative initiale ait utilisé le code suivant :
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Ici, vous n'autorisez pas la résolution de nom de colonne implicite et, par conséquent, SQL Server génère l'erreur suivante :
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Vous allez vérifier les métadonnées de la table Orders, réalisez que vous avez utilisé le mauvais nom de colonne et corrigez la requête (appelez cette requête 2), comme ceci :
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Cette fois, vous obtenez le bon résultat avec 98 clients, à l'exclusion des clients avec les ID 17 et 59 :
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Vous obtenez également le plan attendu présenté précédemment dans la figure 2.
Soit dit en passant, il est clair pourquoi Customers.custid est une référence externe (paramètre corrélé) dans l'opérateur Nested Loops (Left Semi Join) de la figure 2. Ce qui est moins évident, c'est pourquoi Expr1004 apparaît également dans le plan en tant que référence externe. Paul White, un autre MVP de SQL Server, émet l'hypothèse que cela pourrait être lié à l'utilisation des informations de la feuille d'entrée externe pour suggérer au moteur de stockage d'éviter les efforts dupliqués par les mécanismes de lecture anticipée. Vous pouvez trouver les détails ici.
Problème de logique à trois valeurs
Un bogue courant impliquant des sous-requêtes concerne les cas où la requête externe utilise le prédicat NOT IN et la sous-requête peut potentiellement renvoyer des valeurs NULL parmi ses valeurs. Par exemple, supposons que vous deviez pouvoir stocker des commandes dans notre table Orders avec un NULL comme ID client. Un tel cas représenterait une commande qui n'est associée à aucun client ; par exemple, une commande qui compense les incohérences entre le nombre réel de produits et le nombre enregistré dans la base de données.
Utilisez le code suivant pour recréer la table Orders avec la colonne custid autorisant les valeurs NULL, et pour l'instant remplissez-la avec les mêmes exemples de données qu'avant (avec les commandes par ID client 1 à 100, à l'exclusion de 17 et 59) :
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Notez que pendant que nous y sommes, j'ai suivi la meilleure pratique discutée dans la section précédente pour utiliser des noms de colonnes cohérents dans les tables pour les mêmes attributs, et j'ai nommé la colonne dans la table Orders custid comme dans la table Customers.
Supposons que vous ayez besoin d'écrire une requête qui renvoie les clients qui n'ont pas passé de commande. Vous trouvez la solution simpliste suivante en utilisant le prédicat NOT IN (appelez-le Requête 3, première exécution) :
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Cette requête renvoie le résultat attendu avec les clients 17 et 59 :
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Un inventaire est effectué dans l'entrepôt de l'entreprise et une incohérence est constatée entre la quantité réelle de certains produits et la quantité enregistrée dans la base de données. Ainsi, vous ajoutez une commande de compensation fictive pour tenir compte de l'incohérence. Puisqu'il n'y a pas de client réel associé à la commande, vous utilisez un NULL comme ID client. Exécutez le code suivant pour ajouter un tel en-tête de commande :
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Exécutez la requête 3 pour la deuxième fois :
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Cette fois, vous obtenez un résultat vide :
custid companyname ------- ------------ (0 rows affected)
De toute évidence, quelque chose ne va pas. Vous savez que les clients 17 et 59 n'ont passé aucune commande, et en effet ils apparaissent dans la table Clients mais pas dans la table Commandes. Pourtant, le résultat de la requête indique qu'aucun client n'a passé de commande. Pouvez-vous déterminer où se trouve le bogue et comment le corriger ?
Le bogue a à voir avec le NULL dans la table Orders, bien sûr. Pour SQL, un NULL est un marqueur pour une valeur manquante qui pourrait représenter un client applicable. SQL ne sait pas que pour nous, le NULL représente un client manquant et inapplicable (non pertinent). Pour tous les clients de la table Customers qui sont présents dans la table Orders, le prédicat IN trouve une correspondance donnant TRUE et la partie NOT IN en fait un FALSE, par conséquent la ligne client est ignorée. Jusqu'ici tout va bien. Mais pour les clients 17 et 59, le prédicat IN renvoie UNKNOWN puisque toutes les comparaisons avec des valeurs non NULL renvoient FALSE, et la comparaison avec NULL renvoie UNKNOWN. N'oubliez pas que SQL suppose que NULL peut représenter n'importe quel client applicable, de sorte que la valeur logique UNKNOWN indique qu'il est inconnu si l'ID client externe est égal à l'ID client NULL interne. FAUX OU FAUX… OU INCONNU est INCONNU. Ensuite, la partie NOT IN appliquée à UNKNOWN donne toujours UNKNOWN.
En termes anglais plus simples, vous avez demandé de renvoyer les clients qui n'ont pas passé de commandes. Donc, naturellement, la requête supprime tous les clients de la table Customers qui sont présents dans la table Orders car on sait avec certitude qu'ils ont passé des commandes. Quant au reste (17 et 59 dans notre cas), la requête les rejette depuis SQL, tout comme on ne sait pas s'ils ont passé des commandes, on ne sait pas non plus s'ils n'ont pas passé de commandes, et le filtre a besoin de certitude (TRUE) dans afin de retourner une ligne. Quel cornichon !
Ainsi, dès que le premier NULL entre dans la table Orders, à partir de ce moment, vous obtenez toujours un résultat vide de la requête NOT IN. Qu'en est-il des cas où vous n'avez pas réellement de valeurs NULL dans les données, mais la colonne autorise les valeurs NULL ? Comme vous l'avez vu lors de la première exécution de la requête 3, dans un tel cas, vous obtenez le résultat correct. Vous pensez peut-être que l'application n'introduira jamais de valeurs NULL dans les données, vous n'avez donc rien à craindre. C'est une mauvaise pratique pour plusieurs raisons. D'une part, si une colonne est définie comme autorisant les NULL, il est à peu près certain que les NULL finiront par y arriver même s'ils ne sont pas censés le faire ; C'est juste une question de temps. Cela peut être le résultat de l'importation de mauvaises données, d'un bogue dans l'application et d'autres raisons. D'autre part, même si les données ne contiennent pas de NULL, si la colonne les autorise, l'optimiseur doit tenir compte de la possibilité que des NULL soient présents lors de la création du plan de requête, et dans notre requête NOT IN, cela entraîne une pénalité de performance . Pour le démontrer, considérez le plan de la première exécution de la requête 3 avant d'ajouter la ligne avec la valeur NULL, comme illustré à la figure 3.
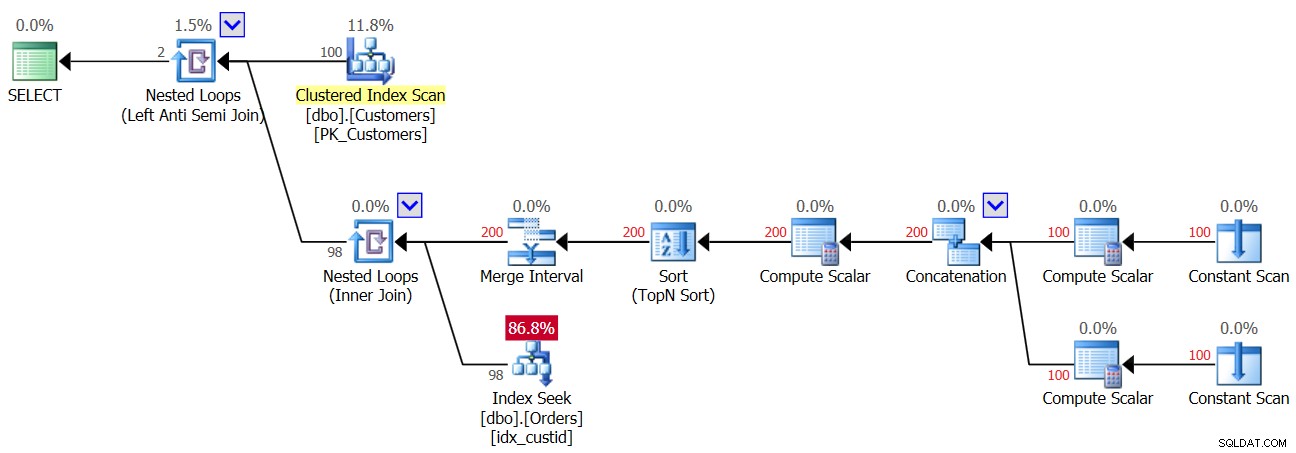 Figure 3 :Plan de la première exécution de la requête 3
Figure 3 :Plan de la première exécution de la requête 3
L'opérateur Top Nested Loops gère la logique Left Anti Semi Join. Il s'agit essentiellement d'identifier les non-correspondances et de court-circuiter l'activité interne dès qu'une correspondance est trouvée. La partie externe de la boucle extrait les 100 clients de la table Customers, par conséquent la partie interne de la boucle est exécutée 100 fois.
La partie interne de la boucle supérieure exécute un opérateur Nested Loops (Inner Join). La partie externe de la boucle inférieure crée deux lignes par client, une pour un cas NULL et une autre pour l'ID client actuel, dans cet ordre. Ne laissez pas l'opérateur Merge Interval vous confondre. Il est normalement utilisé pour fusionner des intervalles qui se chevauchent, par exemple, un prédicat tel que col1 ENTRE 20 ET 30 OU col1 ENTRE 25 ET 35 est converti en col1 ENTRE 20 ET 35. Cette idée peut être généralisée pour supprimer les doublons dans un prédicat IN. Dans notre cas, il ne peut pas vraiment y avoir de doublons. En termes simplifiés, comme mentionné, imaginez que la partie externe de la boucle crée deux lignes par client, la première pour un cas NULL et la seconde pour l'ID client actuel. Ensuite, la partie interne de la boucle effectue d'abord une recherche dans l'index idx_custid sur Orders pour rechercher un NULL. Si un NULL est trouvé, il n'active pas la deuxième recherche pour l'ID client actuel (rappelez-vous le court-circuit géré par la boucle Anti Semi Join supérieure). Dans un tel cas, le client externe est rejeté. Mais si un NULL n'est pas trouvé, la boucle inférieure active une seconde recherche pour rechercher l'ID client actuel dans Orders. S'il est trouvé, le client externe est rejeté. S'il n'est pas trouvé, le client externe est renvoyé. Cela signifie que lorsque les NULL ne sont pas présents dans les commandes, ce plan effectue deux recherches par client ! Cela peut être observé dans le plan comme le nombre de lignes 200 dans l'entrée externe de la boucle inférieure. Par conséquent, voici les statistiques d'E/S qui sont signalées pour la première exécution :
Table 'Orders'. Scan count 200, logical reads 603
Le plan de la deuxième exécution de la requête 3, après l'ajout d'une ligne avec un NULL à la table des commandes, est illustré à la figure 4.
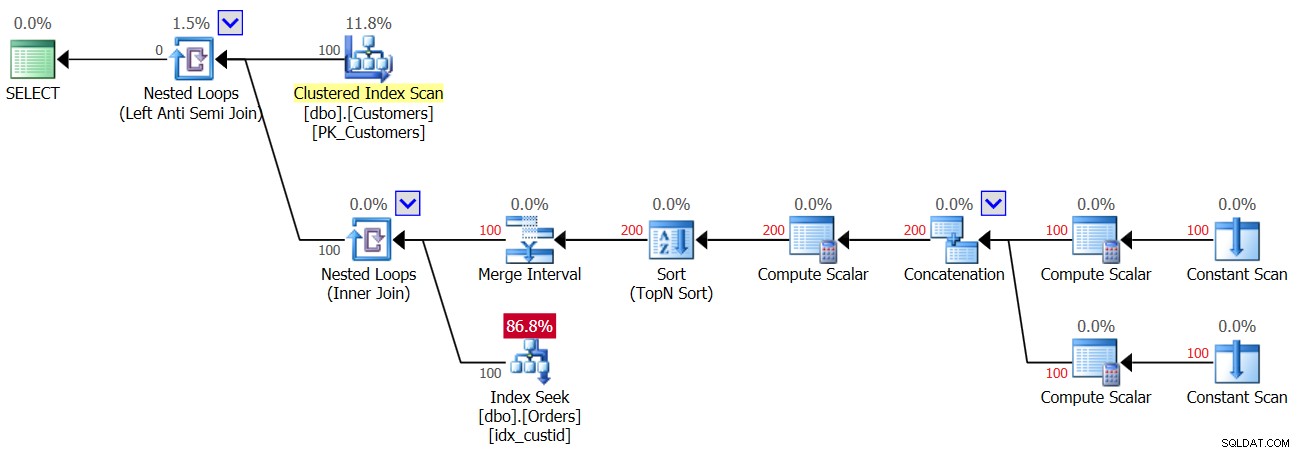 Figure 4 :Plan de la deuxième exécution de la requête 3
Figure 4 :Plan de la deuxième exécution de la requête 3
Puisqu'un NULL est présent dans la table, pour tous les clients, la première exécution de l'opérateur Index Seek trouve une correspondance et, par conséquent, tous les clients sont ignorés. Alors youpi, nous ne faisons qu'une seule recherche par client et non deux, donc cette fois vous obtenez 100 recherches et non 200 ; cependant, cela signifie en même temps que vous obtenez un résultat vide !
Voici les statistiques d'E/S signalées pour la deuxième exécution :
Table 'Orders'. Scan count 100, logical reads 300
Une solution à cette tâche lorsque des valeurs NULL sont possibles parmi les valeurs renvoyées dans la sous-requête consiste simplement à les filtrer, comme ceci (appelez-la Solution 1/Requête 4) :
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Ce code génère la sortie attendue :
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
L'inconvénient de cette solution est que vous devez vous rappeler d'ajouter le filtre. Je préfère une solution utilisant le prédicat NOT EXISTS, où la sous-requête a une corrélation explicite comparant l'ID client de la commande à l'ID client du client, comme ceci (appelez-la Solution 2/Requête 5) :
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
N'oubliez pas qu'une comparaison basée sur l'égalité entre un NULL et n'importe quoi donne UNKNOWN, et UNKNOWN est ignoré par un filtre WHERE. Ainsi, si des valeurs NULL existent dans les commandes, elles sont éliminées par le filtre de la requête interne sans que vous ayez besoin d'ajouter un traitement NULL explicite, et vous n'avez donc pas à vous soucier de savoir si les valeurs NULL existent ou non dans les données.
Cette requête génère le résultat attendu :
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Les plans des deux solutions sont illustrés à la figure 5.
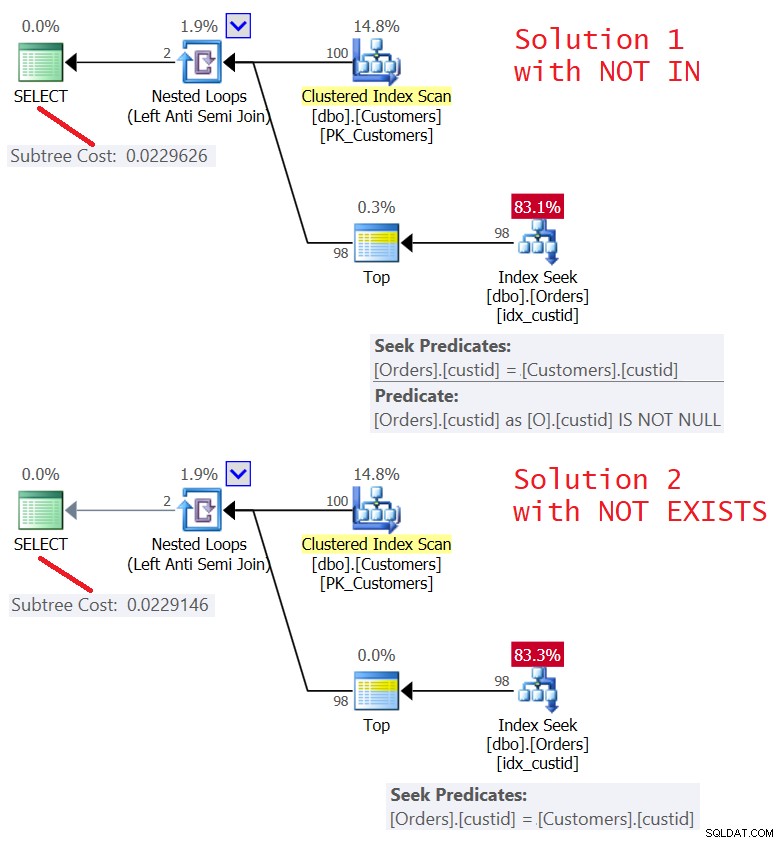 Figure 5 :Plans pour la requête 4 (solution 1) et la requête 5 (solution 2 )
Figure 5 :Plans pour la requête 4 (solution 1) et la requête 5 (solution 2 )
Comme vous pouvez le voir, les plans sont presque identiques. Ils sont également assez efficaces, utilisant une optimisation Left Semi Join avec un court-circuit. Les deux n'effectuent que 100 recherches dans l'index idx_custid sur Orders, et avec l'opérateur Top, appliquent un court-circuit après avoir touché une ligne dans la feuille.
Les statistiques d'E/S pour les deux requêtes sont les mêmes :
Table 'Orders'. Scan count 100, logical reads 348
Une chose à considérer cependant est de savoir s'il y a une chance que la table externe ait des valeurs NULL dans la colonne corrélée (custid dans notre cas). Très peu susceptible d'être pertinent dans un scénario tel que les commandes des clients, mais pourrait être pertinent dans d'autres scénarios. Si tel est le cas, les deux solutions gèrent incorrectement un NULL externe.
Pour illustrer cela, supprimez et recréez la table Customers avec un NULL comme l'un des ID client en exécutant le code suivant :
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); La solution 1 ne renverra pas de NULL externe, qu'un NULL interne soit présent ou non.
La solution 2 renverra un NULL externe, qu'un NULL interne soit présent ou non.
Si vous souhaitez gérer les valeurs NULL comme vous gérez les valeurs non NULL, c'est-à-dire, renvoyer le NULL s'il est présent dans les clients mais pas dans les commandes, et ne le renvoyez pas s'il est présent dans les deux, vous devez modifier la logique de la solution pour utiliser une distinction comparaison basée sur l'égalité au lieu d'une comparaison basée sur l'égalité. Ceci peut être réalisé en combinant le prédicat EXISTS et l'opérateur d'ensemble EXCEPT, comme ceci (appelez ceci Solution 3/Requête 6) :
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Étant donné qu'il existe actuellement des valeurs NULL dans les clients et les commandes, cette requête ne renvoie pas correctement la valeur NULL. Voici le résultat de la requête :
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Exécutez le code suivant pour supprimer la ligne contenant la valeur NULL de la table des commandes et réexécutez la solution 3 :
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Cette fois, puisqu'un NULL est présent dans Customers mais pas dans Orders, le résultat inclut le NULL :
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Le plan de cette solution est illustré à la figure 6 :
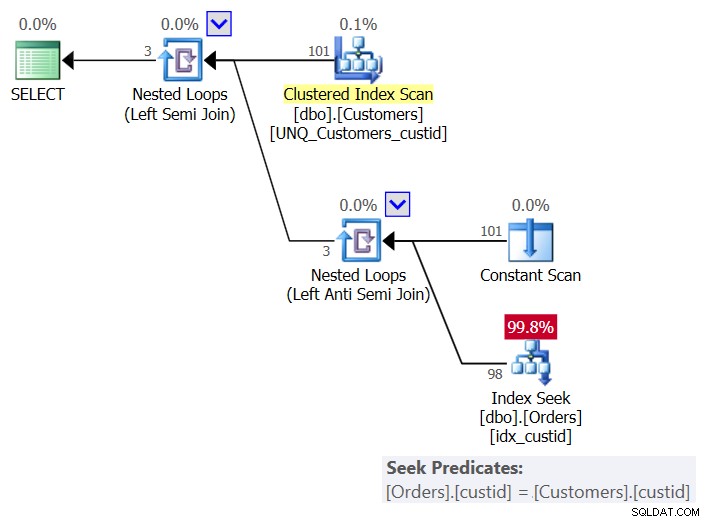 Figure 6 :Plan pour la requête 6 (solution 3)
Figure 6 :Plan pour la requête 6 (solution 3)
Par client, le plan utilise un opérateur Constant Scan pour créer une ligne avec le client actuel et applique une recherche unique dans l'index idx_custid sur Orders pour vérifier si le client existe dans Orders. Vous vous retrouvez avec une recherche par client. Étant donné que nous avons actuellement 101 clients dans le tableau, nous obtenons 101 recherches.
Voici les statistiques d'E/S pour cette requête :
Table 'Orders'. Scan count 101, logical reads 415
Conclusion
Ce mois-ci, j'ai couvert les bogues, les pièges et les meilleures pratiques liés aux sous-requêtes. J'ai couvert les erreurs de substitution et les problèmes de logique à trois valeurs. N'oubliez pas d'utiliser des noms de colonne cohérents dans toutes les tables et de toujours qualifier les colonnes de table dans les sous-requêtes, même lorsqu'elles sont autonomes. N'oubliez pas également d'appliquer une contrainte NOT NULL lorsque la colonne n'est pas censée autoriser les valeurs NULL, et de toujours prendre en compte les valeurs NULL lorsqu'elles sont possibles dans vos données. Assurez-vous d'inclure des valeurs NULL dans vos exemples de données lorsqu'elles sont autorisées afin de pouvoir détecter plus facilement les bogues dans votre code lorsque vous le testez. Soyez prudent avec le prédicat NOT IN lorsqu'il est combiné avec des sous-requêtes. Si des valeurs NULL sont possibles dans le résultat de la requête interne, le prédicat NOT EXISTS est généralement l'alternative préférée.