Le type et le nombre de verrous acquis et libérés lors de l'exécution de la requête peuvent avoir un effet surprenant sur les performances (lors de l'utilisation d'un niveau d'isolement de verrouillage comme la lecture validée par défaut) même en l'absence d'attente ou de blocage. Il n'y a aucune information dans les plans d'exécution pour indiquer la quantité d'activité de verrouillage pendant l'exécution, ce qui rend plus difficile la détection lorsqu'un verrouillage excessif cause un problème de performances.
Pour explorer certains comportements de verrouillage moins connus dans SQL Server, je réutiliserai les requêtes et les exemples de données de mon dernier article sur le calcul des médianes. Dans ce post, j'ai mentionné que le OFFSET la solution médiane groupée nécessitait un PAGLOCK explicite indice de verrouillage pour éviter de perdre mal au curseur imbriqué solution, alors commençons par examiner les raisons en détail.
La solution médiane groupée OFFSET
Le test médian groupé a réutilisé les données de l'échantillon de l'article précédent d'Aaron Bertrand. Le script ci-dessous recrée cette configuration d'un million de lignes, composée de dix mille enregistrements pour chacun des cent vendeurs imaginaires :
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Le SQL Server 2012 (et versions ultérieures) OFFSET solution créée par Peter Larsson est la suivante (sans aucun indice de verrouillage) :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Les parties importantes du plan de post-exécution sont présentées ci-dessous :

Avec toutes les données requises en mémoire, cette requête s'exécute en 580 ms en moyenne sur mon ordinateur portable (exécutant SQL Server 2014 Service Pack 1). Les performances de cette requête peuvent être améliorées jusqu'à 320 ms simplement en ajoutant un indice de verrouillage de granularité de page à la table Sales dans la sous-requête apply :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Le plan d'exécution est inchangé (enfin, mis à part le texte d'indication de verrouillage dans showplan XML bien sûr) :
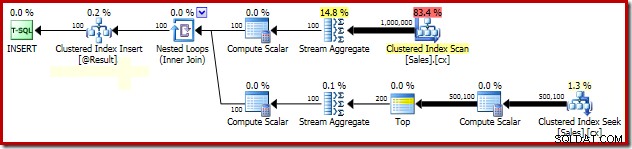
Analyse de verrouillage médian groupé
L'explication de l'amélioration spectaculaire des performances due au PAGLOCK l'indice est assez simple, du moins au début.
Si nous surveillons manuellement l'activité de verrouillage pendant l'exécution de cette requête, nous constatons que sans l'indice de granularité de verrouillage de page, SQL Server acquiert et libère plus d'un demi-million de verrous au niveau des lignes lors de la recherche de l'index clusterisé. Il n'y a aucun blocage à blâmer; le simple fait d'acquérir et de libérer autant de verrous ajoute une surcharge substantielle à l'exécution de cette requête. La demande de verrous au niveau de la page réduit considérablement l'activité de verrouillage, ce qui améliore considérablement les performances.
Le problème de performances de verrouillage de ce plan particulier est limité à la recherche d'index clusterisé dans le plan ci-dessus. L'analyse complète de l'index clusterisé (utilisé pour calculer le nombre de lignes présentes pour chaque vendeur) utilise automatiquement les verrous au niveau de la page. C'est un point intéressant. Le comportement de verrouillage détaillé du moteur SQL Server n'est pas documenté dans la documentation en ligne dans une large mesure, mais divers membres de l'équipe SQL Server ont fait quelques remarques générales au fil des ans, notamment le fait que les analyses sans restriction ont tendance à commencer par prendre la page verrous, tandis que les petites opérations ont tendance à commencer avec des verrous de ligne.
L'optimiseur de requête met certaines informations à la disposition du moteur de stockage, notamment les estimations de cardinalité, les conseils internes pour le niveau d'isolement et la granularité de verrouillage, les optimisations internes pouvant être appliquées en toute sécurité, etc. Encore une fois, ces détails ne sont pas documentés dans la documentation en ligne. En fin de compte, le moteur de stockage utilise une variété d'informations pour décider quels verrous sont nécessaires au moment de l'exécution et à quelle granularité ils doivent être pris.
En remarque, et en rappelant que nous parlons d'une requête s'exécutant sous le niveau d'isolement de transaction de lecture validée de verrouillage par défaut, notez que les verrous de ligne pris sans l'indice de granularité ne se transformeront pas en verrou de table dans ce cas. En effet, le comportement normal sous lecture validée est de libérer le verrou précédent juste avant d'acquérir le verrou suivant, ce qui signifie qu'un seul verrou de ligne partagé (avec ses verrous partagés d'intention de niveau supérieur associés) sera détenu à un moment donné. Étant donné que le nombre de verrous de ligne détenus simultanément n'atteint jamais le seuil, aucune escalade de verrou n'est tentée.
La solution médiane unique OFFSET
Le test de performance pour un calcul de médiane unique utilise un ensemble différent d'échantillons de données, à nouveau reproduits à partir de l'article précédent d'Aaron. Le script ci-dessous crée une table avec dix millions de lignes de données pseudo-aléatoires :
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Le OFFSET la solution est :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Le plan de post-exécution est :

Cette requête s'exécute en 910 ms en moyenne sur ma machine de test. Les performances sont inchangées si un PAGLOCK un indice est ajouté, mais la raison n'est pas ce que vous pensez peut-être…
Analyse de verrouillage à médiane unique
Vous vous attendez peut-être à ce que le moteur de stockage choisisse de toute façon les verrous partagés au niveau de la page, en raison de l'analyse de l'index en cluster, expliquant pourquoi un PAGLOCK l'indice n'a aucun effet. En fait, la surveillance des verrous pris pendant l'exécution de cette requête révèle qu'aucun verrou partagé (S) n'est pris du tout, à n'importe quelle granularité . Les seuls verrous pris sont intentionnellement partagés (IS) au niveau de l'objet et de la page.
L'explication de ce comportement se divise en deux parties. La première chose à remarquer est que l'analyse de l'index clusterisé se trouve sous un opérateur supérieur dans le plan d'exécution. Cela a un effet important sur les estimations de cardinalité, comme indiqué dans le plan de pré-exécution (estimé) :

Le OFFSET et FETCH Les clauses de la requête référencent une expression et une variable, de sorte que l'optimiseur de requête devine le nombre de lignes qui seront nécessaires au moment de l'exécution. L'estimation standard pour Top est de cent lignes. C'est une supposition terrible bien sûr, mais c'est suffisant pour convaincre le moteur de stockage de se verrouiller au niveau de la granularité des lignes plutôt qu'au niveau de la page.
Si nous désactivons l'effet "objectif de ligne" de l'opérateur Top à l'aide de l'indicateur de trace documenté 4138, le nombre estimé de lignes lors de l'analyse passe à dix millions (ce qui est toujours faux, mais dans l'autre sens). Cela suffit pour modifier la décision de granularité de verrouillage du moteur de stockage, de sorte que les verrous partagés au niveau de la page (notez, pas les verrous partagés d'intention) soient pris :
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Le plan d'exécution estimé produit sous l'indicateur de trace 4138 est :

Pour en revenir à l'exemple principal, l'estimation de cent lignes due à l'objectif de ligne deviné signifie que le moteur de stockage choisit de se verrouiller au niveau de la ligne. Cependant, nous n'observons des verrous partagés d'intention (IS) qu'au niveau de la table et de la page. Ces verrous de niveau supérieur seraient tout à fait normaux si nous voyions des verrous partagés (S) au niveau de la ligne, alors où sont-ils allés ?
La réponse est que le moteur de stockage contient une autre optimisation qui peut ignorer les verrous partagés au niveau de la ligne dans certaines circonstances. Lorsque cette optimisation est appliquée, les verrous partagés d'intention de niveau supérieur sont toujours acquis.
Pour résumer, pour la requête à médiane unique :
- L'utilisation d'une variable et d'une expression dans le
OFFSETclause signifie que l'optimiseur devine la cardinalité. - L'estimation basse signifie que le moteur de stockage décide d'une stratégie de verrouillage au niveau des lignes.
- Une optimisation interne signifie que les verrous S au niveau de la ligne sont ignorés lors de l'exécution, ne laissant que les verrous IS au niveau de la page et de l'objet.
La requête médiane unique aurait eu le même problème de performances de verrouillage de ligne que la médiane groupée (en raison de l'estimation inexacte de l'optimiseur de requête), mais elle a été enregistrée par une optimisation de moteur de stockage distincte qui n'a entraîné la prise que de verrous de page et de table partagés par intention. à l'exécution.
Le test médian groupé revisité
Vous vous demandez peut-être pourquoi la recherche d'index clusterisée dans le test médian groupé n'a pas profité de la même optimisation du moteur de stockage pour ignorer les verrous partagés au niveau des lignes. Pourquoi tant de verrous de ligne partagés ont-ils été utilisés, ce qui rend le PAGLOCK indice nécessaire ?
La réponse courte est que cette optimisation n'est pas disponible pour INSERT...SELECT requêtes. Si nous exécutons le SELECT seul (c'est-à-dire sans écrire les résultats dans une table), et sans PAGLOCK indice, l'optimisation du saut de verrou de ligne est appliqué :
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Seuls les verrous partagés d'intention (IS) au niveau de la table et de la page sont utilisés, et les performances augmentent au même niveau que lorsque nous utilisons le PAGLOCK indice. Vous ne trouverez bien sûr pas ce comportement dans la documentation, et il peut changer à tout moment. Néanmoins, il est bon d'en être conscient.
De plus, au cas où vous vous poseriez la question, l'indicateur de trace 4138 n'a aucun effet sur le choix de granularité de verrouillage du moteur de stockage dans ce cas, car le nombre estimé de lignes à la recherche est trop faible (par itération d'application) même avec l'objectif de ligne désactivé.
Avant de tirer des conclusions sur les performances d'une requête, assurez-vous de vérifier le nombre et le type de verrous qu'elle prend lors de son exécution. Bien que SQL Server choisisse généralement la "bonne" granularité, il arrive parfois qu'il se trompe, avec parfois des effets dramatiques sur les performances.