Vous travaillez avec un développeur qui signale un ralentissement des performances pour l'appel de procédure stockée suivant :
EXEC [dbo].[charge_by_date] '2/28/2013';
Vous demandez quel problème le développeur constate, mais la seule information supplémentaire que vous entendez est qu'il "fonctionne lentement". Donc, vous sautez sur l'instance SQL Server et jetez un œil au réel plan d'exécution. Vous faites cela parce que vous êtes intéressé non seulement à quoi ressemble le plan d'exécution, mais aussi au nombre de lignes estimé par rapport au nombre réel pour le plan :
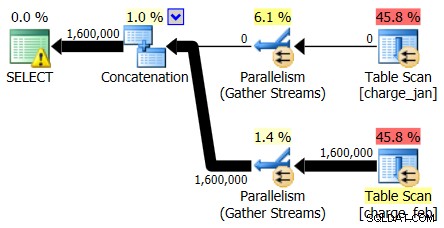
En regardant d'abord les opérateurs du plan, vous pouvez voir quelques détails remarquables :
- Il y a un avertissement dans l'opérateur racine
- Il y a une analyse de table pour les deux tables référencées au niveau feuille (charge_jan et charge_feb) et vous vous demandez pourquoi ce sont toujours des tas et n'ont pas d'index clusterisés
- Vous voyez qu'il n'y a que des lignes circulant dans la table charge_feb et non dans la table charge_jan
- Vous voyez des zones parallèles dans le plan
Quant à l'avertissement dans l'itérateur racine, vous le survolez et voyez qu'il manque des avertissements d'index avec une recommandation pour les index suivants :
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Vous demandez au développeur de la base de données d'origine pourquoi il n'y a pas d'index clusterisé, et la réponse est "Je ne sais pas".
Poursuivant l'enquête avant d'apporter des modifications, vous regardez l'onglet Arborescence du plan dans SQL Sentry Plan Explorer et vous constatez en effet qu'il existe des écarts importants entre les lignes estimées et réelles pour l'une des tables :

Il semble y avoir deux problèmes :
- Une sous-estimation des lignes dans l'analyse de la table charge_jan
- Une surestimation des lignes dans l'analyse de la table charge_feb
Ainsi, les estimations de cardinalité sont asymétrique, et vous vous demandez si cela est lié au reniflage de paramètres. Vous décidez de vérifier la valeur compilée du paramètre et de la comparer à la valeur d'exécution du paramètre, que vous pouvez voir dans l'onglet Paramètres :

En effet il existe des différences entre la valeur d'exécution et la valeur compilée. Vous copiez la base de données dans un environnement de test de type prod, puis testez l'exécution de la procédure stockée avec la valeur d'exécution du 28/02/2013 d'abord, puis du 31/01/2013 par la suite.
Les plans 28/02/2013 et 31/01/2013 ont des formes identiques mais des flux réels de données différents. Les estimations du plan et de la cardinalité du 28/02/2013 étaient les suivantes :
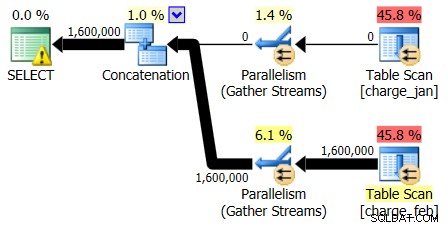

Et tandis que le plan du 28/02/2013 ne montre aucun problème d'estimation de cardinalité, le plan du 31/01/2013 le fait :
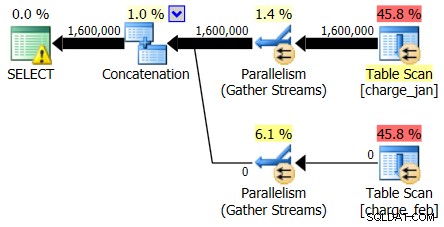

Ainsi, le deuxième plan montre les mêmes surestimations et sous-estimations, juste inversées par rapport au plan d'origine que vous avez examiné.
Vous décidez d'ajouter les index suggérés à l'environnement de test de type prod pour les tables charge_jan et charge_feb et voyez si cela aide. En exécutant les procédures stockées dans l'ordre de janvier/février, vous voyez les nouvelles formes de plan suivantes et les estimations de cardinalité associées :
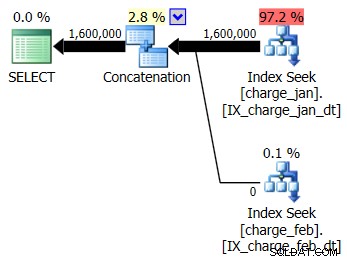

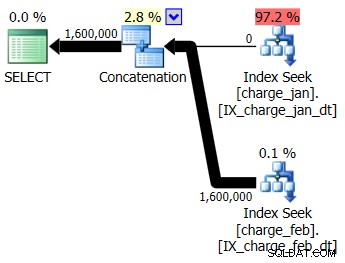

Le nouveau plan utilise une opération Index Seek à partir de chaque table, mais vous voyez toujours zéro ligne provenant d'une table et pas de l'autre, et vous voyez toujours des biais d'estimation de cardinalité basés sur le reniflage de paramètres lorsque la valeur d'exécution est dans un mois différent de la compilation valeur de temps.
Votre équipe a pour politique de ne pas ajouter d'index sans preuve d'avantages suffisants et de tests de régression associés. Vous décidez, pour le moment, de supprimer les index non-cluster que vous venez de créer. Même si vous ne résolvez pas immédiatement les problèmes cluster manquants index, vous décidez de vous en occuper plus tard.
À ce stade, vous réalisez que vous devez approfondir la définition de la procédure stockée, qui est la suivante :
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Ensuite, vous regardez la définition de l'objet charge_view :
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
La vue fait référence aux données de frais qui sont séparées dans différentes tables par date. Et puis vous vous demandez si le deuxième décalage du plan d'exécution de la requête peut être évité en modifiant la définition de la procédure stockée.
Peut-être que si l'optimiseur connaît la valeur au moment de l'exécution, le problème d'estimation de la cardinalité disparaîtra et améliorera les performances globales ?
Vous allez de l'avant et redéfinissez l'appel de procédure stockée comme suit, en ajoutant un indice RECOMPILE (sachant que vous avez également entendu dire que cela peut augmenter l'utilisation du processeur, mais comme il s'agit d'un environnement de test, vous vous sentez en sécurité en l'essayant) :
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Vous réexécutez ensuite la procédure stockée en utilisant la valeur du 31/01/2013, puis la valeur du 28/02/2013.
La forme du plan reste la même, mais le problème d'estimation de la cardinalité est désormais supprimé.
Les données d'estimation de cardinalité au 31/01/2013 indiquent :

Et les données d'estimation de cardinalité du 28/02/2013 indiquent :

Cela vous rend heureux pendant un moment, mais vous réalisez ensuite que la durée d'exécution globale de la requête semble relativement la même qu'auparavant. Vous commencez à douter que le développeur soit satisfait de vos résultats. Vous avez résolu le biais d'estimation de cardinalité, mais sans l'amélioration des performances attendue, vous ne savez pas si vous avez aidé de manière significative.
C'est à ce stade que vous vous rendez compte que le plan d'exécution de la requête n'est qu'un sous-ensemble des informations dont vous pourriez avoir besoin, et vous élargissez donc votre exploration en consultant l'onglet Table I/O. Vous voyez la sortie suivante pour l'exécution du 31/01/2013 :

Et pour l'exécution du 28/02/2013, vous voyez des données similaires :

C'est à ce moment-là que vous vous demandez si les opérations d'accès aux données pour les deux des tableaux sont nécessaires dans chaque plan. Si l'optimiseur sait que vous n'avez besoin que des lignes de janvier, pourquoi accéder à février et vice versa ? N'oubliez pas non plus que l'optimiseur de requête n'a aucune garantie qu'il n'y en a pas lignes réelles des autres mois dans la "mauvaise" table à moins que de telles garanties n'aient été faites explicitement via des contraintes sur la table elle-même.
Vous vérifiez les définitions de table via sp_help pour chaque table et vous ne voyez aucune contrainte définie pour l'une ou l'autre table.
Donc, en tant que test, vous ajoutez les deux contraintes suivantes :
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Vous réexécutez les procédures stockées et voyez les formes de plan et les estimations de cardinalité suivantes.
31/01/2013 exécution :
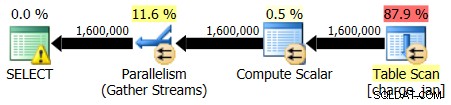

Exécution du 28/02/2013 :


En regardant à nouveau Table I/O, vous voyez la sortie suivante pour l'exécution du 31/01/2013 :

Et pour l'exécution du 28/02/2013, vous voyez des données similaires, mais pour la table charge_feb :

En vous rappelant que vous avez toujours le RECOMPILE dans la définition de la procédure stockée, vous essayez de le supprimer et de voir si vous voyez le même effet. Après cela, vous voyez le retour d'accès à deux tables, mais sans lectures logiques réelles pour la table qui ne contient aucune ligne (par rapport au plan d'origine sans les contraintes). Par exemple, l'exécution du 31/01/2013 a montré la sortie Table I/O suivante :

Vous décidez d'aller de l'avant avec le test de charge des nouvelles contraintes CHECK et de la solution RECOMPILE, en supprimant entièrement l'accès à la table du plan (et les opérateurs de plan associés). Vous vous préparez également à un débat sur la clé d'index clusterisé et un index non clusterisé de prise en charge approprié qui s'adaptera à un ensemble plus large de charges de travail qui accèdent actuellement aux tables associées.