Analyser davantage la requête de la population clé
Dans la partie 3 de notre série de traçage ODBC, nous allons examiner plus en détail les clés de gestion d'accès pour les tables liées ODBC et comment il trie et regroupe les requêtes SELECT. Dans l'article précédent, nous avons appris comment un jeu d'enregistrements de type dynaset est en fait 2 requêtes distinctes, la première requête ne récupérant que les clés de la table liée ODBC qui est ensuite utilisée pour remplir les données. Dans cet article, nous étudierons un peu plus comment Access gère les clés et comment il déduit quelle est la clé à utiliser pour une table liée ODBC parmi les ramifications qu'elle a. Nous allons commencer par le tri.
Ajouter un tri à la requête
Vous avez vu dans l'article précédent que nous avons commencé par un simple SELECT sans commande particulière. Vous avez également vu comment Access a récupéré pour la première fois le CityID et utiliser le résultat de la première requête pour remplir ensuite les requêtes suivantes afin de donner l'impression d'être rapide à l'utilisateur lors de l'ouverture d'un jeu d'enregistrements volumineux. Si vous avez déjà rencontré une situation où l'ajout d'un tri ou d'un regroupement à une requête s'est soudainement ralenti, ceci vous expliquera pourquoi.
Ajoutons un tri sur le StateProvinceID dans une requête Access :
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Maintenant, si nous traçons le SQL ODBC, nous devrions voir la sortie :
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Si vous comparez avec la trace de l'article précédent, vous pouvez voir qu'elles sont identiques sauf pour la première requête. Access place le tri dans la première requête où il utilise pour obtenir les clés. Cela a du sens car en imposant le tri sur les clés qu'il utilise pour parcourir les enregistrements, Access est garanti d'avoir une correspondance un à un entre la position ordinale d'un enregistrement et la façon dont il doit être trié. Il remplit ensuite les enregistrements exactement de la même manière. La seule différence est la séquence de touches qu'il utilise pour remplir les autres requêtes.
Considérons ce qui se passe lorsque nous ajoutons un GROUP BY en faisant un décompte des villes par état :
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Le traçage doit afficher :
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Vous avez peut-être également remarqué que la requête s'ouvre maintenant lentement, et même si elle peut être définie comme un jeu d'enregistrements de type feuille de réponse dynamique, Access a choisi de l'ignorer et de la traiter essentiellement comme un jeu d'enregistrements de type instantané. Cela a du sens car la requête ne peut pas être mise à jour et parce que vous ne pouvez pas vraiment naviguer vers une position arbitraire dans une requête comme celle-ci. Ainsi, vous devez attendre que toutes les lignes aient été récupérées avant de pouvoir naviguer librement. Le StateProvinceID ne peut pas être utilisé pour localiser un enregistrement car il y aurait plusieurs enregistrements dans les Cities table. Bien que j'ai utilisé un GROUP BY dans cet exemple, il n'est pas nécessaire qu'il s'agisse d'un regroupement qui force Access à utiliser un jeu d'enregistrements de type instantané à la place. Utilisation de DISTINCT par exemple aurait le même effet. Une règle empirique utile pour prédire si Access utilisera un jeu d'enregistrements de type feuille de réponse dynamique consiste à demander si une ligne donnée dans le jeu d'enregistrements résultant correspond exactement à une ligne dans la source de données ODBC. Si ce n'est pas le cas, Access utilisera le comportement d'instantané même si la requête était censée utiliser un dynaset. Par conséquent, simplement parce que la valeur par défaut est un jeu d'enregistrements de type feuille de réponse dynamique, cela ne garantit pas qu'il s'agira en fait d'un jeu d'enregistrements de type feuille de réponse dynamique. Il s'agit simplement d'une demande , pas une demande.
Déterminer la clé à utiliser pour la sélection
Vous avez peut-être remarqué dans le SQL tracé précédent dans cet article et dans les articles précédents, Access a utilisé le CityID comme clé. Cette colonne a été récupérée dans la première requête, puis utilisée dans les requêtes préparées suivantes. Mais comment Access sait-il quelle(s) colonne(s) d'une table liée il doit utiliser ? La première tendance serait de dire qu'il recherche une clé primaire et l'utilise. Cependant, ce serait incorrect. En fait, le moteur de base de données Access utilisera les SQLStatistics d'ODBC fonction lors de la liaison ou de la reconnexion de la table pour examiner quels indices sont disponibles. Cette fonction renverra un jeu de résultats avec une ligne pour chaque colonne participant à un index pour tous les index. Ce jeu de résultats est toujours trié et par convention, il triera toujours les index groupés, les index hachés, puis les autres types d'index. Au sein de chaque type d'index, les index seront triés par leurs noms par ordre alphabétique. Le moteur de base de données Access sélectionnera le premier index unique qu'il trouve même s'il ne s'agit pas de la clé primaire réelle. Pour le prouver, nous allons créer une table idiote avec quelques indices étranges :
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Si nous remplissons ensuite la table avec des données et la lions dans Access et ouvrons une vue de feuille de données sur la table liée, nous le verrons dans le SQL ODBC tracé. Par souci de concision, seules les 2 premières commandes sont incluses.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Parce que les
OtherStuff participe à un index clusterisé, il est venu avant la clé primaire réelle et a donc été sélectionné par le moteur de base de données Access pour être utilisé dans un jeu d'enregistrements de type dynaset pour sélectionner une ligne individuelle. C'est également en dépit du fait que le nom de l'index clusterisé unique serait venu après le nom de l'index primaire. Une tactique pour forcer le moteur de base de données Access à sélectionner un index particulier pour une table serait de modifier son type ou de renommer le nom afin qu'il soit trié par ordre alphabétique dans le groupe du type d'index. Dans le cas de SQL Server, les clés primaires sont généralement en cluster et il ne peut y avoir qu'un seul index en cluster, c'est donc un heureux hasard qu'il s'agisse généralement du bon index à utiliser par le moteur de base de données Access. Cependant, si la base de données SQL Server contient des tables avec des clés primaires non clusterisées et qu'il existe un index unique clusterisé, cela peut ne pas être le choix optimal. Dans les cas où il n'y a pas du tout d'index clusterisés, vous pouvez influencer les index uniques à utiliser en nommant l'index de sorte qu'il soit trié avant les autres index. Cela peut être utile avec d'autres logiciels RDBMS où la création d'un index clusterisé pour la clé primaire n'est pas pratique ou possible. Index côté accès pour la vue ou la table SQL liée sans index
Lors de la liaison à une vue SQL ou à une table SQL pour laquelle aucun index ou clé primaire n'est défini, aucun index ne sera disponible pour le moteur de base de données Access. Si vous avez utilisé le gestionnaire de tables liées pour lier une table ou une vue SQL sans index, vous avez peut-être vu une boîte de dialogue comme celle-ci :
 Si nous sélectionnons l'
Si nous sélectionnons l'ID , terminez la liaison, ouvrez la table liée en mode création, puis la boîte de dialogue des index, nous devrions voir ceci :
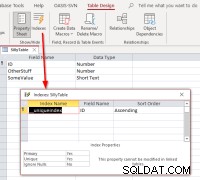 Cela montre que la table a un index nommé
Cela montre que la table a un index nommé __uniqueindex mais il n'existe pas dans la source de données d'origine. Ce qui se passe? La réponse est qu'Access a créé un Access-side index pour son utilisation pour aider à identifier ce qui peut être utilisé comme identifiant d'enregistrement pour ces tables ou vues. S'il vous arrive de relier par programmation les tables plutôt que d'utiliser le gestionnaire de tables liées, vous trouverez nécessaire de répliquer le comportement afin de rendre ces tables liées pouvant être mises à jour. Cela peut être fait en exécutant une commande Access SQL :
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Vous pouvez utiliser par exemple,
CurrentDb.Execute pour exécuter Access SQL afin de créer l'index sur la table liée. Cependant, vous ne devez pas l'exécuter en tant que requête directe car l'index n'est pas réellement créé sur le serveur. Seuls les avantages d'Access permettent la mise à jour de cette table liée. Il convient de noter qu'Access n'autorisera qu'un seul index pour une telle table liée et uniquement s'il n'a pas déjà d'index. Néanmoins, vous pouvez voir que l'utilisation d'une vue SQL peut être une option souhaitable dans les cas où la conception de la base de données ne vous permet pas d'utiliser des index clusterisés et vous ne voulez pas jouer avec le nom de l'index pour persuader le moteur de base de données Access d'utiliser cet index, pas cet indice. Vous pouvez contrôler explicitement l'index et les colonnes qu'il doit inclure lors de la liaison de la vue SQL.
Conclusion
Dans l'article précédent, nous avons vu qu'un jeu d'enregistrements de type dynaset émet généralement 2 requêtes. La première requête traite généralement du remplissage du Nous avons examiné de plus près comment Access gère le remplissage des clés qu'il utilisera pour un jeu d'enregistrements de type dynaset. Nous avons vu comment Access convertira réellement tout tri à partir de la requête Access d'origine, puis l'utilisera dans la requête de population clé. Nous avons vu que l'ordre de la requête de la population clé a un impact direct sur la manière dont les données du jeu d'enregistrements seront triées et présentées à l'utilisateur. Cela permet à l'utilisateur de faire des choses comme sauter à un enregistrement arbitraire basé sur la position ordinale de la liste.
Nous avons ensuite vu que le regroupement et d'autres opérations SQL qui empêchent le mappage un-un entre la ligne renvoyée et la ligne d'origine amèneront Access à traiter la requête Access comme s'il s'agissait d'un jeu d'enregistrements de type instantané malgré la demande d'un jeu d'enregistrements de type dynaset.
Nous avons ensuite regardé comment Access détermine la clé à utiliser pour gérer les mises à jour avec une table liée ODBC. Contrairement à ce à quoi on pourrait s'attendre, il ne sélectionnera pas nécessairement la clé primaire de la table mais plutôt le premier index unique qu'il trouve, selon le type d'index et le nom de l'index. Nous avons discuté des stratégies pour s'assurer qu'Access sélectionnera l'index unique correct. Nous avons examiné la vue SQL qui n'a normalement pas d'index et avons discuté d'une méthode pour nous informer Access comment saisir une vue SQL ou une table qui n'a pas de clé primaire, nous permettant plus de contrôle sur la façon dont Access gérera les mises à jour pour ces tables liées ODBC.
Dans le prochain article, nous verrons comment Access exécute réellement les mises à jour sur les données lorsque les utilisateurs apportent des modifications via la requête Access ou la source d'enregistrement.
Nos experts en accès sont disponibles pour vous aider. Appelez-nous au 773-809-5456 ou envoyez-nous un e-mail à sales@itimpact.com.



