Il s'agit de la dernière partie d'une série en cinq parties qui analyse en profondeur la façon dont les plans parallèles en mode ligne de SQL Server commencent à s'exécuter. La partie 1 a initialisé le contexte d'exécution zéro pour la tâche parente et la partie 2 a créé l'arborescence d'analyse des requêtes. La partie 3 a commencé l'analyse de la requête, effectué une phase préliminaire traitement, et a lancé les premières tâches parallèles supplémentaires dans la branche C. La partie 4 a décrit la synchronisation des échanges et le démarrage des branches C et D du plan parallèle.
Démarrage des tâches parallèles de la branche B
Rappel des branches de ce plan parallèle (cliquez pour agrandir) :
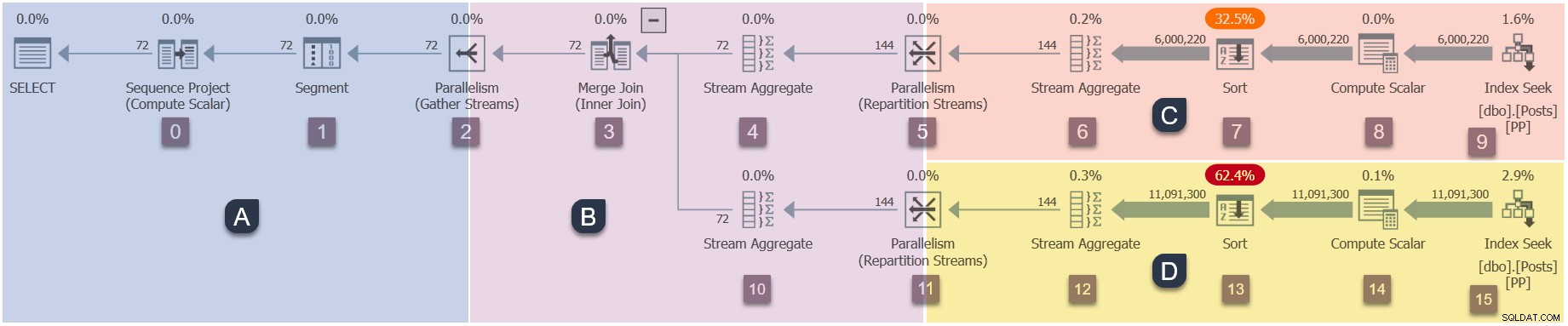
Il s'agit de la quatrième étape de la séquence d'exécution :
- Branche A (tâche parente).
- Branche C (tâches parallèles supplémentaires).
- Branche D (tâches parallèles supplémentaires).
- Branche B (tâches parallèles supplémentaires).
Le seul thread actif en ce moment (non suspendu sur CXPACKET ) est la tâche parent , qui se trouve du côté consommateur de l'échange de flux de répartition au nœud 11 dans la branche B :
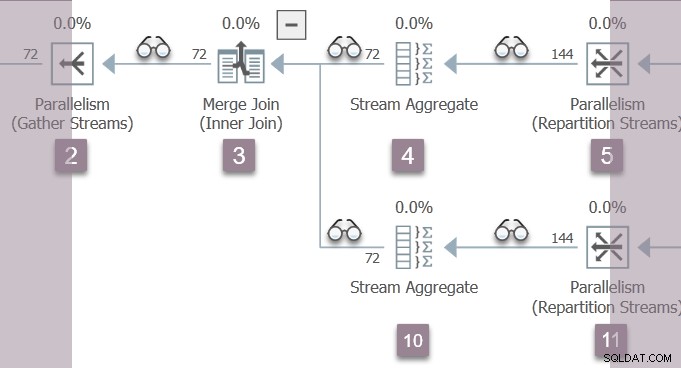
La tâche parent revient maintenant des premières phases imbriquées appels, en définissant les temps écoulés et les temps CPU dans les profileurs au fur et à mesure. Les premières et dernières heures d'activité ne sont pas mis à jour au cours de la première phase de traitement. N'oubliez pas que ces nombres sont enregistrés par rapport au contexte d'exécution zéro - les tâches parallèles de la branche B n'existent pas encore.
La tâche parente monte l'arborescence du nœud 11, via l'agrégat de flux au nœud 10 et la jointure de fusion au nœud 3, jusqu'à l'échange de flux de collecte au nœud 2.
Le traitement de la phase préliminaire est maintenant terminé .
Avec les EarlyPhases d'origine appeler au nœud 2 recueillir les flux échanger enfin terminé, la tâche parent revient à l'ouverture de cet échange (vous vous souviendrez peut-être à peu près de cet appel dès le début de cette série). La méthode open au nœud 2 appelle maintenant CQScanExchangeNew::StartAllProducers pour créer les tâches parallèles pour la branche B.
La tâche parente maintenant attend sur CXPACKET chez le consommateur côté du nœud 2 regrouper les flux échanger. Cette attente se poursuivra jusqu'à ce que les tâches de la branche B nouvellement créées aient terminé leur Open imbriqué appels et renvoyé pour terminer l'ouverture du côté producteur de l'échange de flux de collecte.
Tâches parallèles de la branche B ouvertes
Les deux nouvelles tâches parallèles de la branche B commencent chez le producteur côté du nœud 2 regrouper les flux échanger. Suivant le modèle d'exécution itératif en mode ligne habituel, ils appellent :
CQScanXProducerNew::Open(nœud 2 côté producteur ouvert).CQScanProfileNew::Open(profileur pour le nœud 3).CQScanMergeJoinNew::Open(jointure de fusion du nœud 3).CQScanProfileNew::Open(profileur pour le nœud 4).CQScanStreamAggregateNew::Open(agrégat de flux nœud 4).CQScanProfileNew::Open(profileur pour le nœud 5).CQScanExchangeNew::Open(échange de flux de répartition).
Les tâches parallèles suivent toutes les deux l'entrée externe (supérieure) de la jointure de fusion, tout comme le traitement de la phase initiale.
Fin de l'échange
Lorsque les tâches de la branche B arrivent chez le consommateur côté de l'échange de flux de répartition au nœud 5, chaque tâche :
- S'enregistre auprès du port d'échange (
CXPort). - Crée les canaux (
CXPipe) qui relient cette tâche à une ou plusieurs tâches côté producteur (selon le type d'échange). L'échange courant est une répartition des flux, donc chaque tâche consommatrice a deux canaux (au DOP 2). Chaque consommateur peut recevoir des lignes de l'un ou l'autre des deux producteurs. - Ajoute un
CXPipeMergepour fusionner lignes de plusieurs canaux (puisqu'il s'agit d'un échange préservant l'ordre). - Crée des paquets de lignes (nommé
CXPacketde manière confuse ) utilisé pour le contrôle de flux et pour tamponner les rangées à travers les tuyaux d'échange. Celles-ci sont allouées à partir de la mémoire de requête précédemment accordée.
Une fois que les deux tâches parallèles côté consommateur ont terminé ce travail, l'échange du nœud 5 est prêt à fonctionner. Les deux consommateurs (en Branche B) et les deux producteurs (en Branche C) ont tous ouvert le port d'échange, donc le nœud 5 CXPACKET attend la fin .
Point de contrôle
Dans l'état actuel des choses :
- La tâche parent dans la Branche A est en attente sur
CXPACKETdu côté consommateur du noeud 2 se rassemblent les échanges de flux. Cette attente se poursuivra jusqu'à ce que les deux producteurs du nœud 2 reviennent et ouvrent l'échange. - Les deux tâches parallèles de la branche B sont exécutables . Ils viennent d'ouvrir le côté consommateur de l'échange de flux de répartition au nœud 5.
- Les deux tâches parallèles de la branche C viennent de sortir de leur
CXPACKETattendez, et sont maintenant exécutables . Les deux agrégats de flux au nœud 6 (un par tâche parallèle) peuvent commencer à agréger les lignes des deux tris au nœud 7. Rappelez-vous que les recherches d'index au nœud 9 ont été fermées il y a quelque temps, lorsque les tris ont terminé leur phase d'entrée. - Les deux tâches parallèles de la Branche D sont en attente sur
CXPACKETdu côté producteur de l'échange de flux de répartition au nœud 11. Ils attendent que le côté consommateur du nœud 11 soit ouvert par les deux tâches parallèles de la branche B. Les recherches d'index se sont fermées et les tris sont prêts à passer à leur phase de sortie.
Plusieurs branches actives
C'est la première fois que nous avons plusieurs branches (B et C) actives en même temps, ce qui pourrait être difficile à discuter. Heureusement, la conception de la requête de démonstration est telle que les agrégats de flux dans la branche C ne produiront que quelques lignes. Le petit nombre de lignes de sortie étroites s'intégrera facilement dans les tampons du paquet de lignes au nœud 5 répartition des flux d'échange. Les tâches de la branche C peuvent donc poursuivre leur travail (et éventuellement se fermer) sans attendre que le consommateur des flux de répartition du nœud 5 récupère les lignes.
De manière pratique, cela signifie que nous pouvons laisser les deux tâches parallèles de la branche C s'exécuter en arrière-plan sans nous en soucier. Nous n'avons qu'à nous préoccuper de ce que font les deux tâches parallèles de la branche B.
L'ouverture de la succursale B est terminée
Un rappel de la branche B :
Les deux travailleurs parallèles de la branche B reviennent de leur Open les appels au noeud 5 répartissent les flux d'échange. Cela les ramène via l'agrégat de flux au nœud 4, à la jointure de fusion au nœud 3.
Parce que nous montons l'arborescence dans le Open méthode, les profileurs au-dessus du nœud 5 et du nœud 4 enregistrent le dernier actif temps, ainsi que le cumul des temps écoulés et CPU (par tâche). Nous n'exécutons pas les premières phases sur la tâche parent maintenant, donc les nombres enregistrés pour le contexte d'exécution zéro ne sont pas affectés.
À la jointure de fusion, les deux tâches parallèles de la branche B commencent descendant l'entrée interne (inférieure), les faisant passer par l'agrégat de flux au nœud 10 (et quelques profileurs) vers le côté consommateur de l'échange de flux de répartition au nœud 11.
La branche D reprend l'exécution
Une répétition des événements de la branche C au nœud 5 se produit maintenant au niveau des flux de répartition du nœud 11. Le côté consommateur de l'échange du nœud 11 est terminé et ouvert. Les deux producteurs de la Branche D mettent fin à leur CXPACKET attend, devenant exécutable de nouveau. Nous laisserons les tâches de la branche D s'exécuter en arrière-plan, en plaçant leurs résultats dans des tampons d'échange.
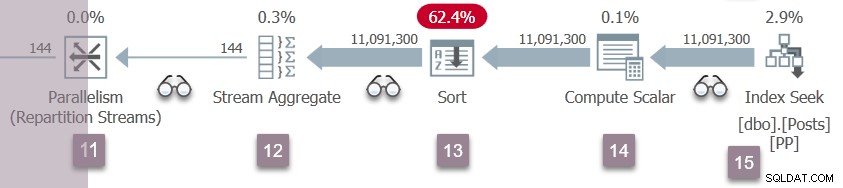
Il y a maintenant six tâches parallèles (deux dans les branches B, C et D) partageant en coopération le temps sur les deux planificateurs affectés à des tâches parallèles supplémentaires dans cette requête.
L'ouverture de la succursale A est terminée
Les deux tâches parallèles de la branche B reviennent de leur Open appels au niveau de l'échange de flux de répartition du nœud 11, au-delà de l'agrégat de flux du nœud 10, via la jointure de fusion au nœud 3, et retour au côté producteur des flux de collecte au nœud 2. Profileur dernier actif et les temps écoulés et CPU accumulés sont mis à jour au fur et à mesure que nous montons l'arborescence dans Open imbriqué méthodes.
Chez le producteur côté de l'échange de flux de collecte, les deux tâches parallèles de la branche B se synchronisent en ouvrant le port d'échange, puis attendent CXPACKET pour que le côté consommateur s'ouvre.
La tâche parente l'attente du côté consommateur des flux de collecte est maintenant publiée depuis son CXPACKET attendre, ce qui lui permet de terminer l'ouverture du port d'échange côté consommateur. Cela libère à son tour les producteurs de leur (bref) CXPACKET Attendez. Les flux de collecte du nœud 2 ont maintenant été ouverts par tous les propriétaires.
Fin de l'analyse de la requête
La tâche parente monte maintenant l'arborescence d'analyse des requêtes à partir de l'échange de flux de collecte, revenant de l'Open appels au central, segment , et projet de séquence opérateurs de la branche A.
Ceci termine l'ouverture l'arborescence d'analyse des requêtes, initiée tout à l'heure par l'appel à CQueryScan::StartupQuery . Toutes les branches du plan parallèle ont maintenant commencé à s'exécuter.
Renvoyer des lignes
Le plan d'exécution est prêt à commencer à renvoyer des lignes en réponse à GetRow appels à la racine de l'arborescence d'analyse des requêtes, initiée par un appel à CQueryScan::GetRow . Je ne vais pas entrer dans les détails, car cela dépasse strictement le cadre d'un article sur la façon dont les plans parallèles démarrent .
Pourtant, la brève séquence est :
- La tâche parent appelle
GetRowsur le projet de séquence, qui appelleGetRowsur le segment, qui appelleGetRowsur le consommateur côté de l'échange de flux de collecte. - Si aucune ligne n'est encore disponible sur l'échange, la tâche parente attend sur
CXCONSUMER. - Pendant ce temps, les tâches parallèles de la branche B qui s'exécutent indépendamment appellent de manière récursive
GetRowen commençant par le producteur côté de l'échange de flux de collecte. - Les lignes sont fournies à la branche B par les côtés consommateurs des échanges de flux de répartition aux nœuds 5 et 12.
- Les branches C et D traitent toujours les lignes de leurs tris via leurs agrégats de flux respectifs. Les tâches de la branche B peuvent devoir attendre sur
CXCONSUMERaux nœuds 5 et 12 des flux de répartition pour qu'un paquet complet de lignes devienne disponible. - Lignes issues du
GetRowimbriqué les appels dans la branche B sont assemblés en paquets de lignes chez le producteur côté de l'échange de flux de collecte. - Le
CXCONSUMERde la tâche parent l'attente du côté consommateur des flux de collecte se termine lorsqu'un paquet devient disponible. - Une ligne à la fois est ensuite traitée par les opérateurs parents dans la branche A, et finalement jusqu'au client.
- Finalement, les lignes s'épuisent et un
Closeimbriqué l'appel se répercute dans l'arborescence, à travers les échanges, et l'exécution parallèle prend fin.
Résumé et notes finales
Tout d'abord, un résumé de la séquence d'exécution de ce plan d'exécution parallèle particulier :
- La tâche parente ouvre la succursale A . Phase précoce le traitement commence à l'échange de flux de collecte.
- Les appels de la phase initiale de la tâche parent descendent l'arborescence d'analyse jusqu'à la recherche d'index au nœud 9, puis remontent vers l'échange de répartition au nœud 5.
- La tâche parent démarre des tâches parallèles pour la Branche C , puis attend pendant qu'il lit toutes les lignes disponibles dans les opérateurs de tri bloquant au nœud 7.
- Les appels de la première phase montent jusqu'à la jointure de fusion, puis descendent l'entrée interne jusqu'à l'échange au nœud 11.
- Tâches pour la Branche D sont démarrés comme pour la branche C, tandis que la tâche parent attend au nœud 11.
- Les appels de phase précoce reviennent du nœud 11 jusqu'aux flux de collecte. La phase préliminaire se termine ici.
- La tâche parent crée des tâches parallèles pour la Branche B , et attend que l'ouverture de la branche B soit terminée.
- Les tâches de la branche B atteignent les flux de répartition du nœud 5, se synchronisent, terminent l'échange et libèrent les tâches de la branche C pour commencer à agréger les lignes à partir des tris.
- Lorsque les tâches de la branche B atteignent les flux de répartition du nœud 12, elles se synchronisent, terminent l'échange et libèrent les tâches de la branche D pour commencer à agréger les lignes du tri.
- Les tâches de la branche B retournent à l'échange et à la synchronisation des flux de collecte, libérant la tâche parent de son attente. La tâche parent est maintenant prête à démarrer le processus de renvoi des lignes au client.
Vous aimerez peut-être regarder l'exécution de ce plan dans Sentry One Plan Explorer. Assurez-vous d'activer l'option "Avec profil de requête en direct" de la collection Plan réel. L'avantage d'exécuter la requête directement dans Plan Explorer est que vous pourrez parcourir plusieurs captures à votre propre rythme, et même revenir en arrière. Il affichera également un résumé graphique des E/S, du processeur et des attentes synchronisées avec les données de profilage des requêtes en direct.
Remarques supplémentaires
L'ascension de l'arborescence d'analyse des requêtes au cours de la phase initiale de traitement définit les première et dernière heures actives à chaque itérateur de profilage pour la tâche parent, mais n'accumule pas le temps écoulé ou le temps CPU. Remonter l'arbre pendant Open et GetRow appelle une tâche parallèle définit la dernière heure active et accumule le temps écoulé et le temps CPU à chaque itérateur de profilage par tâche.
Le traitement de la phase précoce est spécifique aux plans parallèles en mode ligne. Il faut s'assurer que les échanges sont initialisés dans le bon ordre, et que toutes les machines parallèles fonctionnent correctement.
La tâche parent n'exécute pas toujours l'intégralité du traitement de la phase initiale. Les premières phases commencent à un échange racine, mais la manière dont ces appels naviguent dans l'arborescence dépend des itérateurs rencontrés. J'ai choisi une jointure par fusion pour cette démo car elle nécessite un traitement de phase précoce pour les deux entrées.
Les premières phases (par exemple) d'une jointure de hachage parallèle se propagent uniquement dans l'entrée de construction. Lorsque la jointure de hachage passe à sa phase de test, elle s'ouvre itérateurs sur cette entrée, y compris les échanges. Un autre cycle de traitement de phase précoce est lancé, géré par (exactement) l'une des tâches parallèles, jouant le rôle de la tâche parent.
Lorsque le traitement de la première phase rencontre une branche parallèle contenant un itérateur bloquant, il démarre les tâches parallèles supplémentaires pour cette branche et attend que ces producteurs terminent leur phase d'ouverture. Cette branche peut également avoir des branches enfants, qui sont gérées de la même manière, de manière récursive.
Certaines branches d'un plan parallèle en mode ligne peuvent devoir s'exécuter sur un seul thread (par exemple, en raison d'un agrégat global ou d'un top). Ces "zones série" s'exécutent également sur une tâche "parallèle" supplémentaire, la seule différence étant qu'il n'y a qu'une seule tâche, un seul contexte d'exécution et un seul travailleur pour cette branche. Le traitement de la phase précoce fonctionne de la même manière quel que soit le nombre de tâches affectées à une branche. Par exemple, une « zone série » signale les horaires de la tâche parente (ou d'une tâche parallèle jouant ce rôle) ainsi que de la tâche supplémentaire unique. Cela se manifeste dans showplan sous la forme de données pour "thread 0" (phases précoces) ainsi que "thread 1" (la tâche supplémentaire).
Réflexions finales
Tout cela représente certainement une couche supplémentaire de complexité. Le retour sur cet investissement se traduit par l'utilisation des ressources d'exécution (principalement les threads et la mémoire), la réduction des attentes de synchronisation, l'augmentation du débit, des mesures de performances potentiellement précises et un risque réduit de blocages parallèles intra-requête.
Bien que le parallélisme en mode ligne ait été largement éclipsé par le moteur d'exécution parallèle en mode batch plus moderne, la conception en mode ligne a toujours une certaine beauté. La plupart des itérateurs peuvent prétendre qu'ils fonctionnent toujours dans un plan en série, avec presque toute la synchronisation, le contrôle de flux et la planification gérés par les échanges. Le soin et l'attention évidents dans les détails de mise en œuvre, tels que le traitement en phase précoce, permettent même aux plans parallèles les plus importants de s'exécuter avec succès sans que le concepteur de requêtes ne se préoccupe trop des difficultés pratiques.