Je suis en train de désencombrer ma maison (trop tard en été pour essayer de faire passer ça pour un ménage de printemps). Vous savez, nettoyer les placards, passer en revue les jouets des enfants et organiser le sous-sol. C'est un processus douloureux. Quand nous avons emménagé dans notre maison il y a 10 ans, nous avions TELLEMENT de place. Maintenant, j'ai l'impression qu'il y a des choses partout, et il est plus difficile de trouver ce que je cherche vraiment et cela prend de plus en plus de temps à nettoyer et à organiser.
Cela ressemble-t-il à n'importe quelle base de données que vous gérez ?
De nombreux clients avec lesquels j'ai travaillé traitent de la purge des données après coup. Au moment de la mise en place, tout le monde veut tout sauvegarder. "Nous ne savons jamais quand nous pourrions en avoir besoin." Après un an ou deux, quelqu'un se rend compte qu'il y a beaucoup de choses supplémentaires dans la base de données, mais maintenant les gens ont peur de s'en débarrasser. "Nous devons vérifier avec Legal pour voir si nous pouvons le supprimer." Mais personne ne vérifie avec Legal, ou si quelqu'un le fait, Legal retourne voir les propriétaires de l'entreprise pour demander ce qu'il faut garder, puis le projet s'arrête. "Nous ne pouvons pas parvenir à un consensus sur ce qui peut être supprimé." Le projet est oublié, puis deux ou quatre ans plus tard, la base de données est soudainement d'un téraoctet, difficile à gérer, et les gens attribuent tous les problèmes de performances à la taille de la base de données. Vous entendez les mots "partitionner" et "archiver la base de données", et parfois vous devez simplement supprimer un tas de données, ce qui a ses propres problèmes.
Idéalement, vous devriez décider de votre stratégie de purge avant la mise en œuvre ou dans les six à douze premiers mois suivant la mise en service. Mais puisque nous avons dépassé ce stade, regardons quel impact ces données supplémentaires peuvent avoir.
Méthodologie des tests
Pour préparer le terrain, j'ai pris une copie de la base de données de crédit et l'ai restaurée sur mon instance SQL Server 2012. J'ai supprimé les trois index non cluster existants et ajouté deux des miens :
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
J'ai ensuite augmenté le nombre de lignes dans le tableau à 14,4 millions, en réinsérant plusieurs fois l'ensemble de lignes d'origine, en modifiant légèrement les dates :
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Enfin, j'ai mis en place un harnais de test pour exécuter une série d'instructions sur la base de données quatre fois chacune. Les déclarations sont ci-dessous :
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Avant chaque instruction que j'ai exécutée
DBCC DROPCLEANBUFFERS; GO
pour effacer le pool de mémoire tampon. Évidemment, ce n'est pas quelque chose à exécuter dans un environnement de production. Je l'ai fait ici pour fournir un point de départ cohérent pour chaque test.
Après chaque exécution, j'ai augmenté la taille de la table dbo.charge en insérant les 14,4 millions de lignes avec lesquelles j'avais commencé, mais j'ai augmenté le charge_dt d'un an pour chaque exécution. Par exemple :
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Après l'ajout de 14,4 millions de lignes, j'ai relancé le faisceau de test. J'ai répété cela six fois, en ajoutant essentiellement six "années" de données. La table dbo.charge a commencé avec des données de 1999, et après les insertions répétées, elle contenait des données jusqu'en 2005.
Résultats
Les résultats des exécutions peuvent être consultés ici :
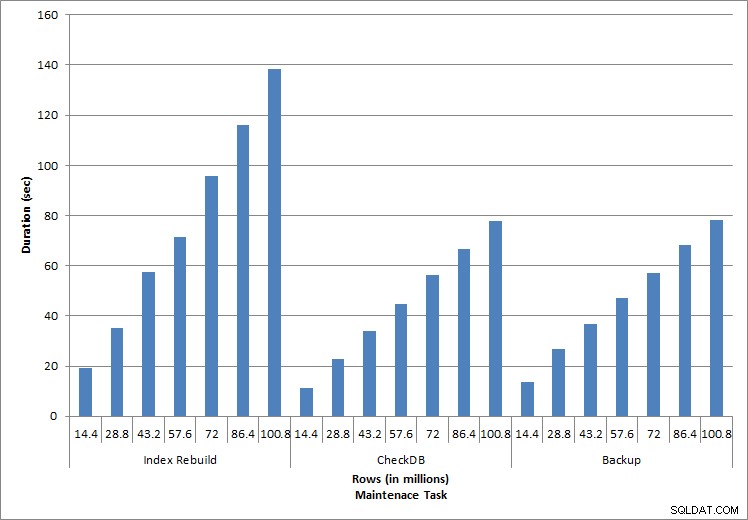
Durée des tâches de maintenance
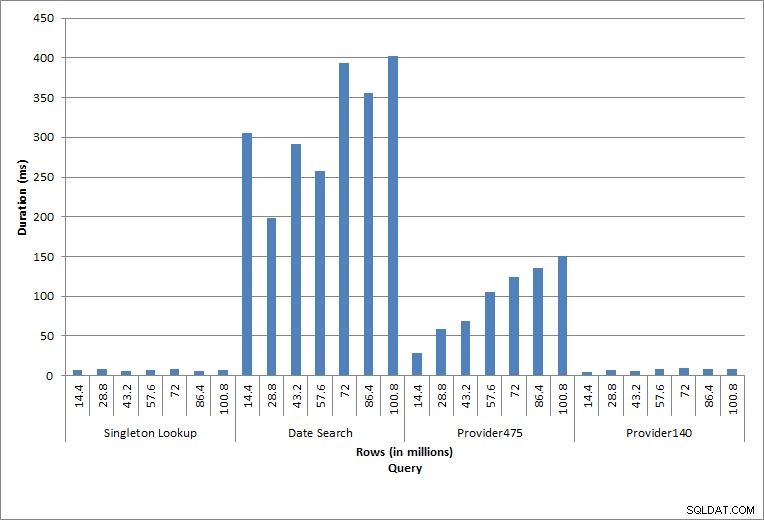
Durée des requêtes
Les instructions individuelles exécutées reflètent l'activité typique de la base de données. Les reconstructions d'index, les vérifications d'intégrité et les sauvegardes font partie de la maintenance régulière de la base de données. Les requêtes sur le tableau des charges représentent une recherche singleton ainsi que trois variantes d'analyses de plage spécifiques aux données du tableau.
Reconstructions d'index, CHECKDB et sauvegardes
Comme prévu pour les tâches de maintenance, la durée et les valeurs d'E/S ont augmenté à mesure que davantage de lignes étaient ajoutées à la base de données. La taille de la base de données a été multipliée par 10 et, bien que les durées n'aient pas augmenté au même rythme, une augmentation constante a été observée. Chaque tâche de maintenance prenait initialement moins de 20 secondes, mais au fur et à mesure que de nouvelles lignes étaient ajoutées, la durée des tâches augmentait à près de 1 minute et 20 secondes pour 100 millions de lignes (et à plus de 2 minutes pour la reconstruction de l'index). Cela reflète le temps supplémentaire requis par SQL Server pour terminer la tâche en raison de données supplémentaires.
Recherche de singleton
La requête contre dbo.charge pour un charge_no spécifique a toujours produit une ligne - et aurait produit une ligne quelle que soit la valeur utilisée, car charge_no est une identité unique. Il existe une variation minimale pour cette recherche. Au fur et à mesure que des lignes sont continuellement ajoutées à la table, l'index peut augmenter en profondeur d'un ou deux niveaux (plus à mesure que la table s'élargit), ajoutant ainsi quelques IO, mais il s'agit d'une recherche singleton avec très peu d'IO.
Balayages de plage
La requête pour une plage de dates (charge_dt) a été modifiée après chaque insertion pour rechercher les données de juillet de l'année la plus récente (par exemple, "2005-07-01" à "2005-07-01" pour la dernière série de tests), mais a renvoyé un peu plus de 1,2 million de lignes à chaque fois. Dans un scénario réel, nous ne nous attendrions pas à ce que le même nombre de lignes soit renvoyé pour le même mois, d'une année sur l'autre, et nous ne nous attendrions pas non plus à ce que le même nombre de lignes soit renvoyé pour chaque mois de l'année. Mais le nombre de lignes pourrait rester dans la même plage d'un mois à l'autre, avec de légères augmentations au fil du temps. Il existe des fluctuations de durée pour cette requête, mais un examen des données d'E/S capturées à partir de sys.dm_io_virtual_file_stats montre une cohérence dans le nombre de lectures.
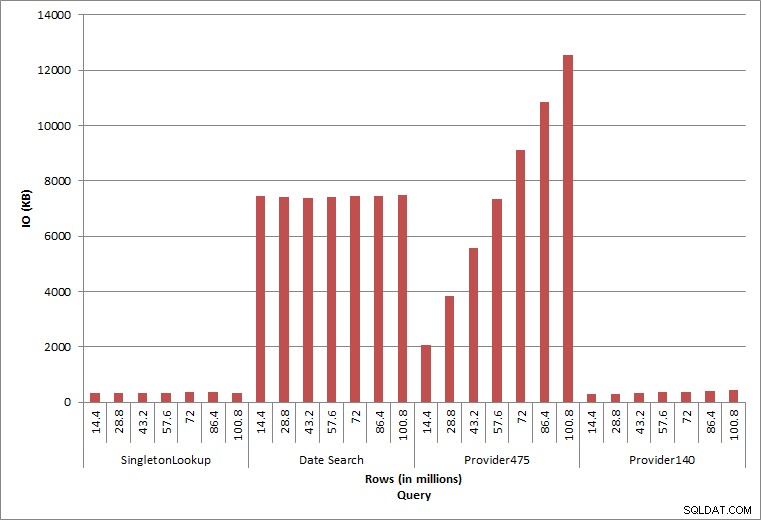
E/S de requête
Les deux dernières requêtes, pour deux valeurs provider_no différentes, montrent le véritable effet de la conservation des données. Dans la table dbo.charge initiale, provider_no 475 comptait plus de 126 000 lignes et provider_no 140 comptait plus de 1 700 lignes. Pour chaque 14,4 millions de lignes ajoutées, environ le même nombre de lignes pour chaque provider_no a été ajouté. Dans un environnement de production, ce type de distribution de données n'est pas rare, et les requêtes pour ces données peuvent bien fonctionner dans les premières années de la solution, mais peuvent se dégrader avec le temps à mesure que d'autres lignes sont ajoutées. La durée de la requête augmente d'un facteur cinq (de 31 ms à 153 ms) entre l'exécution initiale et finale pour provider_no 475. Bien que cet impact puisse ne pas sembler significatif, notez l'augmentation parallèle des E/S (ci-dessus). S'il s'agissait d'une requête exécutée à une fréquence élevée et/ou de requêtes similaires exécutées à une fréquence régulière, la charge supplémentaire peut s'additionner et affecter l'utilisation globale des ressources. En outre, tenez compte de l'impact lorsque vous travaillez avec des tables contenant des milliards de lignes et utilisées dans des requêtes avec des jointures complexes, ainsi que de l'impact sur vos tâches de maintenance régulières et extrêmement critiques. Enfin, tenez compte du temps de récupération. Votre plan de reprise après sinistre doit être basé sur les temps de restauration, et à mesure que la taille de la base de données augmente, la base de données prendra plus de temps à restaurer dans son intégralité. Si vous ne testez pas et ne chronométrez pas régulièrement vos restaurations, la récupération après un sinistre peut prendre plus de temps que prévu.
Résumé
Les exemples présentés ici sont des illustrations simples de ce qui peut se produire lorsqu'une stratégie d'archivage de données n'est pas déterminée lors de la mise en œuvre de la base de données, et il existe de nombreux autres scénarios à explorer et à tester. Les anciennes données auxquelles on accède rarement, voire jamais, n'ont pas seulement un impact sur l'espace disque. Cela peut affecter les performances des requêtes et la durée des tâches de maintenance. En tant que DBA gérant plusieurs bases de données sur une instance, une base de données contenant des données historiques peut affecter les performances et les tâches de maintenance d'autres bases de données. De plus, si les rapports s'exécutent par rapport aux données historiques, cela peut faire des ravages dans un environnement OLTP déjà occupé.
Dès le début, il est essentiel que la durée de vie des données dans une base de données soit déterminée et qu'un plan d'action soit mis en place. Pour certaines solutions, il est nécessaire de conserver toutes les données pour toujours. Dans ce cas, utilisez des stratégies pour maintenir la taille de la base de données gérable, par exemple :archivez régulièrement les données dans une table ou une base de données distincte. Dans le cas où les données n'ont pas besoin d'être stockées pendant des années et des années, mettez en place une stratégie de purge qui supprime les données de manière régulière. De cette manière, vous pouvez jeter les jouets avec lesquels vous ne jouez plus, les vêtements qui ne vous vont plus et les déchets aléatoires que vous n'utilisez tout simplement pas tous les trois mois… plutôt qu'une fois tous les 10 ans.



