Alors que SQL Server sur Linux a volé presque tous les gros titres sur v.Next, il y a d'autres avancées intéressantes à venir dans la prochaine version de notre plate-forme de base de données préférée. Sur le front T-SQL, nous avons enfin un moyen intégré d'effectuer la concaténation de chaînes groupées :STRING_AGG() .
Supposons que nous ayons la structure de table simple suivante :
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL FOREIGN KEY REFERENCES dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
Pour les tests de performances, nous allons remplir ceci en utilisant sys.all_objects et sys.all_columns . Mais pour une démonstration simple, ajoutons d'abord les lignes suivantes :
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'IDClient');
Si les forums sont une indication, il est très courant de renvoyer une ligne pour chaque objet, ainsi qu'une liste de noms de colonnes séparés par des virgules. (Extrapolez cela à tous les types d'entités que vous modélisez de cette façon - noms de produits associés à une commande, noms de pièces impliquées dans l'assemblage d'un produit, subordonnés relevant d'un responsable, etc.) Ainsi, par exemple, avec les données ci-dessus, nous voulez une sortie comme celle-ci :
colonnes d'objet--------- ---------------------------Employés EmployeeID,CurrentStatusOrders OrderID,OrderDate, ID client
La façon dont nous accomplirions cela dans les versions actuelles de SQL Server consiste probablement à utiliser FOR XML PATH , comme je l'ai démontré être le plus efficace en dehors de CLR dans ce post précédent. Dans cet exemple, cela ressemblerait à ceci :
SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML CHEMIN, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Comme on pouvait s'y attendre, nous obtenons la même sortie démontrée ci-dessus. Dans SQL Server v.Next, nous pourrons exprimer cela plus simplement :
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ object_id]GROUPE PAR o.[object_name] ;
Encore une fois, cela produit exactement la même sortie. Et nous avons pu le faire avec une fonction native, en évitant à la fois le coûteux FOR XML PATH l'échafaudage et les STUFF() fonction utilisée pour supprimer la première virgule (cela se produit automatiquement).
Qu'en est-il de la commande ?
L'un des problèmes avec de nombreuses solutions maladroites à la concaténation groupée est que l'ordre de la liste séparée par des virgules doit être considéré comme arbitraire et non déterministe.
Pour le XML PATH solution, j'ai démontré dans un autre article précédent que l'ajout d'un ORDER BY est trivial et garanti. Ainsi, dans cet exemple, nous pourrions classer la liste des colonnes par nom de colonne par ordre alphabétique au lieu de laisser SQL Server le trier (ou non) :
SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c. nom_colonne -- ne changez que FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Sortie :
colonnes d'objet--------- ---------------------------Employés CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, ID de commande
CTP 1.1 ajoute WITHIN GROUP à STRING_AGG() , donc en utilisant la nouvelle approche, nous pouvons dire :
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) -- seulement changeFROM dbo.Objects AS oINNER JOIN dbo. Colonnes AS cON o.[object_id] =c.[object_id]GROUP BY o.[object_name] ;
Maintenant, nous obtenons les mêmes résultats. Notez que, tout comme un ORDER BY normal clause, vous pouvez ajouter plusieurs colonnes ou expressions de classement dans WITHIN GROUP () .
D'accord, les performances sont déjà !
À l'aide de processeurs quad-core 2,6 GHz, de 8 Go de mémoire et de SQL Server CTP1.1 (14.0.100.187), j'ai créé une nouvelle base de données, recréé ces tables et ajouté des lignes à partir de sys.all_objects et sys.all_columns . Je me suis assuré de n'inclure que les objets qui avaient au moins une colonne :
INSERT dbo.Objects([object_id], [object_name]) -- 656 lignes SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FROM sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS ( SELECT 1 FROM sys.all_columns WHERE [object_id] =o.[object_id] ] ); INSERT dbo.Columns([object_id], column_name) -- 8 085 lignes SELECT [object_id], nom FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id] );Sur mon système, cela a donné 656 objets et 8 085 colonnes (votre système peut donner des nombres légèrement différents).
Les plans
Commençons par comparer les plans et les onglets Table I/O pour nos deux requêtes non ordonnées, à l'aide de Plan Explorer. Voici les métriques d'exécution globales :
Métriques d'exécution pour XML PATH (haut) et STRING_AGG() (bas)
Le plan graphique et Table I/O du
FOR XML PATHrequête :
E/S de plan et de table pour XML PATH, pas d'ordre
Et à partir du
STRING_AGGversion :
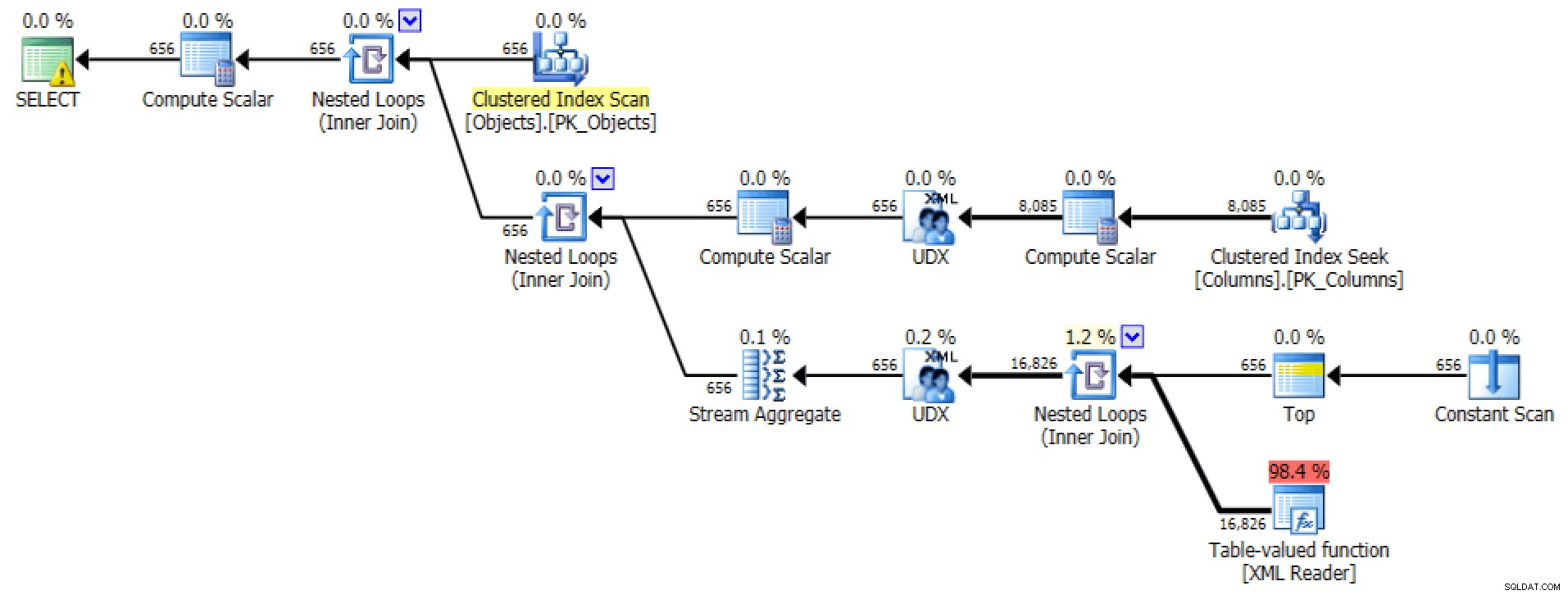
E/S de plan et de table pour STRING_AGG, pas de commande
Pour ce dernier, la recherche d'index clusterisé me semble un peu troublante. Cela semblait être un bon cas pour tester le
FORCESCANrarement utilisé indice (et non, cela n'aiderait certainement pas leFOR XML PATHrequête) :SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- ajout d'un indice ON o .[object_id] =c.[object_id]GROUPER PAR o.[object_name] ;Maintenant, le plan et l'onglet E/S de la table ont l'air beaucoup mieux, du moins à première vue :
E/S de plan et de table pour STRING_AGG(), pas de commande, avec FORCESCAN
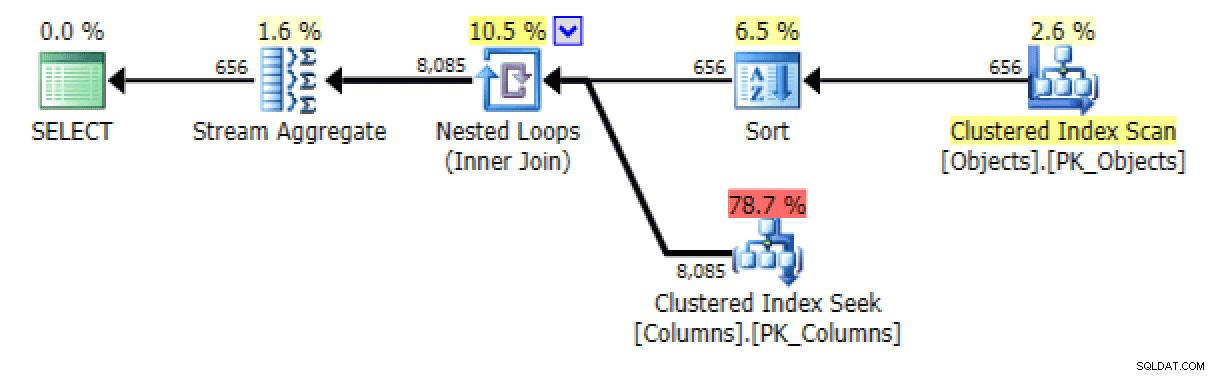
Les versions ordonnées des requêtes génèrent à peu près les mêmes plans. Pour le
FOR XML PATHversion, un tri est ajouté :
Ajout d'un tri dans la version FOR XML PATH
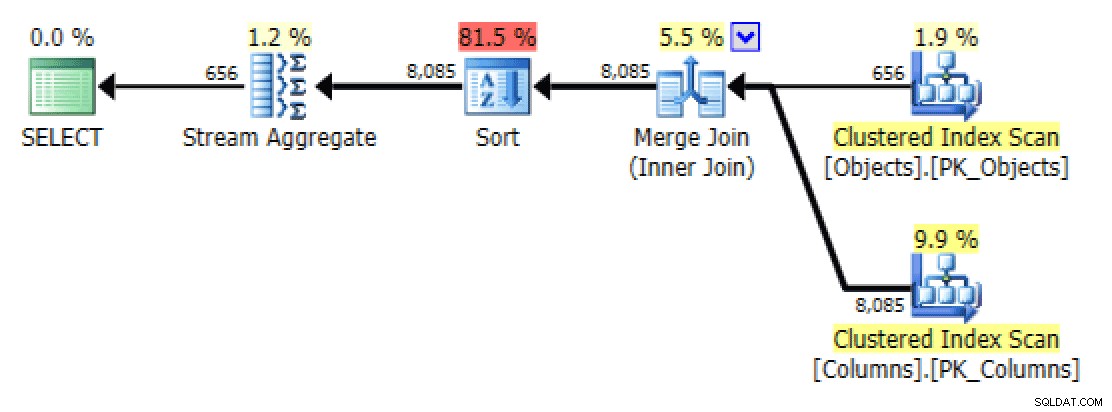
Pour
STRING_AGG(), un scan est choisi dans ce cas, même sans leFORCESCANindice, et aucune opération de tri supplémentaire n'est requise - le plan semble donc identique auFORCESCANversion.À grande échelle
L'examen d'un plan et de métriques d'exécution ponctuelles peut nous donner une idée de si
STRING_AGG()fonctionne mieux que leFOR XML PATHexistant solution, mais un test plus important pourrait avoir plus de sens. Que se passe-t-il lorsque nous effectuons la concaténation groupée 5 000 fois ?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, non ordonné] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value (N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;GO 5000SELECT [for xml path, unordered] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, ordonné] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c.column_name FOR XML PATH , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [for xml path , ordonné] =SYSDATETIME();Après avoir exécuté ce script cinq fois, j'ai fait la moyenne des durées et voici les résultats :
Durée (millisecondes) pour diverses approches de concaténation groupée
Nous pouvons voir que notre
FORCESCANUn indice a vraiment aggravé les choses - alors que nous avons déplacé le coût de la recherche d'index groupé, le tri était en fait bien pire, même si les coûts estimés les jugeaient relativement équivalents. Plus important encore, nous pouvons voir queSTRING_AGG()offre un avantage en termes de performances, que les chaînes concaténées doivent ou non être ordonnées d'une manière spécifique. Comme avecSTRING_SPLIT(), que j'ai examiné en mars, je suis assez impressionné par le fait que cette fonction évolue bien avant la "v1".J'ai d'autres tests prévus, peut-être pour un prochain article :
- Lorsque toutes les données proviennent d'une seule table, avec et sans index prenant en charge le tri
- Tests de performances similaires sous Linux
En attendant, si vous avez des cas d'utilisation spécifiques pour la concaténation groupée, veuillez les partager ci-dessous (ou envoyez-moi un e-mail à abertrand@sentryone.com). Je suis toujours prêt à m'assurer que mes tests sont aussi réalistes que possible.



