[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]
Beaucoup a été écrit au fil des ans sur la compréhension et l'optimisation de SELECT requêtes, mais plutôt moins sur la modification des données. Cette série d'articles examine un problème spécifique à INSERT , UPDATE , DELETE et MERGE requêtes – le problème d'Halloween.
L'expression "Problème d'Halloween" a été inventée à l'origine en référence à un SQL UPDATE requête qui était censée accorder une augmentation de 10 % à chaque employé qui gagnait moins de 25 000 $. Le problème était que la requête continuait à donner des augmentations de 10 % jusqu'à ce que tout le monde gagné au moins 25 000 $. Nous verrons plus tard dans cette série que le problème sous-jacent s'applique également à INSERT , DELETE et MERGE requêtes, mais pour cette première entrée, il sera utile d'examiner le UPDATE problème dans un peu de détail.
Contexte
Le langage SQL permet aux utilisateurs de spécifier les modifications de la base de données à l'aide d'un UPDATE déclaration, mais la syntaxe ne dit rien sur comment le moteur de base de données doit effectuer les modifications. Par contre, le standard SQL précise que le résultat d'un UPDATE doit être le même que s'il avait été exécuté en trois phases distinctes et non superposées :
- Une recherche en lecture seule détermine les enregistrements à modifier et les nouvelles valeurs de colonne
- Les modifications sont appliquées aux enregistrements concernés
- Les contraintes de cohérence de la base de données sont vérifiées
L'implémentation littérale de ces trois phases dans un moteur de base de données produirait des résultats corrects, mais les performances pourraient ne pas être très bonnes. Les résultats intermédiaires à chaque étape nécessiteront de la mémoire système, ce qui réduira le nombre de requêtes que le système peut exécuter simultanément. La mémoire requise peut également dépasser celle qui est disponible, ce qui nécessite qu'au moins une partie de l'ensemble de mises à jour soit écrite sur le stockage sur disque et relue ultérieurement. Enfin, chaque ligne du tableau doit être touchée plusieurs fois sous ce modèle d'exécution.
Une autre stratégie consiste à traiter le UPDATE une rangée à la fois. Cela a l'avantage de ne toucher qu'une seule fois chaque ligne et ne nécessite généralement pas de mémoire pour le stockage (bien que certaines opérations, comme un tri complet, doivent traiter l'ensemble d'entrées complet avant de produire la première ligne de sortie). Ce modèle itératif est celui utilisé par le moteur d'exécution des requêtes SQL Server.
Le défi pour l'optimiseur de requête est de trouver un plan d'exécution itératif (ligne par ligne) qui satisfait le UPDATE sémantique requise par la norme SQL, tout en conservant les avantages de performances et de simultanéité de l'exécution en pipeline.
Traitement de la mise à jour
Pour illustrer le problème initial, nous appliquerons une augmentation de 10 % à chaque employé gagnant moins de 25 000 $ en utilisant le Employees tableau ci-dessous :

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Stratégie de mise à jour en trois phases
La première phase en lecture seule trouve tous les enregistrements qui répondent au WHERE prédicat de clause et enregistre suffisamment d'informations pour que la deuxième phase puisse faire son travail. En pratique, cela signifie enregistrer un identifiant unique pour chaque ligne qualifiante (les clés d'index groupées ou l'identifiant de ligne de tas) et la nouvelle valeur de salaire. Une fois la première phase terminée, l'ensemble des informations de mise à jour est transmis à la deuxième phase, qui localise chaque enregistrement à mettre à jour à l'aide de l'identifiant unique et modifie le salaire à la nouvelle valeur. La troisième phase vérifie ensuite qu'aucune contrainte d'intégrité de la base de données n'est violée par l'état final de la table.
Stratégie itérative
Cette approche lit une ligne à la fois dans la table source. Si la ligne satisfait le WHERE clause prédicat, l'augmentation de salaire est appliquée. Ce processus se répète jusqu'à ce que toutes les lignes aient été traitées à partir de la source. Un exemple de plan d'exécution utilisant ce modèle est présenté ci-dessous :

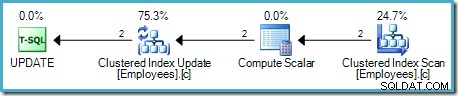
Comme d'habitude pour le pipeline piloté par la demande de SQL Server, l'exécution commence à l'opérateur le plus à gauche - le UPDATE dans ce cas. Il demande une ligne à la mise à jour de la table, qui demande une ligne au scalaire de calcul, et descend la chaîne jusqu'à l'analyse de la table :
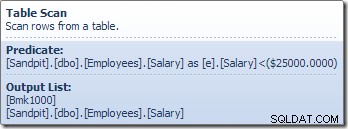
L'opérateur Table Scan lit les lignes une par une à partir du moteur de stockage, jusqu'à ce qu'il en trouve une qui satisfasse le prédicat Salary. La liste de sortie dans le graphique ci-dessus montre l'opérateur Table Scan renvoyant un identifiant de ligne et la valeur actuelle de la colonne Salaire pour cette ligne. Une seule ligne contenant des références à ces deux informations est transmise au scalaire de calcul :
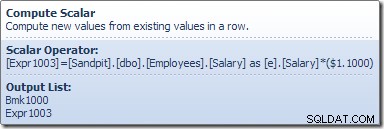
Le scalaire de calcul définit une expression qui applique l'augmentation de salaire à la ligne actuelle. Il renvoie une ligne contenant des références à l'identifiant de ligne et au salaire modifié à la mise à jour de la table, qui appelle le moteur de stockage pour effectuer la modification des données. Ce processus itératif se poursuit jusqu'à ce que l'analyse de table soit à court de lignes. Le même processus de base est suivi si la table a un index cluster :
La principale différence est que la ou les clés d'index cluster et l'unificateur (le cas échéant) sont utilisés comme identifiant de ligne au lieu d'un RID de tas.
Le problème
Le passage de l'opération logique en trois phases définie dans la norme SQL au modèle physique d'exécution itérative a introduit un certain nombre de changements subtils, dont nous n'aborderons qu'un seul aujourd'hui. Un problème peut survenir dans notre exemple en cours d'exécution s'il existe un index non clusterisé sur la colonne Salary, que l'optimiseur de requête décide d'utiliser pour trouver des lignes éligibles (Salary < 25 000 $) :
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Le modèle d'exécution ligne par ligne peut désormais produire des résultats incorrects, voire entrer dans une boucle infinie. Considérez un plan d'exécution itératif (imaginaire) qui recherche l'indice de salaire, renvoyant une ligne à la fois au scalaire de calcul, et finalement à l'opérateur de mise à jour :

Il y a quelques scalaires de calcul supplémentaires dans ce plan en raison d'une optimisation qui ignore la maintenance de l'index non clusterisé si la valeur du salaire n'a pas changé (uniquement possible pour un salaire nul dans ce cas).
Ignorant cela, la caractéristique importante de ce plan est que nous avons maintenant une analyse d'index partiel ordonné passant une ligne à la fois à un opérateur qui modifie le même index (la surbrillance verte dans le graphique SQL Sentry Plan Explorer ci-dessus indique clairement le Clustered L'opérateur de mise à jour d'index maintient à la fois la table de base et l'index non clusterisé).
Quoi qu'il en soit, le problème est qu'en traitant une ligne à la fois, la mise à jour peut déplacer la ligne actuelle devant la position de balayage utilisée par la recherche d'index pour localiser les lignes à modifier. L'examen de l'exemple devrait rendre cette déclaration un peu plus claire :
L'index non clusterisé est indexé et trié par ordre croissant sur la valeur du salaire. L'index contient également un pointeur vers la ligne parente dans la table de base (soit un RID de tas, soit les clés d'index groupées plus l'unificateur si nécessaire). Pour rendre l'exemple plus facile à suivre, supposons que la table de base a maintenant un index clusterisé unique sur la colonne Nom, donc le contenu de l'index non clusterisé au début du traitement de la mise à jour est :
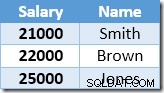
La première ligne renvoyée par Index Seek est le salaire de 21 000 $ de Smith. Cette valeur est mise à jour à 23 100 $ dans la table de base et l'index non clusterisé par l'opérateur Clustered Index. L'index non-cluster contient désormais :
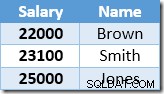
La ligne suivante renvoyée par Index Seek sera l'entrée de 22 000 $ pour Brown, qui est mise à jour à 24 200 $ :
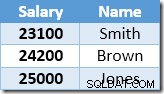
Maintenant, Index Seek trouve la valeur de 23 100 $ pour Smith, qui est mise à jour à nouveau , à 25 410 $. Ce processus se poursuit jusqu'à ce que tous les employés aient un salaire d'au moins 25 000 USD - ce qui n'est pas un résultat correct pour la UPDATE donnée. requête. Le même effet dans d'autres circonstances peut conduire à une mise à jour incontrôlable qui ne se termine que lorsque le serveur manque d'espace de journalisation ou qu'une erreur de débordement se produit (cela pourrait se produire dans ce cas si quelqu'un avait un salaire nul). C'est le problème d'Halloween tel qu'il s'applique aux mises à jour.
Éviter le problème d'Halloween pour les mises à jour
Les lecteurs aux yeux d'aigle auront remarqué que les pourcentages de coût estimés dans le plan imaginaire Index Seek ne totalisaient pas 100 %. Ce n'est pas un problème avec Plan Explorer - j'ai délibérément supprimé un opérateur clé du plan :

L'optimiseur de requêtes reconnaît que ce plan de mise à jour en pipeline est vulnérable au problème d'Halloween et introduit un spool de table impatient pour l'empêcher de se produire. Il n'y a pas d'indication ou d'indicateur de trace pour empêcher l'inclusion du spool dans ce plan d'exécution car il est requis pour l'exactitude.
Comme son nom l'indique, le spool consomme avec impatience toutes les lignes de son opérateur enfant (Index Seek) avant de renvoyer une ligne à son parent Compute Scalar. Cela a pour effet d'introduire une séparation de phases complète – toutes les lignes éligibles sont lues et enregistrées dans un stockage temporaire avant toute mise à jour.
Cela nous rapproche de la sémantique logique en trois phases de la norme SQL, mais veuillez noter que l'exécution du plan est toujours fondamentalement itérative, avec des opérateurs à droite du spool formant le curseur de lecture , et les opérateurs à gauche formant le curseur d'écriture . Le contenu du spool est toujours lu et traité ligne par ligne (il n'est pas passé en masse comme la comparaison avec le standard SQL pourrait autrement vous le faire croire).
Les inconvénients de la séparation de phase sont les mêmes que ceux mentionnés précédemment. Le spool de table consomme tempdb espace (pages dans le pool de mémoire tampon) et peut nécessiter des lectures et des écritures physiques sur le disque sous la pression de la mémoire. L'optimiseur de requête attribue un coût estimé au spool (sous réserve de toutes les mises en garde habituelles concernant les estimations) et choisira entre les plans qui nécessitent une protection contre le problème d'Halloween et ceux qui ne le font pas sur la base du coût estimé comme d'habitude. Naturellement, l'optimiseur peut mal choisir entre les options pour l'une des raisons normales.
Dans ce cas, le compromis est entre l'augmentation de l'efficacité en recherchant directement les enregistrements éligibles (ceux avec un salaire <25 000 $) par rapport au coût estimé de la bobine nécessaire pour éviter le problème d'Halloween. Un plan alternatif (dans ce cas précis) est une analyse complète de l'index clusterisé (ou tas). Cette stratégie ne nécessite pas la même protection Halloween car les clés de l'index clusterisé ne sont pas modifiés :

Comme les clés d'index sont stables, les lignes ne peuvent pas changer de position dans l'index entre les itérations, ce qui évite le problème d'Halloween dans le cas présent. En fonction du coût d'exécution de l'analyse d'index clusterisé par rapport à la combinaison Index Seek plus Eager Table Spool vue précédemment, un plan peut s'exécuter plus rapidement que l'autre. Une autre considération est que le plan avec Halloween Protection acquerra plus de verrous que le plan entièrement en pipeline, et les verrous seront conservés plus longtemps.
Réflexions finales
Comprendre le problème d'Halloween et les effets qu'il peut avoir sur les plans de requête de modification des données vous aidera à analyser les plans d'exécution de modification des données et peut offrir des opportunités pour éviter les coûts et les effets secondaires d'une protection inutile lorsqu'une alternative est disponible.
Il existe plusieurs formes du problème d'Halloween, qui ne sont pas toutes causées par la lecture et l'écriture sur les clés d'un index commun. Le problème d'Halloween ne se limite pas non plus à UPDATE requêtes. L'optimiseur de requête a plus d'astuces dans sa manche pour éviter le problème d'Halloween en dehors de la séparation de phase par force brute à l'aide d'un Eager Table Spool. Ces points (et bien d'autres) seront explorés dans les prochains épisodes de cette série.
[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]