[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]
Le MERGE (introduite dans SQL Server 2008) nous permet d'effectuer un mélange de INSERTs , UPDATE , et DELETE opérations à l'aide d'une seule instruction. Les problèmes de protection d'Halloween pour MERGE sont principalement une combinaison des exigences des opérations individuelles, mais il existe quelques différences importantes et quelques optimisations intéressantes qui ne s'appliquent qu'à MERGE .
Éviter le problème d'Halloween avec MERGE
Nous commençons par examiner à nouveau l'exemple de démonstration et de mise en scène de la deuxième partie :
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Comme vous vous en souvenez peut-être, cet exemple a été utilisé pour montrer qu'un INSERTs nécessite la protection Halloween lorsque la table cible d'insertion est également référencée dans le SELECT partie de la requête (le EXISTS clause dans ce cas). Le comportement correct pour le INSERTs la déclaration ci-dessus est d'essayer d'ajouter les deux 1234 valeurs, et par conséquent échouer avec une PRIMARY KEY violation. Sans séparation de phases, le INSERTs ajouterait incorrectement une valeur, se terminant sans qu'une erreur ne soit renvoyée.
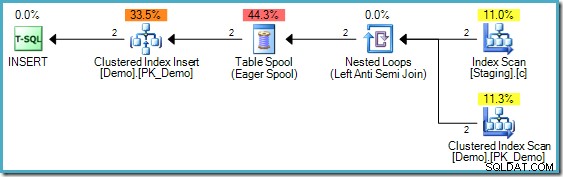
Le plan d'exécution INSERT
Le code ci-dessus présente une différence par rapport à celui utilisé dans la deuxième partie ; un index non clusterisé sur la table Staging a été ajouté. Le INSERTs plan d'exécution toujours nécessite cependant la protection d'Halloween :
Le plan d'exécution MERGE
Essayez maintenant la même insertion logique exprimée en utilisant MERGE syntaxe :
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Si vous n'êtes pas familier avec la syntaxe, la logique consiste à comparer les lignes des tables Staging et Demo sur la valeur SomeKey, et si aucune ligne correspondante n'est trouvée dans la table cible (Demo), nous insérons une nouvelle ligne. Cela a exactement la même sémantique que le précédent INSERT...WHERE NOT EXISTS coder, bien sûr. Le plan d'exécution est cependant assez différent :
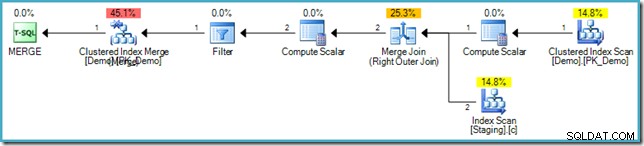
Remarquez l'absence d'une bobine de table Eager dans ce plan. Malgré cela, la requête produit toujours le message d'erreur correct. Il semble que SQL Server ait trouvé un moyen d'exécuter le MERGE planifier de manière itérative en respectant la séparation logique des phases exigée par la norme SQL.
L'optimisation du remplissage des trous
Dans les bonnes circonstances, l'optimiseur SQL Server peut reconnaître que le MERGE l'énoncé est plein de trous , ce qui est juste une autre façon de dire que l'instruction n'ajoute que des lignes là où il existe un écart existant dans la clé de la table cible.
Pour que cette optimisation soit appliquée, les valeurs utilisées dans le WHEN NOT MATCHED BY TARGET la clause doit exactement correspondre au ON partie de USING clause. De plus, la table cible doit avoir une clé unique (une exigence satisfaite par la PRIMARY KEY dans le cas présent). Lorsque ces exigences sont remplies, le MERGE déclaration ne nécessite pas de protection contre le problème d'Halloween.
Bien sûr, le MERGE l'instruction est logique pas plus ou moins de remplissage de trous que l'original INSERT...WHERE NOT EXISTS syntaxe. La différence est que l'optimiseur a un contrôle total sur la mise en œuvre de la MERGE alors que l'instruction INSERTs la syntaxe l'obligerait à raisonner sur la sémantique plus large de la requête. Un humain peut facilement voir que le INSERTs remplit également les trous, mais l'optimiseur ne pense pas les choses de la même manière que nous.
Pour illustrer la correspondance exacte exigence que j'ai mentionnée, considérez la syntaxe de requête suivante, qui ne le fait pas bénéficier de l'optimisation du remplissage des trous. Le résultat est une protection Halloween complète fournie par une bobine de table Eager :
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

La seule différence est la multiplication par un dans les VALUES clause - quelque chose qui ne change pas la logique de la requête, mais qui est suffisant pour empêcher l'application de l'optimisation de remplissage des trous.
Remplissage de trous avec des boucles imbriquées
Dans l'exemple précédent, l'optimiseur a choisi de joindre les tables à l'aide d'une jointure par fusion. L'optimisation du remplissage des trous peut également être appliquée lorsqu'une jointure Nested Loops est choisie, mais cela nécessite une garantie d'unicité supplémentaire sur la table source et une recherche d'index sur le côté interne de la jointure. Pour voir cela en action, nous pouvons effacer les données de staging existantes, ajouter un caractère unique à l'index non clusterisé et essayer le MERGE encore :
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Le plan d'exécution résultant utilise à nouveau l'optimisation du remplissage des trous pour éviter la protection d'Halloween, en utilisant une jointure de boucles imbriquées et une recherche interne dans la table cible :
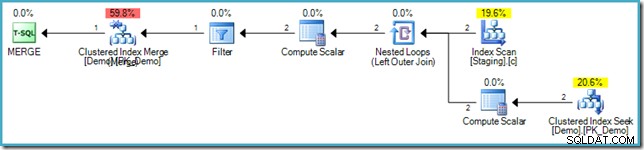
Éviter les parcours d'index inutiles
Lorsque l'optimisation de remplissage de trous s'applique, le moteur peut également appliquer une autre optimisation. Il peut se souvenir de la position actuelle de l'index lors de la lecture la table cible (traitant une ligne à la fois, rappelez-vous) et réutilisez ces informations lors de l'insertion, au lieu de rechercher l'emplacement de l'insertion dans le b-tree. Le raisonnement est que la position de lecture actuelle est très susceptible d'être sur la même page où la nouvelle ligne doit être insérée. Vérifier que la ligne appartient bien à cette page est très rapide, puisqu'il s'agit de ne vérifier que les clés les plus basses et les plus hautes qui y sont actuellement stockées.
La combinaison de l'élimination du spool de table Eager et de l'enregistrement d'une navigation d'index par ligne peut offrir un avantage significatif dans les charges de travail OLTP, à condition que le plan d'exécution soit extrait du cache. Le coût de compilation pour MERGE instructions est plutôt plus élevé que pour INSERTs , UPDATE et DELETE , la réutilisation du plan est donc une considération importante. Il est également utile de s'assurer que les pages disposent de suffisamment d'espace libre pour accueillir de nouvelles lignes, en évitant les fractionnements de page. Ceci est généralement réalisé grâce à la maintenance normale de l'index et à l'attribution d'un FILLFACTOR approprié .
Je mentionne les charges de travail OLTP, qui comportent généralement un grand nombre de changements relativement petits, car le MERGE les optimisations peuvent ne pas être un bon choix lorsqu'un grand nombre de lignes sont traitées par instruction. D'autres optimisations comme les INSERTs à journalisation minimale ne peut actuellement pas être combiné avec le remplissage des trous. Comme toujours, les caractéristiques de performance doivent être comparées pour s'assurer que les avantages attendus sont réalisés.
L'optimisation du remplissage des trous pour MERGE les insertions peuvent être combinées avec des mises à jour et des suppressions à l'aide de MERGE supplémentaires clauses ; chaque opération de modification de données est évaluée séparément pour le problème d'Halloween.
Éviter la jointure
L'optimisation finale que nous examinerons peut être appliquée là où le MERGE L'instruction contient des opérations de mise à jour et de suppression ainsi qu'une insertion de remplissage de trous, et la table cible a un index clusterisé unique. L'exemple suivant montre un MERGE commun modèle dans lequel les lignes sans correspondance sont insérées et les lignes correspondantes sont mises à jour ou supprimées en fonction d'une condition supplémentaire :
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
Le MERGE l'instruction requise pour effectuer toutes les modifications requises est remarquablement compacte :
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Le plan d'exécution est assez surprenant :

Pas de protection Halloween, pas de jointure entre les tables source et cible, et ce n'est pas souvent que vous verrez un opérateur d'insertion d'index clusterisé suivi d'une fusion d'index clusterisé vers la même table. Il s'agit d'une autre optimisation ciblée sur les charges de travail OLTP avec une réutilisation élevée des plans et une indexation appropriée.
L'idée est de lire une ligne de la table source et d'essayer immédiatement de l'insérer dans la cible. Si une violation de clé se produit, l'erreur est supprimée, l'opérateur d'insertion génère la ligne en conflit qu'il a trouvée, et cette ligne est ensuite traitée pour une opération de mise à jour ou de suppression à l'aide de l'opérateur de plan de fusion comme d'habitude.
Si l'insertion d'origine réussit (sans violation de clé), le traitement se poursuit avec la ligne suivante à partir de la source (l'opérateur Merge traite uniquement les mises à jour et les suppressions). Cette optimisation profite principalement à MERGE les requêtes où la plupart des lignes source aboutissent à une insertion. Encore une fois, une analyse comparative minutieuse est nécessaire pour s'assurer que les performances sont meilleures que l'utilisation d'instructions séparées.
Résumé
Le MERGE offre plusieurs possibilités d'optimisation uniques. Dans les bonnes circonstances, cela peut éviter d'avoir à ajouter une protection Halloween explicite par rapport à un équivalent INSERTs opération, ou peut-être même une combinaison de INSERTs , UPDATE , et DELETE déclarations. MERGE supplémentaire -des optimisations spécifiques peuvent éviter la traversée de l'index b-tree qui est généralement nécessaire pour localiser la position d'insertion d'une nouvelle ligne, et peut également éviter d'avoir à joindre complètement les tables source et cible.
Dans la dernière partie de cette série, nous examinerons comment l'optimiseur de requête raisonne sur la nécessité d'une protection Halloween et identifierons d'autres astuces qu'il peut utiliser pour éviter d'avoir à ajouter des spools de table impatients aux plans d'exécution qui modifient les données.
[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]



