Conservez-vous toujours la conception parent/enfant ou souhaitez-vous essayer quelque chose de nouveau, comme l'ID de hiérarchie SQL Server ? Eh bien, c'est vraiment nouveau car hierarchieID fait partie de SQL Server depuis 2008. Bien sûr, la nouveauté elle-même n'est pas un argument convaincant. Mais notez que Microsoft a ajouté cette fonctionnalité pour mieux représenter les relations un-à-plusieurs avec plusieurs niveaux.
Vous vous demandez peut-être quelle différence cela fait et quels avantages vous tirez de l'utilisation de l'ID de hiérarchie au lieu des relations parent/enfant habituelles. Si vous n'avez jamais exploré cette option, cela pourrait vous surprendre.
La vérité est que je n'ai pas exploré cette option depuis sa sortie. Cependant, quand je l'ai finalement fait, j'ai trouvé que c'était une grande innovation. C'est un code plus beau, mais il contient beaucoup plus. Dans cet article, nous allons découvrir toutes ces excellentes opportunités.
Cependant, avant de nous plonger dans les particularités de l'utilisation de l'ID de hiérarchie SQL Server, clarifions sa signification et sa portée.
Qu'est-ce que SQL Server HierarchyID ?
L'ID de hiérarchie SQL Server est un type de données intégré conçu pour représenter des arborescences, qui sont le type le plus courant de données hiérarchiques. Chaque élément d'un arbre est appelé un nœud. Dans un format de tableau, il s'agit d'une ligne avec une colonne de type de données hierarchieID.
Habituellement, nous démontrons les hiérarchies en utilisant une conception de table. Une colonne ID représente un nœud et une autre colonne représente le parent. Avec SQL Server HierarchyID, nous n'avons besoin que d'une colonne avec un type de données de hierarchyID.
Lorsque vous interrogez une table avec une colonne hierarchyID, vous voyez des valeurs hexadécimales. C'est l'une des images visuelles d'un nœud. Une autre façon est une chaîne :
‘/’ représente le nœud racine ;
‘/1/’, ‘/2/’, ‘/3/’ ou ‘/n/’ représentent les enfants – descendants directs 1 à n ;
‘/1/1/’ ou ‘/1/2/’ sont les « enfants d’enfants – « petits-enfants ». La chaîne comme ‘/1/2/’ signifie que le premier enfant de la racine a deux enfants, qui sont, à leur tour, deux petits-enfants de la racine.
Voici un exemple de ce à quoi cela ressemble :
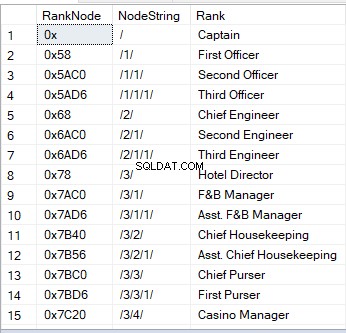
Contrairement à d'autres types de données, les colonnes de l'ID de hiérarchie peuvent tirer parti des méthodes intégrées. Par exemple, si vous avez une colonne hierarchieID nommée RankNode , vous pouvez avoir la syntaxe suivante :
RankNode.
Méthodes SQL Server HierarchyID
L'une des méthodes disponibles est IsDescendantOf . Il renvoie 1 si le nœud actuel est un descendant d'une valeur hierarchieID.
Vous pouvez écrire du code avec cette méthode similaire à celle ci-dessous :
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Les autres méthodes utilisées avec l'ID de hiérarchie sont les suivantes :
- GetRoot – la méthode statique qui renvoie la racine de l'arborescence.
- GetDescendant :renvoie un nœud enfant d'un parent.
- GetAncestor - renvoie un hierarchieID représentant le nième ancêtre d'un nœud donné.
- GetLevel - renvoie un entier qui représente la profondeur du nœud.
- ToString - renvoie la chaîne avec la représentation logique d'un nœud. ToString est appelé implicitement lorsque la conversion de hierarchieID en type chaîne se produit.
- GetReparentedValue - déplace un nœud de l'ancien parent vers le nouveau parent.
- Parse - agit comme l'opposé de ToString . Il convertit la vue chaîne d'un hierarchyID valeur en hexadécimal.
Stratégies d'indexation SQL Server HierarchyID
Pour vous assurer que les requêtes pour les tables utilisant l'ID de hiérarchie s'exécutent aussi rapidement que possible, vous devez indexer la colonne. Il existe deux stratégies d'indexation :
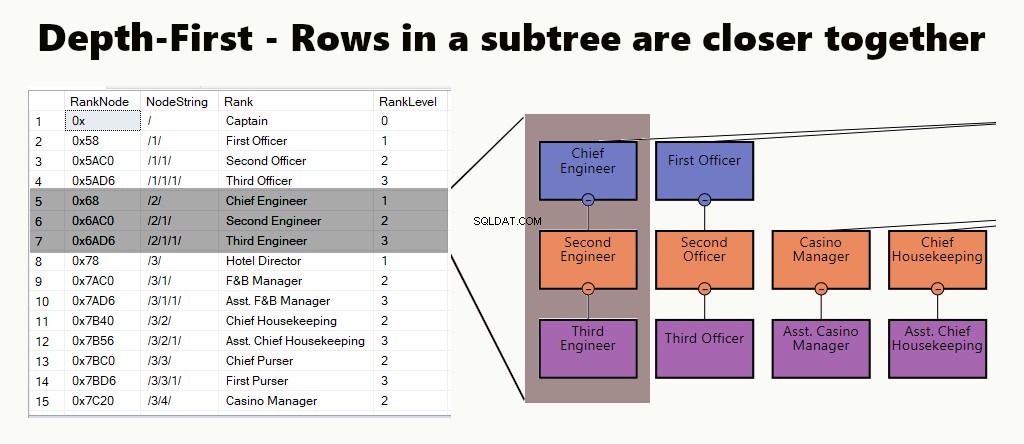
EN PROFONDEUR EN PREMIER
Dans un index de profondeur d'abord, les lignes de sous-arbre sont plus proches les unes des autres. Il convient aux requêtes telles que la recherche d'un service, de ses sous-unités et de ses employés. Un autre exemple est un gestionnaire et ses employés stockés plus près les uns des autres.
Dans une table, vous pouvez implémenter un index de profondeur d'abord en créant un index clusterisé pour les nœuds. De plus, nous exécutons un de nos exemples, juste comme ça.
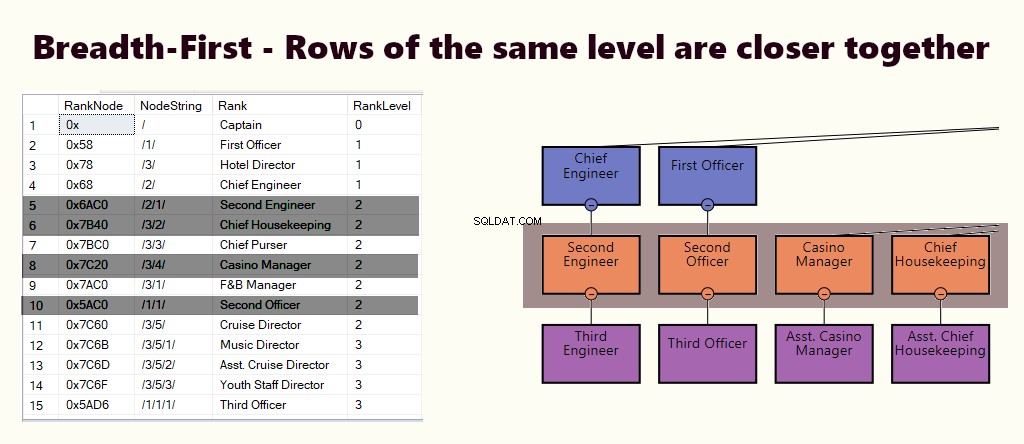
LA LARGE D'ABORD
Dans un index en largeur d'abord, les lignes d'un même niveau sont plus rapprochées. Il convient à des requêtes telles que la recherche de tous les employés directement hiérarchiques du responsable. Si la plupart des requêtes sont similaires à celle-ci, créez un index clusterisé basé sur (1) le niveau et (2) le nœud.
Cela dépend de vos besoins si vous avez besoin d'un index de profondeur d'abord, d'un index de largeur d'abord, ou des deux. Vous devez équilibrer l'importance du type de requêtes et les instructions DML que vous exécutez sur la table.
Limitations de SQL Server HierarchyID
Malheureusement, l'utilisation de l'ID de hiérarchie ne peut pas résoudre tous les problèmes :
- SQL Server ne peut pas deviner ce qu'est l'enfant d'un parent. Vous devez définir l'arborescence dans le tableau.
- Si vous n'utilisez pas de contrainte d'unicité, la valeur de l'ID de hiérarchie généré ne sera pas unique. La gestion de ce problème relève de la responsabilité du développeur.
- Les relations entre un nœud parent et un nœud enfant ne sont pas appliquées comme une relation de clé étrangère. Par conséquent, avant de supprimer un nœud, recherchez tous les descendants existants.
Visualiser les hiérarchies
Avant de continuer, considérons une autre question. En regardant le jeu de résultats avec les chaînes de nœuds, trouvez-vous la hiérarchie difficile à visualiser ?
Pour moi, c'est un grand oui car je ne rajeunis pas.
Pour cette raison, nous allons utiliser Power BI et Hierarchy Chart d'Akvelon avec nos tables de base de données. Ils aideront à afficher la hiérarchie dans un organigramme. J'espère que cela facilitera la tâche.
Passons maintenant aux choses sérieuses.
Utilisations de SQL Server HierarchyID
Vous pouvez utiliser HierarchyID avec les scénarios commerciaux suivants :
- Structure organisationnelle
- Dossiers, sous-dossiers et fichiers
- Tâches et sous-tâches d'un projet
- Pages et sous-pages d'un site Web
- Données géographiques avec pays, régions et villes
Même si votre scénario d'entreprise est similaire à celui ci-dessus et que vous effectuez rarement des requêtes dans les sections de la hiérarchie, vous n'avez pas besoin de l'ID de hiérarchie.
Par exemple, votre organisation traite les paies des employés. Avez-vous besoin d'accéder à la sous-arborescence pour traiter la paie de quelqu'un ? Pas du tout. Cependant, si vous traitez des commissions de personnes dans un système de marketing à plusieurs niveaux, cela peut être différent.
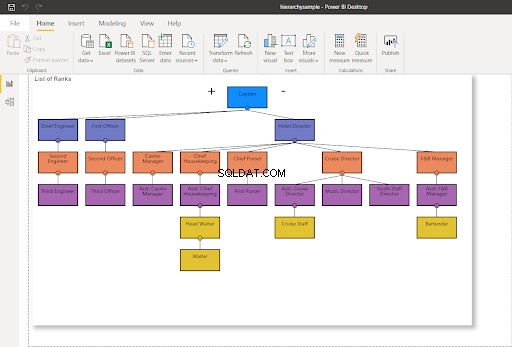
Dans cet article, nous utilisons la partie de la structure organisationnelle et de la chaîne de commandement sur un navire de croisière. La structure a été adaptée de l'organigramme d'ici. Jetez-y un coup d'œil dans la figure 4 ci-dessous :

Vous pouvez maintenant visualiser la hiérarchie en question. Nous utilisons les tableaux ci-dessous tout au long de cet article :
- Navires – est le tableau représentant la liste des navires de croisière.
- Classements – est le tableau des grades d'équipage. Là, nous établissons des hiérarchies à l'aide de l'ID de hiérarchie.
- Équipage – est la liste de l'équipage de chaque navire et leurs grades.
La structure du tableau de chaque cas est la suivante :
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOInsérer des données de table avec SQL Server HierarchyID
La première tâche dans l'utilisation approfondie de l'ID de hiérarchie consiste à ajouter des enregistrements dans la table avec un ID de hiérarchie colonne. Il y a deux façons de le faire.
Utiliser des chaînes
Le moyen le plus rapide d'insérer des données avec l'ID de hiérarchie consiste à utiliser des chaînes. Pour voir cela en action, ajoutons quelques enregistrements aux rangs tableau.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Le code ci-dessus ajoute 20 enregistrements à la table Ranks.
Comme vous pouvez le voir, l'arborescence a été définie dans le INSERT déclaration ci-dessus. Il est discernable facilement lorsque nous utilisons des chaînes. De plus, SQL Server le convertit en valeurs hexadécimales correspondantes.
Utilisation de Max(), GetAncestor() et GetDescendant()
L'utilisation de chaînes convient à la tâche de remplissage des données initiales. À long terme, vous avez besoin que le code gère l'insertion sans fournir de chaînes.
Pour effectuer cette tâche, récupérez le dernier nœud utilisé par un parent ou un ancêtre. Nous l'accomplissons en utilisant les fonctions MAX() et GetAncestor() . Voir l'exemple de code ci-dessous :
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Voici les points tirés du code ci-dessus :
- Tout d'abord, vous avez besoin d'une variable pour le dernier nœud et le supérieur immédiat.
- Le dernier nœud peut être acquis en utilisant MAX() contre RankNode pour le parent ou le supérieur immédiat spécifié. Dans notre cas, il s'agit de l'Assistant F&B Manager avec une valeur de nœud de 0x7AD6.
- Ensuite, pour vous assurer qu'aucun enfant en double n'apparaît, utilisez @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . La valeur dans @MaxNode est le dernier enfant. Si ce n'est pas NULL , GetDescendant() renvoie la prochaine valeur de nœud possible.
- Dernier, GetLevel() renvoie le niveau du nouveau nœud créé.
Interroger des données
Après avoir ajouté des enregistrements à notre table, il est temps de l'interroger. 2 façons d'interroger les données sont disponibles :
La requête pour les descendants directs
Lorsque nous recherchons les employés relevant directement du responsable, nous devons savoir deux choses :
- La valeur du nœud du gestionnaire ou du parent
- Le niveau de l'employé sous le responsable
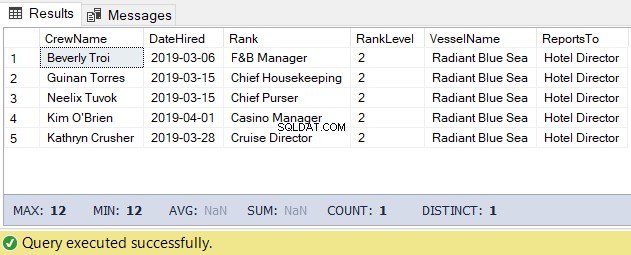
Pour cette tâche, nous pouvons utiliser le code ci-dessous. La sortie est la liste de l'équipage sous le directeur de l'hôtel.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorLe résultat du code ci-dessus est le suivant dans la figure 5 :
Requête pour les sous-arborescences
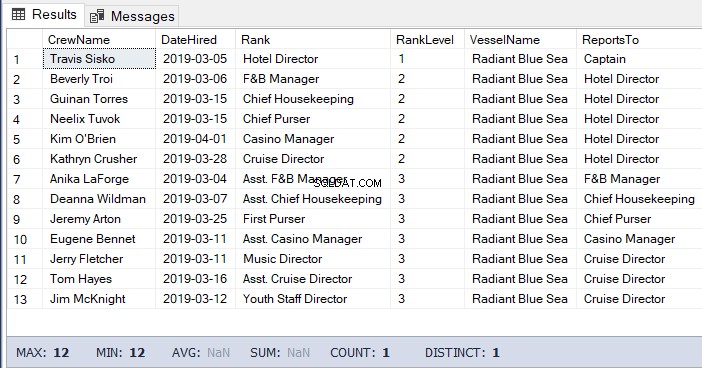
Parfois, vous devez également lister les enfants et les enfants des enfants jusqu'au bas. Pour ce faire, vous devez disposer de l'ID de hiérarchie du parent.
La requête sera similaire au code précédent mais sans qu'il soit nécessaire d'obtenir le niveau. Voir l'exemple de code :
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Le résultat du code ci-dessus :
Déplacement de nœuds avec SQL Server HierarchyID
Une autre opération standard avec des données hiérarchiques consiste à déplacer un enfant ou un sous-arbre entier vers un autre parent. Cependant, avant de poursuivre, veuillez noter un problème potentiel :
Problème potentiel
- Tout d'abord, le déplacement des nœuds implique des E/S. La fréquence à laquelle vous déplacez les nœuds peut être le facteur décisif si vous utilisez l'ID de hiérarchie ou le parent/enfant habituel.
- Deuxièmement, déplacer un nœud dans une conception parent/enfant met à jour une ligne. En même temps, lorsque vous déplacez un nœud avec l'ID de hiérarchie, il met à jour une ou plusieurs lignes. Le nombre de lignes affectées dépend de la profondeur du niveau hiérarchique. Cela peut se transformer en un problème de performances important.
Solution
Vous pouvez gérer ce problème avec la conception de votre base de données.
Considérons le design que nous avons utilisé ici.
Au lieu de définir la hiérarchie sur le Crew tableau, nous l'avons défini dans les rangs table. Cette approche diffère de l'Employé tableau dans AdventureWorks exemple de base de données, et offre les avantages suivants :
- Les membres d'équipage se déplacent plus souvent que les rangs d'un navire. Cette conception réduira les mouvements de nœuds dans la hiérarchie. En conséquence, cela minimise le problème défini ci-dessus.
- Définir plus d'une hiérarchie dans l'équipage tableau est plus compliqué, car deux navires ont besoin de deux capitaines. Le résultat est deux nœuds racine.
- Si vous avez besoin d'afficher tous les grades avec le membre d'équipage correspondant, vous pouvez utiliser un LEFT JOIN. Si personne n'est à bord pour ce rang, il affiche un emplacement vide pour le poste.
Passons maintenant à l'objectif de cette section. Ajoutez des nœuds enfants sous les mauvais parents.
Pour visualiser ce que nous sommes sur le point de faire, imaginez une hiérarchie comme celle ci-dessous. Notez les nœuds jaunes.

Déplacer un nœud sans enfants
Le déplacement d'un nœud enfant nécessite les éléments suivants :
- Définissez l'ID de hiérarchie du nœud enfant à déplacer.
- Définissez l'ancien ID de hiérarchie du parent.
- Définissez l'ID de hiérarchie du nouveau parent.
- Utilisez MISE À JOUR avec GetReparentedValue() pour déplacer le nœud physiquement.
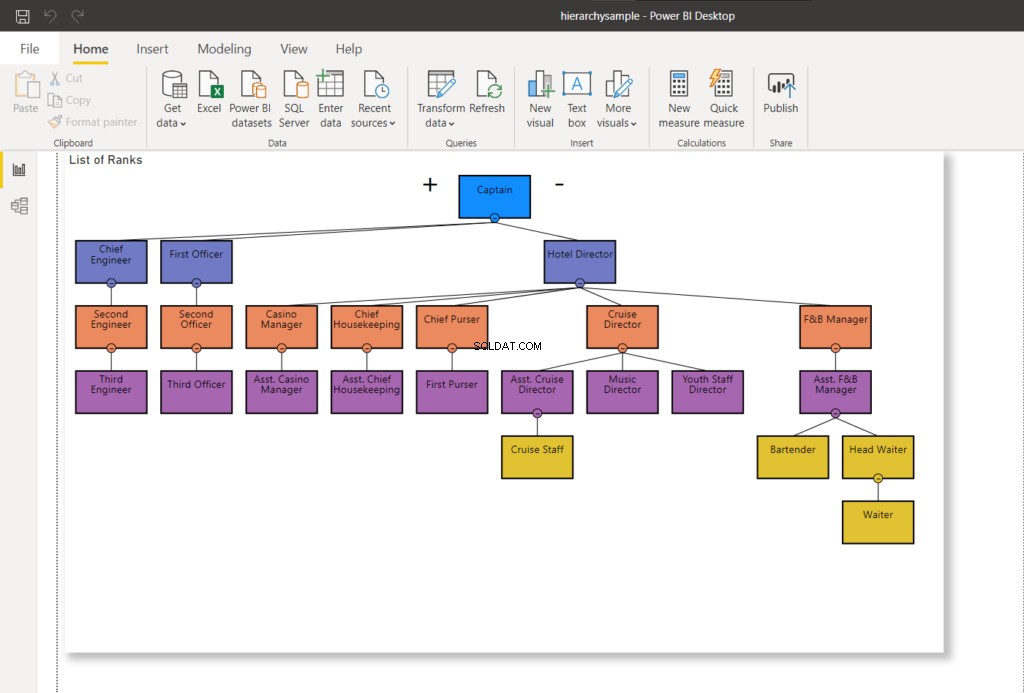
Commencez par déplacer un nœud sans enfants. Dans l'exemple ci-dessous, nous déplaçons le Cruise Staff de dessous le Cruise Director vers sous l'Asst. Directeur de croisière.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveUne fois le nœud mis à jour, une nouvelle valeur hexadécimale sera utilisée pour le nœud. Actualiser ma connexion Power BI à SQL Server - cela modifiera le graphique hiérarchique comme indiqué ci-dessous :
Dans la figure 8, le personnel de croisière ne relève plus du directeur de croisière - il est modifié pour relever du directeur adjoint de croisière. Comparez-le avec la figure 7 ci-dessus.
Passons maintenant à l'étape suivante et transférons le maître d'hôtel au directeur adjoint de la restauration.
Déplacer un nœud avec des enfants
Il y a un défi dans cette partie.
Le fait est que le code précédent ne fonctionnera pas avec un nœud avec même un enfant. Rappelons que déplacer un nœud nécessite de mettre à jour un ou plusieurs nœuds fils.
De plus, cela ne s'arrête pas là. Si le nouveau parent a un enfant existant, nous pourrions tomber sur des valeurs de nœud en double.
Dans cet exemple, nous devons faire face à ce problème :l'Asst. F&B Manager a un nœud enfant Bartender.
Prêt? Voici le code :
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;Dans l'exemple de code ci-dessus, l'itération commence par la nécessité de transférer le nœud vers l'enfant au dernier niveau.
Après l'avoir exécuté, les rangs le tableau sera mis à jour. Et encore une fois, si vous souhaitez voir les modifications visuellement, actualisez le rapport Power BI. Vous verrez des changements similaires à celui ci-dessous :
Avantages de l'utilisation de SQL Server HierarchyID par rapport à parent/enfant
Pour convaincre quiconque d'utiliser une fonctionnalité, nous devons en connaître les avantages.
Ainsi, dans cette section, nous allons comparer des déclarations utilisant les mêmes tables comme celles du début. L'un utilisera l'ID de hiérarchie et l'autre utilisera l'approche parent/enfant. L'ensemble de résultats sera le même pour les deux approches. Nous l'attendons pour cet exercice comme celui de Figure 6 ci-dessus.
Maintenant que les exigences sont précises, examinons attentivement les avantages.
Plus simple à coder
Voir le code ci-dessous :
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Cet exemple nécessite uniquement une valeur hierarchieID. Vous pouvez modifier la valeur à volonté sans modifier la requête.
Maintenant, comparez la déclaration pour l'approche parent/enfant produisant le même ensemble de résultats :
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Qu'en penses-tu? Les exemples de code sont presque les mêmes sauf un point.
Le OÙ La clause dans la deuxième requête ne sera pas flexible pour s'adapter si une sous-arborescence différente est requise.
Rendez la deuxième requête suffisamment générique et le code sera plus long. Aïe !
Exécution plus rapide
Selon Microsoft, "les requêtes de sous-arborescence sont nettement plus rapides avec l'ID de hiérarchie" par rapport au parent/enfant. Voyons si c'est vrai.
Nous utilisons les mêmes requêtes que précédemment. Les lectures logiques sont une mesure importante à utiliser pour les performances. à partir de l'E/S SET STATISTICS . Il indique le nombre de pages de 8 Ko dont SQL Server aura besoin pour obtenir le jeu de résultats souhaité. Plus la valeur est élevée, plus le nombre de pages auxquelles SQL Server accède et lit est élevé, et plus la requête s'exécute lentement. Exécutez SET STATISTICS IO ON et réexécutez les deux requêtes ci-dessus. La valeur la plus basse des lectures logiques sera la gagnante.
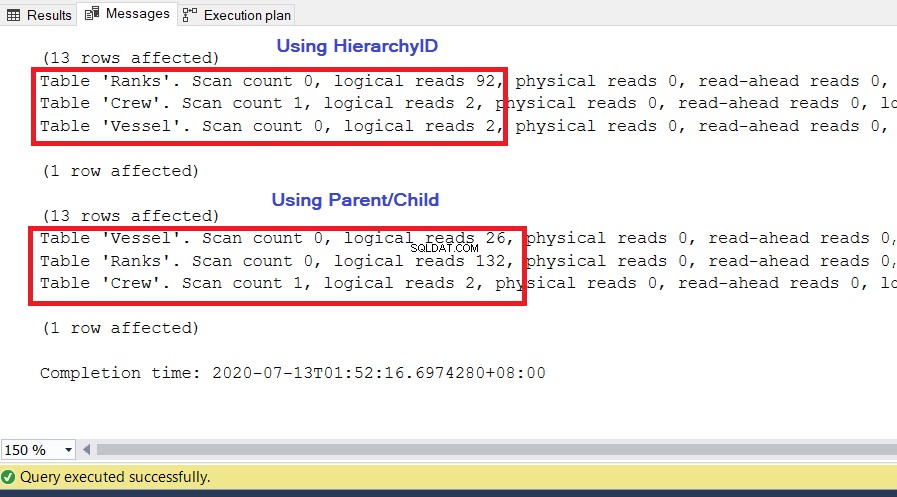
ANALYSE
Comme vous pouvez le voir dans la figure 10, les statistiques d'E/S pour la requête avec l'ID de hiérarchie ont des lectures logiques inférieures à celles de leurs homologues parent/enfant. Notez les points suivants dans ce résultat :
- Le Vaisseau table est la plus remarquable des trois tables. L'utilisation de la hiérarchie ID ne nécessite que 2 * 8 Ko =16 Ko de pages à lire par SQL Server à partir du cache (mémoire). Pendant ce temps, l'utilisation de parent/enfant nécessite 26 x 8 Ko =208 Ko de pages, ce qui est nettement supérieur à l'utilisation de l'ID de hiérarchie.
- Les rangs table, qui inclut notre définition des hiérarchies, nécessite 92 * 8 Ko =736 Ko. D'autre part, l'utilisation de parent/enfant nécessite 132 * 8 Ko =1056 Ko.
- L'équipage table a besoin de 2 * 8 Ko =16 Ko, ce qui est le même pour les deux approches.
Les kilo-octets de pages peuvent être une petite valeur pour le moment, mais nous n'avons que quelques enregistrements. Cependant, cela nous donne une idée de la façon dont notre requête sera taxée sur n'importe quel serveur. Pour améliorer les performances, vous pouvez effectuer une ou plusieurs des actions suivantes :
- Ajouter le(s) index(s) approprié(s)
- Restructurer la requête
- Mettre à jour les statistiques
Si vous faisiez ce qui précède et que les lectures logiques diminuaient sans ajouter d'enregistrements supplémentaires, les performances augmenteraient. Tant que vous faites en sorte que les lectures logiques soient inférieures à celles utilisant l'ID de hiérarchie, ce sera une bonne nouvelle.
Mais pourquoi faire référence à des lectures logiques plutôt qu'au temps écoulé ?
Vérification du temps écoulé pour les deux requêtes à l'aide de SET STATISTICS TIME ON révèle un petit nombre de différences en millisecondes pour notre petit ensemble de données. De plus, votre serveur de développement peut avoir une configuration matérielle, des paramètres SQL Server et une charge de travail différents. Un temps écoulé de moins d'une milliseconde peut vous tromper si votre requête s'exécute aussi rapidement que prévu ou non.
CROUVER PLUS LOIN
ACTIVER LES E/S STATISTIQUES ne révèle pas les choses qui se passent "dans les coulisses". Dans cette section, nous découvrons pourquoi SQL Server arrive avec ces chiffres en examinant le plan d'exécution.
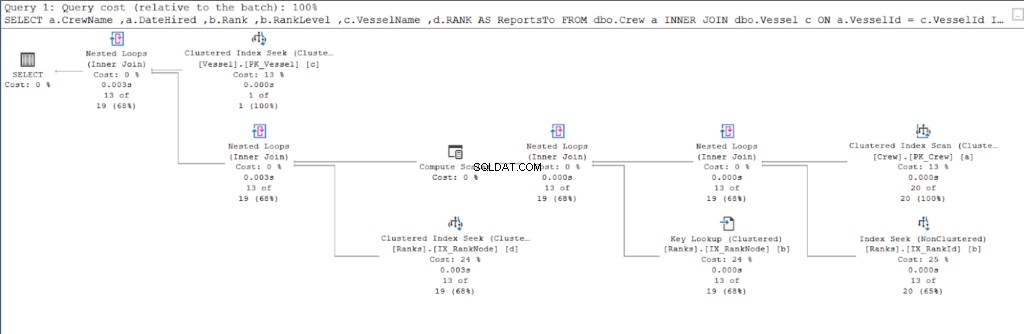
Commençons par le plan d'exécution de la première requête.
Maintenant, regardez le plan d'exécution de la deuxième requête.
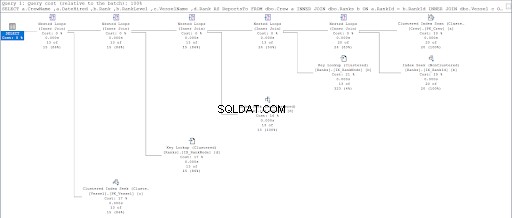
En comparant les figures 11 et 12, nous constatons que SQL Server nécessite des efforts supplémentaires pour produire le jeu de résultats si vous utilisez l'approche parent/enfant. Le OÙ clause est responsable de cette complication.
Cependant, le défaut peut également provenir de la conception de la table. Nous avons utilisé le même tableau pour les deux approches :les rangs table. J'ai donc essayé de dupliquer les rangs table mais utiliser différents index clusterisés appropriés pour chaque procédure.
En conséquence, l'utilisation de la hiérarchie ID avait toujours moins de lectures logiques par rapport à l'homologue parent/enfant. Enfin, nous avons prouvé que Microsoft avait raison de le revendiquer.
Conclusion
Ici, le moment aha central pour l'ID de hiérarchie est :
- HierarchyID est un type de données intégré conçu pour une représentation plus optimisée des arborescences, qui sont le type le plus courant de données hiérarchiques.
- Chaque élément de l'arborescence est un nœud, et les valeurs de l'ID de hiérarchie peuvent être au format hexadécimal ou sous forme de chaîne.
- HierarchyID s'applique aux données des structures organisationnelles, des tâches de projet, des données géographiques, etc.
- Il existe des méthodes pour parcourir et manipuler des données hiérarchiques, telles que GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue (), et plus encore.
- La manière conventionnelle d'interroger des données hiérarchiques consiste à obtenir les descendants directs d'un nœud ou à obtenir les sous-arborescences sous un nœud.
- L'utilisation de l'ID de hiérarchie pour interroger les sous-arborescences n'est pas seulement plus simple à coder. Il fonctionne également mieux que parent/enfant.
Le design parent/enfant n'est pas mal du tout, et ce post n'est pas pour le diminuer. Cependant, élargir les options et introduire de nouvelles idées est toujours un grand avantage pour un développeur.
Vous pouvez essayer vous-même les exemples que nous proposons ici. Recevez les effets et voyez comment vous pouvez les appliquer pour votre prochain projet impliquant des hiérarchies.
Si vous aimez la publication et ses idées, vous pouvez passer le mot en cliquant sur les boutons de partage des médias sociaux préférés.