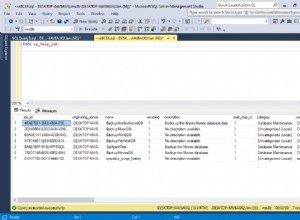
Présentation
Dans cet article, nous allons parler de l'utilisation du nvarchar Type de données. Nous allons explorer comment SQL Server stocke ce type de données sur le disque et comment il est traité dans la RAM. Nous examinerons également comment la taille de nvarchar peut affecter les performances.
Taille réelle des données :nchar vs nvarchar
Nous utilisons nvarchar lorsque la taille des entrées de données de colonne va probablement varier considérablement. La taille de stockage (en octets) est le double de la longueur réelle des données saisies + 2 octets. Cela nous permet d'économiser de l'espace disque par rapport à l'utilisation de nchar Type de données. Considérons l'exemple suivant. Nous créons deux tableaux. Une table contient une colonne nvarchar, une autre table contient des colonnes nchar. La taille de la colonne est de 2000 caractères (4000 octets).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
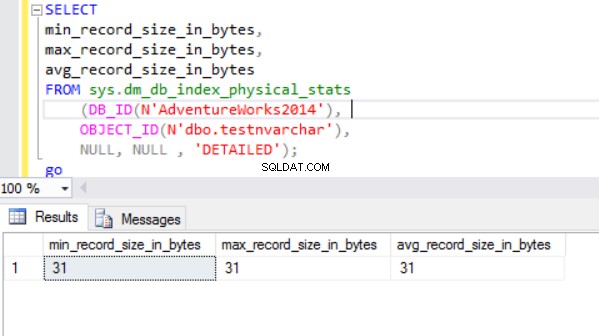
La taille réelle de la ligne est :
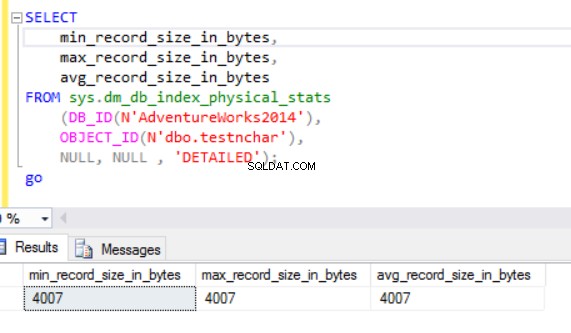
Comme nous pouvons le voir, la taille de ligne réelle du type de données nvarchar est beaucoup plus petite que le type de données nchar. Dans le cas du type de données nchar, nous utilisons ~ 4000 octets pour stocker une chaîne de caractères de 10 symboles. Nous utilisons environ 20 octets pour stocker la même chaîne de caractères dans le cas du type de données nvarchar.
Le moteur SQL Server traite les données dans la RAM (pool de mémoire tampon). Qu'en est-il de la taille des lignes dans la mémoire ?
Taille réelle des données :disque dur vs RAM
Exécutons la requête suivante :
SELECT col1 FROM dbo.testnchar;

Il n'y a aucune différence entre l'utilisation du disque et de la RAM dans le cas d'une chaîne de caractères de longueur fixe.
SELECT col1 FROM dbo.testnvarchar;

Nous pouvons voir que le moteur SQL Server n'a demandé la mémoire que pour la moitié de la taille de ligne déclarée (2000 octets au lieu des 20 octets réels) et plusieurs octets pour une information supplémentaire. D'un côté, nous diminuons l'utilisation de l'espace disque, mais d'un autre, nous pouvons gonfler la RAM demandée. Il s'agit d'un effet secondaire de l'utilisation des différents types de données de caractères. Cet effet secondaire peut avoir un impact important sur les ressources dans certains cas.
FORMAT() :RAM demandée vs RAM utilisée
Nous utilisons la fonction FORMAT, qui renvoie une valeur formatée avec le format spécifié et la culture facultative. La valeur de retour est nvarchar ou nul. La longueur de la valeur de retour est déterminée par le format . FORMAT(getdate(), 'yyyyMMdd','en-US') donnera '20170412'. Nous avons besoin de 16 octets pour stocker ce résultat sur la colonne du disque (le résultat sera nvarchar(8)). Quelle est la taille des données dans la RAM pour les données particulières ?
Exécutons la requête suivante. Nous utilisons l'environnement suivant :
- AdventureWorks 2014
- Édition de développement MS SQL 2016
- dbo.Customer (19 820 000 enregistrements) contient des données de Sales.Customer (19 820 enregistrements ont été téléchargés 1 000 fois) :
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Le plan d'exécution de la requête est assez simple :

La première opération est "Balayage d'index clusterisé" sur la table dbo.Customer. ~19 000 000 enregistrements ont été lus. La taille estimée des données est de 435 Mo.
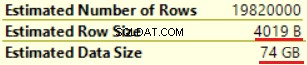
L'opération suivante est "Compute Scalar" (calcul de la fonction FORMAT()). Le résultat est assez inattendu car nous formatons une chaîne de caractères de 16 octets. La taille de la ligne a considérablement augmenté, passant de 23 octets à 4 019 octets. Il en va de même pour la taille estimée des données - de 435 Mo à 74 Go. Nous pouvons voir que FORMAT() renvoie NVARCHAR(4000).
MS SQL Server 2016 a la grande capacité d'afficher une allocation de mémoire excessive. Nous pouvons voir l'avertissement dans la dernière opération (T-SQL SELECT INTO):
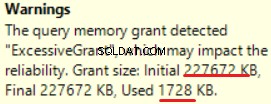
Il s'agit d'un "sur-octroi" de la mémoire :plus de 90 % de la mémoire accordée n'est pas utilisée.
Les statistiques de temps de requête sont :
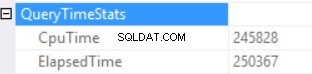
Le long temps d'exécution dépend d'une exécution de fonction scalaire non efficace et de l'effet secondaire d'une allocation de mémoire excessive - correspondance de hachage (jointure externe droite). Nous avons un effet cumulatif de deux causes différentes :l'exécution de plusieurs fonctions scalaires et l'octroi excessif de mémoire.
Le moteur SQL Server ne peut pas accorder plus de 25 % de la mémoire autorisée par requête. Nous pouvons modifier ce montant dans l'édition entreprise de MS SQL Server à l'aide du gouverneur de ressources. La mémoire accordée se compose de deux parties :requise et supplémentaire. Une mémoire requise est utilisée pour les besoins internes - pour les opérations de tri et de jointure par hachage. La mémoire supplémentaire est basée sur la taille de données estimée. Si la mémoire requise et la mémoire supplémentaire dépassent la limite de 25 %, le moteur SQL Server accorde 25 % supplémentaires de la mémoire disponible. Lisez l'article sur l'octroi de mémoire SQL Server pour plus de détails.
Exécutons la même requête sans la fonction FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
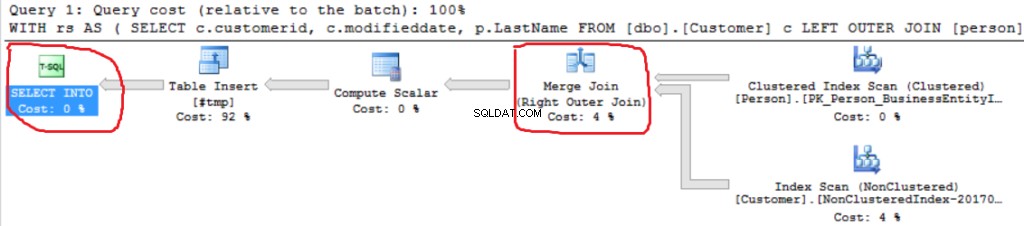
Nous pouvons voir une autre implémentation de Right Outer Join (Merge Join au lieu de Hash Join).
Les informations d'octroi de mémoire sont (si aucun tri et que le serveur SQL de jointure par hachage ne peut accorder aucune mémoire) :
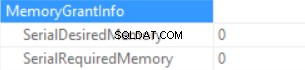
Les statistiques de temps de requête sont (le temps est diminué de manière prévisible :aucune exécution de fonction scalaire, la taille de données estimée est plus petite que dans l'échantillon précédent) :

Nous gonflons donc la "mémoire accordée" jusqu'à 222 Mo (et en utilisons moins de 2 Mo) en utilisant la fonction FORMAT(). Le volume de données dans l'exemple est faible.
Requête d'exécution de longue durée
Considérez la vraie requête SQL d'un environnement de production. Cette requête a été exécutée lors d'un processus de chargement par lots (pas un scénario transactionnel classique). Nous utilisons MS SQL Server démarré sur Amazon Web Services (AWS, Amazon Relational Database Service). Les caractéristiques de l'instance de base de données sont 160 Go de RAM (pas plus de ~30 Go de RAM peuvent être accordés par requête) et 40 vCPU. La requête SQL était presque la même que dans l'exemple ci-dessus (la différence réside dans le nombre de tables et la taille des données) :CTE incluait une jointure entre 6 tables. La « table principale » (une table dans la clause FROM) contient environ 175 000 000 enregistrements et la taille des données est de 20 Go. Les tables de recherche (table de droite dans la clause JOIN) sont petites (par rapport à la table principale). La requête SQL contient deux appels de la fonction FORMAT() (deux colonnes de la table « master table » sont le paramètre de cette fonction).
La requête de production ressemble à ceci :
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
La "photo" du plan d'exécution est ci-dessous (le plan d'exécution est simple :jointures séquentielles et tri (mots clés DISTINCT) en haut) :

Laissez-nous explorer les informations en détail.
La première opération est « Table scan » (tout est correct, pas de surprise) :

L'opération de «calcul scalaire» augmente considérablement la taille de ligne estimée ainsi que la taille de ligne estimée (de 19 Go à 1,3 To). Deux appels de la fonction FORMAT() ont ajouté environ 8 000 octets à la taille de ligne estimée (mais la taille réelle des données est plus petite).

L'une des opérations JOIN (Hash Match, Right Outer Join) utilise des colonnes non uniques de la table de droite. Peu importe dans le cas de quelques enregistrements. Ce n'est pas notre cas. En conséquence, la taille estimée des données augmente jusqu'à ~2,4 To.

Il y a aussi un avertissement (pas assez de RAM pour traiter cette opération) :
La requête SQL contient une opération "Distinct Sort" en haut, qui ressemble à la cerise sur le dessus d'un gâteau. Nous pouvons y voir le même avertissement.
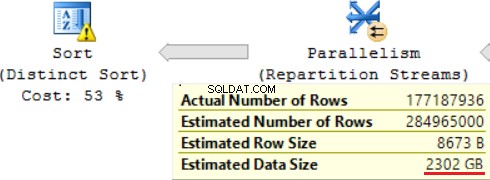
Le résultat de l'utilisation d'une fonction scalaire est une longue durée d'exécution de la requête :24 heures. L'une des causes de ce problème est une estimation incorrecte de la taille des données demandées basée sur "Taille des données estimée". Sans utiliser la fonction FORMAT(), MS SQL Server exécute cette requête en 2 heures.
Conclusion
Les développeurs doivent être prudents lorsqu'ils utilisent les types de données nvarchar et varchar. La sélection de types de données redondants pour les colonnes peut entraîner un gonflement de la mémoire requise. En conséquence, la RAM sera gaspillée, les performances de la base de données seront dégradées.