Il s'agit de la deuxième partie d'une série en cinq parties qui analyse en profondeur le démarrage des plans parallèles en mode ligne de SQL Server. À la fin de la première partie, nous avions créé le contexte d'exécution zéro pour la tâche parent. Ce contexte contient toute l'arborescence des opérateurs exécutables, mais ils ne sont pas encore prêts pour le modèle d'exécution itératif du moteur de traitement des requêtes.
Exécution itérative
SQL Server exécute une requête via un processus appelé analyse de requête . L'initialisation du plan commence à la racine par le processeur de requêtes appelant Open sur le nœud racine. Open les appels parcourent l'arborescence des itérateurs en appelant récursivement Open sur chaque enfant jusqu'à ce que tout l'arbre soit ouvert.
Le processus de retour des lignes de résultats est également récursif, déclenché par le processeur de requête appelant GetRow à l'origine. Chaque appel racine renvoie une ligne à la fois. Le processeur de requête continue d'appeler GetRow sur le nœud racine jusqu'à ce qu'il n'y ait plus de lignes disponibles. L'exécution s'arrête avec un Close récursif final appel. Cet arrangement permet au processeur de requêtes d'initialiser, d'exécuter et de fermer n'importe quel plan arbitraire en appelant les mêmes méthodes d'interface juste à la racine.
Pour transformer l'arborescence des opérateurs exécutables en une arborescence adaptée au traitement ligne par ligne, SQL Server ajoute une analyse de requête emballage à chaque opérateur. L'analyse des requêtes l'objet fournit le Open , GetRow , et Close méthodes nécessaires à l'exécution itérative.
L'objet d'analyse de requête conserve également les informations d'état et expose d'autres méthodes spécifiques à l'opérateur nécessaires lors de l'exécution. Par exemple, l'objet d'analyse de requête pour un opérateur de filtre de démarrage (CQScanStartupFilterNew ) expose les méthodes suivantes :
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Les méthodes supplémentaires pour cet itérateur sont principalement utilisées dans les plans de curseur.
Initialisation de l'analyse de requête
Le processus d'encapsulation est appelé initialisation de l'analyse de la requête . Elle est effectuée par un appel du processeur de requêtes à CQueryScan::InitQScanRoot . La tâche parente exécute ce processus pour le plan entier (contenu dans le contexte d'exécution zéro). Le processus de traduction est lui-même de nature récursive, commençant à la racine et descendant dans l'arborescence.
Au cours de ce processus, chaque opérateur est responsable de l'initialisation de ses propres données et de la création de toutes les ressources d'exécution il faut. Cela peut inclure la création d'objets supplémentaires en dehors du processeur de requêtes, par exemple les structures nécessaires pour communiquer avec le moteur de stockage afin d'extraire des données du stockage persistant.
Un rappel du plan d'exécution, avec les numéros de nœuds ajoutés (cliquez pour agrandir) :
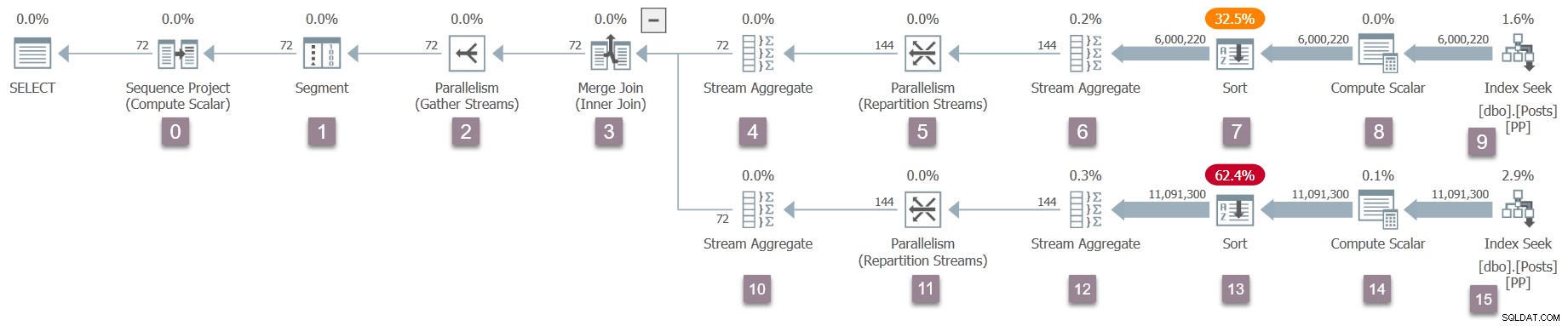
L'opérateur à la racine (nœud 0) de l'arborescence du plan exécutable est un projet de séquence . Il est représenté par une classe nommée CXteSeqProject . Comme d'habitude, c'est là que commence la transformation récursive.
Enveloppes d'analyse de requête
Comme mentionné, le CXteSeqProject l'objet n'est pas équipé pour participer à l'analyse de requête itérative processus - il n'a pas le Open requis , GetRow , et Close méthodes. Le processeur de requêtes a besoin d'un wrapper autour de l'opérateur exécutable pour fournir cette interface.
Pour obtenir ce wrapper d'analyse de requête, la tâche parent appelle CXteSeqProject::QScanGet pour retourner un objet de type CQScanSeqProjectNew . La carte liée des opérateurs créés précédemment est mis à jour pour référencer le nouvel objet d'analyse de requête, et ses méthodes itératives sont connectées à la racine du plan.
L'enfant du projet de séquence est un segment opérateur (nœud 1). Appel de CXteSegment::QScanGet renvoie un objet wrapper d'analyse de requête de type CQScanSegmentNew . La carte liée est à nouveau mise à jour et les pointeurs de fonction d'itérateur sont connectés à l'analyse de requête du projet de séquence parent.
Un demi-échange
L'opérateur suivant est un échange de flux de collecte (noeud 2). Appel de CXteExchange::QScanGet renvoie un CQScanExchangeNew comme vous vous en doutez maintenant.
Il s'agit du premier opérateur de l'arborescence qui doit effectuer une initialisation supplémentaire importante. Cela crée le côté consommateur de l'échange via CXTransport::CreateConsumerPart . Cela crée le port (CXPort ) — une structure de données en mémoire partagée utilisée pour la synchronisation et l'échange de données — et un tube (CXPipe ) pour le transport de paquets. Notez que le producteur côté de l'échange n'est pas créé en ce moment. Nous n'avons qu'un demi-échange !
Plus d'emballage
Le processus de configuration de l'analyse du processeur de requêtes se poursuit ensuite avec la jointure de fusion (noeud 3). Je ne répéterai pas toujours le QScanGet et CQScan* appels à partir de ce moment, mais ils suivent le modèle établi.
La jointure de fusion a deux enfants. La configuration de l'analyse des requêtes se poursuit comme avant avec l'entrée externe (en haut) :un agrégat de flux (nœud 4), puis une répartition des flux échange (noeud 5). Les flux de répartition créent à nouveau uniquement le côté consommateur de l'échange, mais cette fois, deux canaux sont créés car DOP est deux. Le côté consommateur de ce type d'échange a des connexions DOP à son opérateur parent (une par thread).
Ensuite, nous avons un autre agrégat de flux (noeud 6) et un tri (noeud 7). Le tri a un enfant non visible dans les plans d'exécution - un ensemble de lignes de moteur de stockage utilisé pour implémenter le déversement vers tempdb . Le CQScanSortNew attendu est donc accompagné d'un fils CQScanRowsetNew dans l'arborescence interne. Il n'est pas visible dans la sortie showplan.
Profilage d'E/S et opérations différées
Le tri L'opérateur est également le premier que nous ayons initialisé jusqu'à présent qui pourrait être responsable des I/O . En supposant que l'exécution a demandé des données de profilage d'E/S (par exemple, en demandant un plan "réel"), le tri crée un objet pour enregistrer ces données de profilage d'exécution via CProfileInfo::AllocProfileIO .
L'opérateur suivant est un scalaire de calcul (noeud 8), appelé un projet intérieurement. L'appel de configuration d'analyse de requête à CXteProject::QScanGet n'est pas renvoie un objet d'analyse de requête, car les calculs effectués par ce scalaire de calcul sont différés au premier opérateur parent qui a besoin du résultat. Dans ce plan, cet opérateur est le tri. Le tri effectuera tout le travail affecté au scalaire de calcul, de sorte que le projet au nœud 8 ne fait pas partie de l'arborescence d'analyse de requête. Le scalaire de calcul n'est vraiment pas exécuté au moment de l'exécution. Pour plus de détails sur les scalaires de calcul différé, consultez Scalaires de calcul, expressions et performances du plan d'exécution.
Analyse parallèle
Le dernier opérateur après le scalaire de calcul sur cette branche du plan est une recherche d'index (CXteRange ) au nœud 9. Cela produit l'opérateur d'analyse de requête attendu (CQScanRangeNew ), mais il nécessite également une séquence complexe d'initialisations pour se connecter au moteur de stockage et faciliter une analyse parallèle de l'index.
Couvrant juste les points saillants, initialisant la recherche d'index :
- Crée un objet de profilage pour les E/S (
CProfileInfo::AllocProfileIO). - Crée un ensemble de lignes parallèle analyse de requête (
CQScanRowsetNew::ParallelGetRowset). - Configure une synchronisation objet pour coordonner l'analyse de plage parallèle à l'exécution (
CQScanRangeNew::GetSyncInfo). - Crée le moteur de stockage curseur de table et un descripteur de transaction en lecture seule .
- Ouvre l'ensemble de lignes parent pour la lecture (accès au HoBt et prise des verrous nécessaires).
- Définit le délai de verrouillage.
- Configure la prélecture (y compris les tampons de mémoire associés).
Ajout d'opérateurs de profilage en mode ligne
Nous avons maintenant atteint le niveau feuille de cette branche du plan (l'index seek n'a pas d'enfant). Après avoir créé l'objet d'analyse de requête pour la recherche d'index, l'étape suivante consiste à envelopper l'analyse de requête avec une classe de profilage (en supposant que nous ayons demandé un plan réel). Cela se fait par un appel à sqlmin!PqsWrapQScan . Notez que les profileurs sont ajoutés après la création de l'analyse de la requête, lorsque nous commençons à remonter l'arborescence des itérateurs.
PqsWrapQScan crée un nouvel opérateur de profilage en tant que parent de la recherche d'index, via un appel à CProfileInfo::GetOrCreateProfileInfo . L'opérateur de profilage (CQScanProfileNew ) a les méthodes d'interface d'analyse de requête habituelles. En plus de collecter les données nécessaires aux plans réels, les données de profilage sont également exposées via le DMV sys.dm_exec_query_profiles .
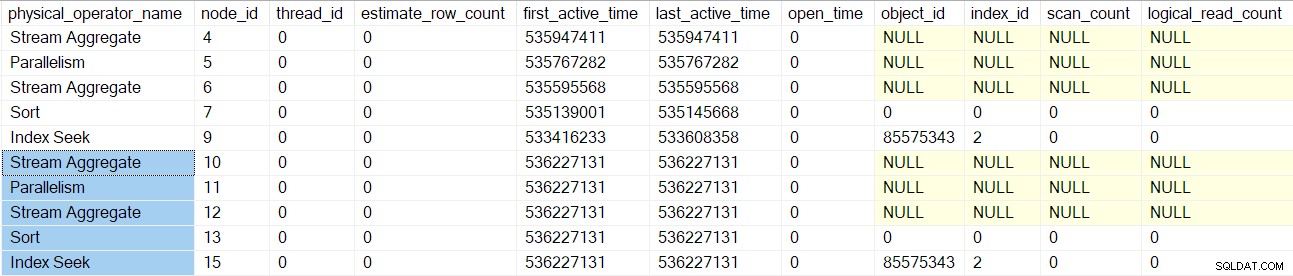
Interroger ce DMV à ce moment précis pour la session en cours montre qu'un seul opérateur de plan (nœud 9) existe (ce qui signifie qu'il est le seul enveloppé par un profileur) :

Cette capture d'écran montre le jeu de résultats complet du DMV au moment actuel (il n'a pas été modifié).
Ensuite, CQScanProfileNew appelle l'API de compteur de performances de requête (KERNEL32!QueryPerformanceCounterStub ) fourni par le système d'exploitation pour enregistrer les premier et dernier temps d'activité de l'opérateur profilé :

La dernière heure active sera mis à jour à l'aide de l'API de compteur de performances de requête à chaque exécution du code de cet itérateur.
Le profileur définit ensuite le nombre estimé de lignes à ce stade du plan (CProfileInfo::SetCardExpectedRows ), en tenant compte de n'importe quel objectif de ligne (CXte::CardGetRowGoal ). Puisqu'il s'agit d'un plan parallèle, il divise le résultat par le nombre de threads (CXte::FGetRowGoalDefinedForOneThread ) et enregistre le résultat dans le contexte d'exécution.
Le nombre estimé de lignes n'est pas visible via le DMV à ce stade, car la tâche parent n'exécutera pas cet opérateur. Au lieu de cela, l'estimation par thread sera exposée plus tard dans des contextes d'exécution parallèles (qui n'ont pas encore été créés). Néanmoins, le numéro par thread est enregistré dans le profileur de la tâche parent - il n'est tout simplement pas visible via le DMV.
Le nom convivial de l'opérateur du plan ("Index Seek") est alors défini via un appel à CXteRange::GetPhysicalOp :

Avant cela, vous avez peut-être remarqué que l'interrogation du DMV affichait le nom sous la forme "???". Il s'agit du nom permanent affiché pour les opérateurs invisibles (par exemple, prélecture de boucles imbriquées, tri par lots) qui n'ont pas de nom convivial défini.
Enfin, indexez les métadonnées et les statistiques d'E/S actuelles pour la recherche d'index enveloppé sont ajoutés via un appel à CQScanRowsetNew::GetIoCounters :

Les compteurs sont à zéro pour le moment, mais seront mis à jour lorsque la recherche d'index effectuera des E/S pendant l'exécution du plan terminé.
Plus de traitement de l'analyse des requêtes
Avec l'opérateur de profilage créé pour la recherche d'index, le traitement de l'analyse des requêtes remonte l'arborescence vers le parent sort (noeud 7).
Le tri effectue les tâches d'initialisation suivantes :
- Enregistre son utilisation de la mémoire avec la requête gestionnaire de mémoire (
CQryMemManager::RegisterMemUsage) - Calcule la mémoire requise pour l'entrée de tri (
CQScanIndexSortNew::CbufInputMemory) et sortie (CQScanSortNew::CbufOutputMemory). - La table de tri est créé, ainsi que son ensemble de lignes de moteur de stockage associé (
sqlmin!RowsetSorted). - Une transaction système autonome (non limité par la transaction utilisateur) est créé pour les allocations de disque de débordement de tri, ainsi qu'une fausse table de travail (
sqlmin!CreateFakeWorkTable). - Le service d'expression est initialisé (
sqlTsEs!CEsRuntime::Startup) pour que l'opérateur de tri effectue les calculs différés du scalaire de calcul. - Prélecture pour toute exécution de tri renversée sur tempdb est alors créé via (
CPrefetchMgr::SetupPrefetch).
Enfin, l'analyse de la requête de tri est enveloppée par un opérateur de profilage (y compris les E/S) comme nous l'avons vu pour la recherche d'index :

Notez que le scalaire de calcul (nœud 8) est manquant de la DMV. En effet, son travail est reporté au tri, ne fait pas partie de l'arborescence d'analyse des requêtes et n'a donc pas d'objet profileur d'encapsulation.
En remontant jusqu'au parent du tri, l'agrégat de flux L'opérateur d'analyse de requête (nœud 6) initialise ses expressions et ses compteurs d'exécution (par exemple, le nombre de lignes du groupe actuel). L'agrégat de flux est entouré d'un opérateur de profilage, enregistrant ses temps initiaux :

La répartition parente des flux exchange (nœud 5) est enveloppé par un profileur (rappelez-vous que seul le côté consommateur de cet échange existe à ce stade) :

La même chose est faite pour son agrégat de flux parent (nœud 4), qui est également initialisé comme décrit précédemment :

Le traitement de l'analyse des requêtes retourne à la jointure de fusion parente (nœud 3) mais ne l'initialise pas encore. Au lieu de cela, nous nous déplaçons vers le bas du côté interne (inférieur) de la jointure de fusion, en effectuant les mêmes tâches détaillées pour ces opérateurs (nœuds 10 à 15) que pour la branche supérieure (externe) :
Une fois ces opérateurs traités, la jointure de fusion l'analyse de requête est créée, initialisée et enveloppée avec un objet de profilage. Cela inclut les compteurs d'E/S, car une jointure de fusion plusieurs-plusieurs utilise une table de travail (même si la jointure de fusion actuelle est un-plusieurs) :
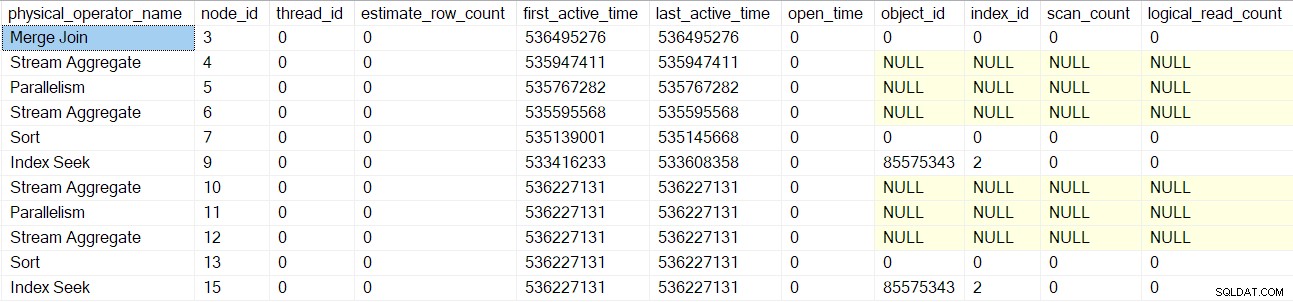
Le même processus est suivi pour les flux de collecte parent échange (nœud 2) côté consommateur uniquement, segment (nœud 1) et projet de séquence (nœud 0) opérateurs. Je ne les décrirai pas en détail.
Les profils de requête DMV signalent désormais un ensemble complet de nœuds d'analyse de requête intégrés au profileur :
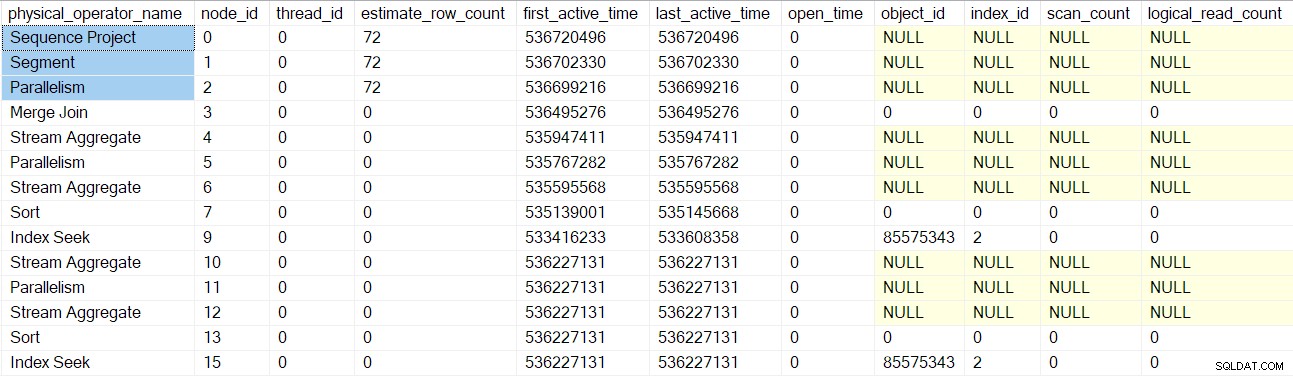
Notez que le projet de séquence, le segment et le consommateur de flux de collecte ont un nombre de lignes estimé, car ces opérateurs seront exécutés par la tâche parent , pas par des tâches parallèles supplémentaires (voir CXte::FGetRowGoalDefinedForOneThread plus tôt). La tâche parente n'a pas de travail à faire dans les branches parallèles, donc le concept de nombre de lignes estimé n'a de sens que pour les tâches supplémentaires.
Les valeurs de temps actif indiquées ci-dessus sont quelque peu déformées car j'avais besoin d'arrêter l'exécution et de prendre des captures d'écran DMV à chaque étape. Une exécution séparée (sans les retards artificiels introduits par l'utilisation d'un débogueur) a produit les délais suivants :
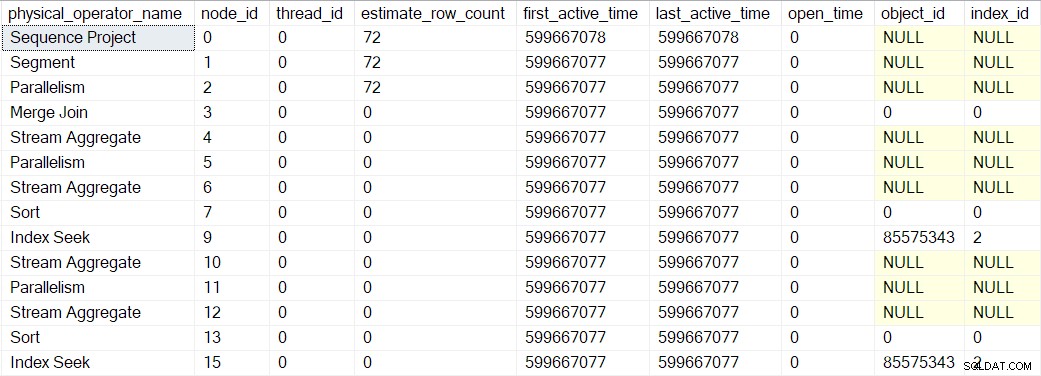
L'arbre est construit dans la même séquence décrite précédemment, mais le processus est si rapide qu'il n'y a qu'une microseconde différence entre le temps actif du premier opérateur enveloppé (la recherche d'index au nœud 9) et le dernier (le projet de séquence au nœud 0).
Fin de la partie 2
Il peut sembler que nous avons fait beaucoup de travail, mais rappelez-vous que nous n'avons créé qu'un arbre d'analyse des requêtes pour la tâche parente , et les bourses n'ont qu'un côté consommateur (pas encore de producteur). Notre plan parallèle n'a également qu'un seul fil (comme indiqué dans la dernière capture d'écran). La partie 3 verra la création de nos premières tâches parallèles supplémentaires.