L'assurance-vie est quelque chose dont nous espérons tous ne pas avoir besoin, mais comme nous le savons, la vie est imprévisible. Dans cet article, nous nous concentrerons sur la formulation d'un modèle de données qu'une compagnie d'assurance-vie peut utiliser pour stocker ses informations.
L'assurance-vie en tant que concept
Avant de commencer à discuter du modèle de données réel d'une compagnie d'assurance-vie, nous allons brièvement nous rappeler ce qu'est l'assurance et son fonctionnement afin d'avoir une meilleure idée de ce avec quoi nous travaillons.
L'assurance est un concept assez ancien qui remonte même avant le Moyen Âge, lorsque de nombreuses guildes proposaient des polices pour protéger leurs membres dans des situations inattendues. Même le célèbre astronome, mathématicien, scientifique et inventeur Edmund Halley s'est essayé à l'assurance, travaillant sur les statistiques et les taux de mortalité qui constituaient l'épine dorsale des modèles d'assurance modernes.
Pourquoi devriez-vous payer une assurance? L'idée est assez simple - vous payez un certain montant (la prime) en échange de la garantie de la compagnie d'assurance que vous ou votre famille serez indemnisés financièrement si quelque chose d'inattendu vous arrive ou arrive à vos biens. Dans le cas d'un contrat d'assurance-vie, vous désignez un bénéficiaire qui recevra une somme d'argent (la prestation) en cas de décès. L'idée est que cet argent les aidera à se remettre de leur perte, surtout si votre décès crée des problèmes financiers.
Bien sûr, les compagnies d'assurance paient généralement beaucoup moins en prestations qu'elles ne gagnent sur les primes et en investissant votre argent, par exemple, sur le marché boursier. Sinon, ils feraient faillite et tout le système s'effondrerait !
C'est à peu près l'essentiel. Maintenant que nous avons réglé ce problème, examinons le modèle de données d'une compagnie d'assurance-vie type.
Le modèle de données :présentation
Le modèle de données avec lequel nous allons travailler se compose de cinq domaines :
- Employés
- Produits
- Client
- Offres
- Paiements
Nous couvrirons chacune de ces sections plus en détail, dans l'ordre dans lequel elles sont répertoriées ci-dessus.
Domaine n° 1 :Employés
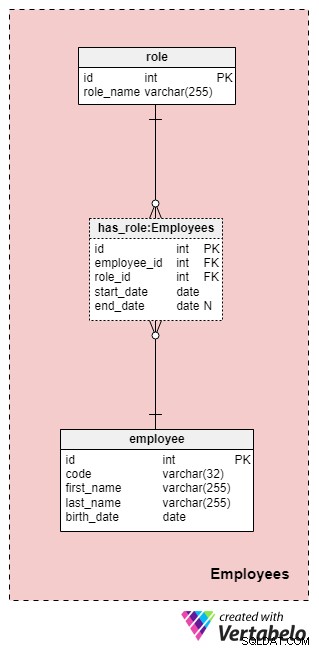
Ce domaine n'est pas nécessairement spécifique à ce modèle de données, mais il est tout de même très important car les tableaux contenus ici seront référencés par d'autres domaines. Pour les besoins de notre modèle de données de compagnie d'assurance, nous aurons bien sûr besoin de savoir qui a effectué quelle action (par exemple, qui a représenté notre compagnie lorsque nous avons travaillé avec le client/client, qui a signé la police, etc.).
La liste de tous les employés de l'entreprise est stockée dans le employee table. Pour chaque employé, nous stockerons les informations suivantes :
code— une clé unique qui identifie un seul employé. Étant donné que le code sera utilisé comme attribut dans d'autres tables, il servira de clé alternative dans cette table.first_nameetlast_name— le nom et le prénom de l'employé, respectivement.birth_date— la date de naissance de l'employé.
Bien sûr, nous pourrions certainement inclure de nombreux autres attributs liés aux employés dans ce tableau, mais ces quatre sont plus que suffisants pour le moment. Nous suivrons ce modèle tout au long de l'article et essaierons de garder les choses aussi simples que possible, mais notez que vous pouvez certainement étendre ce modèle de données pour inclure des informations supplémentaires.
Étant donné que les employés peuvent changer de rôle dans notre entreprise à tout moment, nous aurons besoin d'une table de dictionnaire pour représenter les rôles de l'entreprise et d'une table pour stocker les valeurs. La liste de tous les rôles possibles que les employés peuvent assumer au sein de notre compagnie d'assurance-vie est stockée dans le role dictionnaire. Il n'a qu'un seul attribut nommé role_name qui contient des valeurs d'identification uniques.
Nous mettrons en relation les employés et les rôles à l'aide du has_role table. En plus des clés étrangères employee_id et role_id , nous stockerons deux valeurs :start_date et end_date . Ces deux valeurs indiquent la plage dans laquelle ce rôle dans l'entreprise était actif pour un employé particulier. La end_date contiendra une valeur nulle jusqu'à ce qu'une date de fin pour le rôle de cet employé ait été déterminée. La clé alternative pour cette table est la combinaison de employee_id , role_id , et start_date . Pour éviter de dupliquer le même rôle pour le même employé, nous devrons vérifier par programmation tout chevauchement chaque fois que nous ajoutons un nouvel enregistrement au tableau ou mettons à jour un existant.
Domaine 2 : Produits
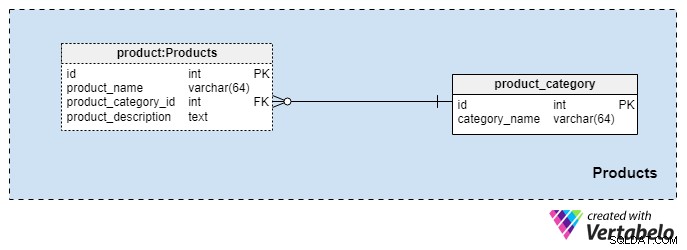
Ce domaine est assez petit et ne contient que deux tableaux. Les valeurs de ces tableaux sont des conditions préalables pour nos autres domaines, nous en discuterons donc brièvement.
Le product_category dictionnaire stocke les catégories les plus générales de produits que nous prévoyons d'offrir à nos clients. La seule valeur que nous stockerons dans cette table est l'unique category_name pour indiquer le type d'assurance que nous proposons, qui peut être une assurance-vie personnelle, une assurance-vie familiale, etc.
Nous catégoriserons encore plus nos produits en utilisant le product table. Ce tableau représente les produits réels que nous vendons et non leurs catégories. Comme vous pouvez l'imaginer, nous pouvons regrouper les produits par durée (par exemple, 10 ou 20 ans, voire toute une vie). Si nous choisissons de le faire, nous aurons probablement des produits avec le même product_category_id mais des noms et des descriptions différents. Pour chaque produit, nous stockons les informations de base suivantes :
product_name— le nom de ce produit. Il est utilisé comme clé alternative pour cette table en combinaison avec leproduct_category_idattribut. Il est peu probable que nous ayons deux produits portant le même nom qui appartiennent à des catégories différentes, mais c'est néanmoins une possibilité.product_category_id— identifie la catégorie à laquelle appartient ce produit.product_description— description textuelle de ce produit.
Domaine n° 3 :Clients
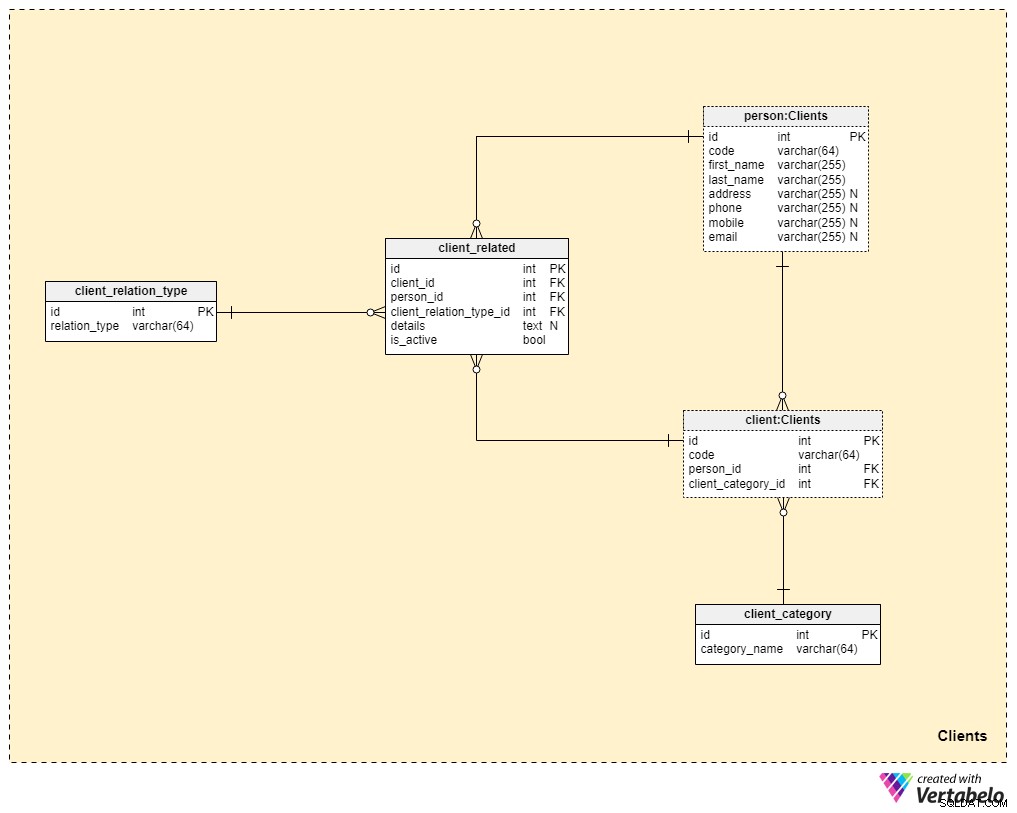
Nous nous rapprochons maintenant beaucoup plus du cœur de notre modèle de données, mais nous n'en sommes pas encore là. L'assurance-vie est unique car une police peut être transférée à un membre de la famille ou à quelqu'un d'autre, alors que les polices d'autres formes d'assurance (telles que l'assurance maladie ou l'assurance automobile) appartiennent à un seul client et ne peuvent pas être transférées. Pour cette raison, nous devrons stocker non seulement des informations sur le client à qui appartient la police, mais également des informations sur toutes les personnes liées et leur relation avec le client.
Nous allons commencer par le client table. Pour chaque client, nous stockerons le code unique généré ou inséré manuellement pour ce client, ainsi que les clés étrangères référençant la table avec leurs données personnelles (person_id ) et le tableau contenant notre catégorisation interne (client_category_id ).
Le client_category dictionnaire nous permet de regrouper les clients en fonction de leurs données démographiques et de leurs détails financiers. Les catégories de clients seront ensuite utilisées pour déterminer la police d'assurance que nous sommes prêts à offrir à un client particulier. Ici, nous ne stockerons qu'une liste de valeurs uniques que nous attribuerons ensuite aux clients.
Puisque nous parlons d'assurance-vie, nous supposerons donc qu'un client est une personne seule. Cependant, comme nous l'avons mentionné précédemment, il peut y avoir d'autres personnes liées au client à qui la police peut être transférée ou qui peuvent recevoir le bénéfice de la police au décès du client. Pour cette raison, nous avons créé une person table. Pour chaque enregistrement de ce tableau, nous stockerons les informations suivantes :
code— une valeur générée automatiquement ou insérée manuellement utilisée pour identifier de manière unique la personne associée.first_nameetlast_name— le prénom et le nom de la personne, respectivement.address,phone,mobileetemail— les coordonnées de cette personne, qui contiennent toutes des valeurs arbitraires.
Les deux autres tableaux de ce domaine sont nécessaires pour décrire la nature de la relation entre les clients et les autres personnes.
La liste de tous les types de relation possibles est stockée dans le client_relation_type dictionnaire. Comme avec d'autres dictionnaires, celui-ci contiendra une liste de noms uniques que nous utiliserons plus tard pour décrire la relation entre un client particulier et une autre personne.
Les données de relation réelles sont stockées dans le client_related table. Pour chaque enregistrement de cette table, nous stockerons les références au client (client_id ), la personne liée (person_id ), la nature de cette relation (client_relation_type_id ), tous les détails des ajouts (details ), le cas échéant, et un indicateur indiquant si la relation est actuellement active (is_active ). La clé alternative dans cette table est définie par la combinaison de client_id , person_id , et client_relation_type_id .
Sujet n° 4 :Offres
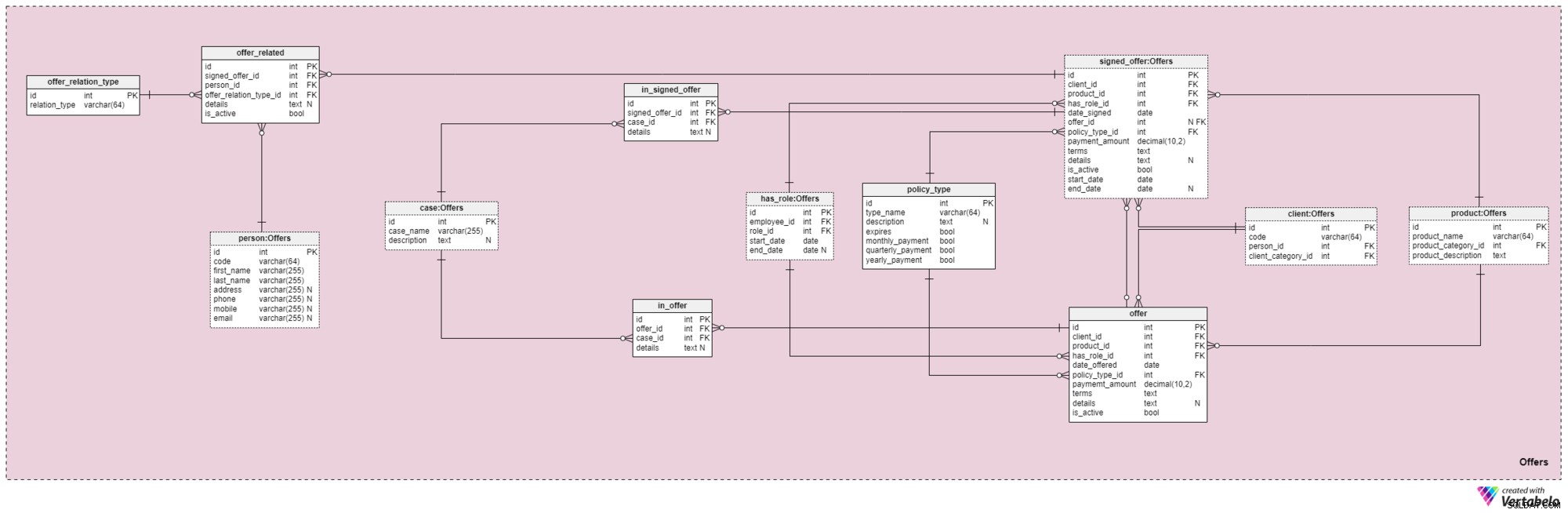
Ce domaine et celui qui suit sont au cœur de ce modèle de données. Ils couvrent les offres et les polices signées, ainsi que les paiements liés aux offres. Tout d'abord, nous décrirons le domaine Offres. Il peut sembler complexe car il contient 12 tables. Cependant, quatre de ces 12 (has_role , product , client , et person ) ont été décrites dans des domaines précédents, nous ne répéterons donc pas notre discussion ici.
L'offre offer et signed_offer les tables ont des structures similaires car elles seront utilisées pour stocker des données très similaires dans notre modèle. Cependant, même si l'offer sera principalement utilisé pour stocker toutes les politiques (et leurs détails) que nous avons proposées à nos clients, le signed_offer table sera strictement utilisée pour stocker des informations sur les clients qui ont effectivement signé des politiques avec notre société. Nous couvrirons ces tableaux ensemble, en notant toute différence là où ils apparaissent. Les attributs de ces deux tables sont les suivants :
client_id— référence à l'identifiant unique du client qui a signé une offre particulière.product_id— référence à l'identifiant unique du produit inclus dans l'offre signée.has_role_id— référence à l'identifiant de l'employé et au rôle qu'il occupait au moment où l'offre a été présentée/signée.date_offeredetdate_signed— les dates réelles indiquant quand cette offre a été présentée au client et quand elle a été signée, respectivement.offer_id— une référence à l'offre précédente pour ce client. Cela peut contenir une valeur nulle, car le client peut avoir signé une police sans avoir reçu d'offre préalable de la société, par exemple s'il nous a contactés par lui-même. Cet attribut appartient strictement ausigned_offertableau.policy_type_id— référence au dictionnaire des types de police indiquant le type de police que nous avons proposé au client ou que nous lui avons fait signer.payment_amount— le montant que le client doit payer régulièrement pour la police.terms— tous les termes de l'accord, en format textuel (XML). L'idée est de stocker tous les détails importants concernant la partie financière de la politique dans cet attribut. Des exemples de texte que nous pourrions stocker sont le montant total de la police, le nombre de paiements que le client doit effectuer, etc.details— tout détail supplémentaire, sous forme textuelle.is_active— indicateur indiquant si l'enregistrement est toujours actif.start_dateetend_date— indique la plage de temps pendant laquelle cette politique est/était active. Si la politique a été signée pour une durée de vie, alors end_date contiendra une valeur de null.
Il y a aussi le policy_type dictionnaire que nous avons brièvement mentionné auparavant. Nous avons besoin d'un certain degré de flexibilité dans la façon dont nous offrons le même produit à différents clients, en fonction de facteurs tels que l'âge, la santé, l'état matrimonial, le risque de crédit, etc. Pour chaque type de politique, nous stockerons un type_name identifiant, une description textuelle supplémentaire , un indicateur nommé expires indiquant si la police peut expirer, et un autre indicateur indiquant si les primes de ce type de police doivent être payées mensuellement, trimestriellement ou annuellement. Certains types de polices attendues sont :l'assurance vie temporaire, l'assurance vie entière, l'assurance vie universelle, l'assurance vie universelle garantie, l'assurance vie variable, l'assurance vie universelle variable et l'assurance vie après la retraite.
Passant à autre chose, nous devons maintenant définir tous les cas et situations qu'une police particulière peut couvrir. Nous devons relier ces cas à des offres spécifiques et à des offres signées.
La liste de tous les cas possibles couverts par nos politiques est stockée dans le case dictionnaire. Chaque enregistrement de cette table peut être identifié de manière unique par son case_name et a une description supplémentaire , si nécessaire.
Le in_offer et in_signed_offer les tables partagent la même structure car elles stockent les mêmes données. La seule différence entre les deux est que le premier stocke les cas couverts dans la police qui a simplement été proposée au client, tandis que le second stocke les cas dans la police signée par le client. Pour chaque enregistrement dans ces deux tables, nous stockerons la paire unique de offer_id /signed_offer_id et case_id , ce dernier désignant le cas ou l'incident couvert par la police. Tous les autres détails seront stockés dans un attribut textuel, si nécessaire.
Comme nous l'avons mentionné précédemment, les polices d'assurance-vie sont presque toujours liées non seulement aux clients, mais également aux membres de leur famille ou à leurs proches. Nous devons également stocker ces relations dans ce domaine. Ils seront définis au moment de la signature d'une police, mais ils pourront également être modifiés pendant toute la durée de la police.
La première chose que nous devons faire est de créer un dictionnaire contenant toutes les valeurs possibles pouvant être attribuées à une relation. Dans notre modèle, il s'agit du offer_relation_type dictionnaire. Outre la clé primaire, cette table ne contient qu'un seul attribut :le relation_type – qui ne peut contenir que des valeurs uniques.
Nous y sommes presque! Le dernier tableau de ce domaine est intitulé offer_related . Il concerne une offre signée à toute personne liée au client. Par conséquent, nous devrons stocker les références à la politique signée (signed_offer_id ) et la personne liée (person_id ) et précisez également la nature de cette relation (offer_relation_type_id ). De plus, nous devrons stocker les details lié à cet enregistrement et créez un indicateur pour vérifier s'il est toujours valide dans notre système.
Domaine n° 5 :Paiements
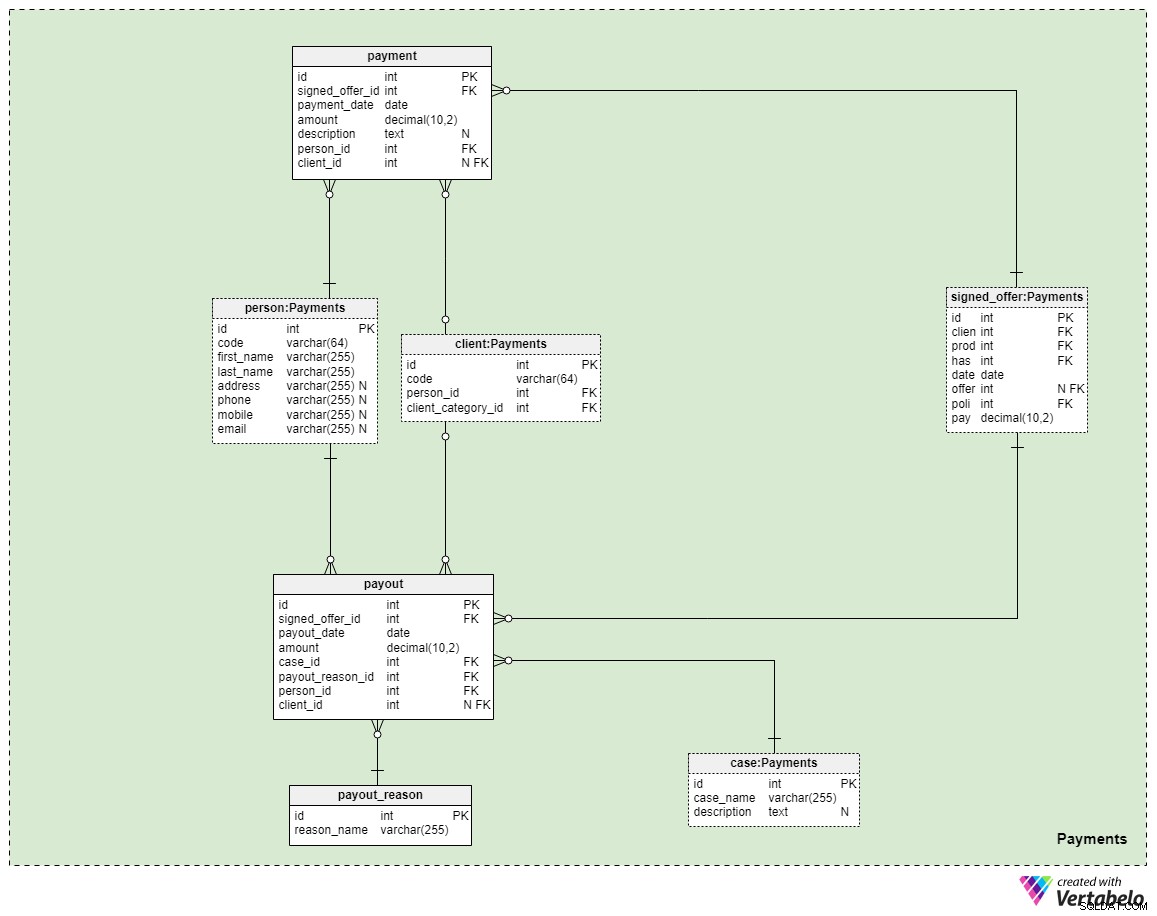
Le dernier domaine de notre modèle concerne les paiements. Ici, nous n'introduisons que trois nouveaux tableaux :payment , payout_reason , et payment .
Tous les paiements liés aux politiques sont stockés dans le payment table. Nous n'avons inclus ici que les attributs les plus importants :
signed_offer_id— référence à l'identifiant unique de l'offre signée (politique).payment_date— la date à laquelle ce paiement a été effectué.amount— le montant réel qui a été payé.description— une description facultative du paiement, sous forme textuelle.person_id— référence à l'identifiant unique de la personne qui a effectué le paiement. Notez que le client qui a signé l'offre n'est pas nécessairement la seule personne qui peut effectuer un paiement.client_id— référence à l'identifiant unique du client qui a effectué le paiement. Cet attribut contiendra une valeur uniquement si le client a lui-même effectué le paiement.
Les deux tableaux restants représentent peut-être la raison la plus importante pour laquelle nous payons une assurance-vie - que si quelque chose devait nous arriver, des paiements seraient versés aux membres de notre famille ou à nos partenaires de vie/d'affaires. La manière dont cela se produit dépend de votre situation et des conditions de la police spécifique que vous avez signée. Nous utiliserons deux tableaux simples pour couvrir ces cas.
Le premier est un dictionnaire intitulé payout_reason et présente une structure de dictionnaire classique. Mis à part l'attribut de clé primaire, nous n'avons qu'un seul attribut - le reason_name – qui stockera une liste de valeurs uniques indiquant pourquoi ce paiement a été effectué.
Le dernier tableau du modèle est le payment table. C'est très similaire au payment tableau, mais les différences les plus importantes sont indiquées ci-dessous :
payment_date— la date à laquelle le paiement a été effectué.case_id— référence à l'identifiant unique du cas ou de l'incident lié qui a déclenché le paiement. Cela doit correspondre à l'un des identifiants inclus dans la stratégie.payout_reason_id— référence au dictionnaire qui décrit plus en détail la raison du paiement. Bien que le cas de paiement soit plus court et plus général, la raison du paiement fournira des détails plus spécifiques sur ce qui s'est passé.person_idetclient_id— fait référence à la personne et au client liés au paiement, respectivement.
Résumé
Génial! Nous avons construit avec succès notre modèle de données d'assurance-vie. Avant de conclure notre discussion, il convient de noter qu'il y a beaucoup plus qui peut être couvert dans ce modèle. Dans cet article, nous voulions principalement couvrir les bases du modèle pour vous donner une idée de son apparence et de son fonctionnement. Voici quelques détails supplémentaires que l'on pourrait intégrer à un tel modèle de données :
- Les mises à niveau supplémentaires des polices ne sont pas couvertes par notre modèle actuel (par exemple, si vous souhaitez faire des offres annuelles pour les polices existantes, vous ne pourrez pas le faire avec cette structure). Nous devrions ajouter quelques tables supplémentaires pour stocker toutes les modifications de politique pour les offres présentées/signées.
- Tous les documents sont intentionnellement omis. Bien sûr, il y aura beaucoup de paperasse associée à une police d'assurance-vie particulière, en particulier pour le processus de signature et les paiements. Nous pourrions joindre des documents décrivant le statut du client au moment de la signature de la police et tout changement en cours de route, ainsi que tout document lié aux paiements.
- Ce modèle n'intègre pas la structure nécessaire au calcul du risque lié aux politiques. Nous devrions avoir tous les paramètres que nous devons tester et toutes les plages qui déterminent comment la valeur d'un client affecte le calcul global. Les résultats de ces calculs devraient être stockés pour chaque offre et politique signée.
- La structure de la facture est en réalité beaucoup plus complexe que ce que nous avons couvert dans le domaine des paiements. Nous n'avons même pas mentionné les comptes financiers dans notre modèle.
De toute évidence, le secteur de l'assurance est assez complexe. Nous n'avons abordé dans cet article qu'un modèle de données pour l'assurance-vie. Pouvez-vous imaginer comment ce modèle de données évoluerait si nous devions diriger une entreprise qui propose plusieurs types d'assurance différents ? Il faudrait certainement beaucoup de planification et de réflexion pour présenter un modèle de données organisé pour une telle entreprise.
Si vous avez des suggestions ou des idées pour améliorer notre modèle de données, n'hésitez pas à nous en faire part dans les commentaires ci-dessous !