Cet article montre comment SQL Server combine les informations de densité de plusieurs statistiques à une seule colonne, pour produire une estimation de cardinalité pour une agrégation sur plusieurs colonnes. Les détails sont, espérons-le, intéressants en eux-mêmes. Ils donnent également un aperçu de certaines des approches générales et des algorithmes utilisés par l'estimateur de cardinalité.
Considérez l'exemple de requête de base de données AdventureWorks suivant, qui répertorie le nombre d'articles d'inventaire de produits dans chaque casier sur chaque étagère de l'entrepôt :
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Le plan d'exécution estimé indique que 1 069 lignes sont lues à partir de la table, triées dans Shelf et Bin ordre, puis agrégé à l'aide d'un opérateur Stream Aggregate :
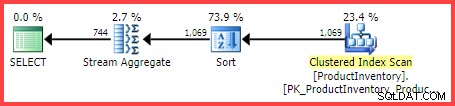
Plan d'exécution estimé
La question est, comment l'optimiseur de requête SQL Server est-il arrivé à l'estimation finale de 744 lignes ?
Statistiques disponibles
Lors de la compilation de la requête ci-dessus, l'optimiseur de requête créera des statistiques à une seule colonne sur le Shelf et Bin colonnes, si les statistiques appropriées n'existent pas déjà. Entre autres choses, ces statistiques fournissent des informations sur le nombre de valeurs de colonnes distinctes (dans le vecteur de densité) :
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Les résultats sont résumés dans le tableau ci-dessous (la troisième colonne est calculée à partir de la densité) :
| Colonne | Densité | 1 / Densité |
|---|---|---|
| Étagère | 0.04761905 | 21 |
| Bac | 0.01612903 | 62 |
Informations vectorielles sur la densité des étagères et des bacs
Comme le note la documentation, l'inverse de la densité est le nombre de valeurs distinctes dans la colonne. D'après les informations statistiques présentées ci-dessus, SQL Server sait qu'il y avait 21 éléments Shelf distincts. valeurs et 62 Bin distincts valeurs dans le tableau, lorsque les statistiques ont été collectées.
La tâche d'estimation du nombre de lignes produites par un GROUP BY La clause est triviale lorsqu'une seule colonne est impliquée (en supposant qu'il n'y a pas d'autres prédicats). Par exemple, il est facile de voir que GROUP BY Shelf produira 21 rangées ; GROUP BY Bin en produira 62.
Cependant, on ne sait pas immédiatement comment SQL Server peut estimer le nombre de (Shelf, Bin) distincts combinaisons pour notre GROUP BY Shelf, Bin requête. Pour poser la question d'une manière légèrement différente :étant donné 21 étagères et 62 bacs, combien y aura-t-il de combinaisons uniques d'étagères et de bacs ? Laissant de côté les aspects physiques et les autres connaissances humaines du domaine du problème, la réponse pourrait être n'importe où entre max(21, 62) =62 et (21 * 62) =1 302. Sans plus d'informations, il n'y a aucun moyen évident de savoir où présenter une estimation dans cette fourchette.
Pourtant, pour notre exemple de requête, SQL Server estime 744.312 lignes (arrondies à 744 dans la vue Plan Explorer) mais sur quelle base ?
Événement étendu d'estimation de cardinalité
La manière documentée d'examiner le processus d'estimation de la cardinalité consiste à utiliser l'événement étendu query_optimizer_estimate_cardinality (bien qu'il soit dans le canal "debug"). Lorsqu'une session collectant cet événement est en cours d'exécution, les opérateurs de plan d'exécution obtiennent une propriété supplémentaire StatsCollectionId qui relie les estimations individuelles des opérateurs aux calculs qui les ont produites. Pour notre exemple de requête, l'identifiant de collecte de statistiques 2 est lié à l'estimation de cardinalité pour le groupe par opérateur d'agrégation.
La sortie pertinente de l'événement étendu pour notre requête de test est :
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Il y a certainement des informations utiles là-bas.
Nous pouvons voir que la classe de calculateur de valeurs distinctes de feuille de plan (CDVCPlanLeaf ) a été utilisé, en utilisant des statistiques à une seule colonne sur Shelf et Bin comme entrées. L'élément de collection stats fait correspondre ce fragment à l'id (2) indiqué dans le plan d'exécution, qui indique l'estimation de cardinalité de 744.31 , et plus d'informations sur les identifiants d'objets de statistiques utilisés également.
Malheureusement, rien dans la sortie de l'événement ne dit exactement comment la calculatrice est arrivée au chiffre final, ce qui nous intéresse vraiment.
Combiner des comptages distincts
En suivant un itinéraire moins documenté, nous pouvons demander un plan estimé pour la requête avec des indicateurs de trace 2363 et 3604 activé :
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Cela renvoie les informations de débogage à l'onglet Messages dans SQL Server Management Studio. La partie intéressante est reproduite ci-dessous :
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Cela montre à peu près les mêmes informations que l'événement étendu dans un format (sans doute) plus facile à consommer :
- L'opérateur relationnel d'entrée pour calculer une estimation de cardinalité pour (
LogOp_GbAgg– regroupement logique par agrégat) - Le calculateur utilisé (
CDVCPlanLeaf) et les statistiques d'entrée - Les détails de la collecte de statistiques résultante
La nouvelle information intéressante est la partie sur l'utilisation de la cardinalité ambiante pour combiner des comptages distincts .
Cela montre clairement que les valeurs 21, 62 et 1069 ont été utilisées, mais (frustrant) toujours pas exactement quels calculs ont été effectués pour arriver au 744.312 résultat.
Au débogueur !
Attacher un débogueur et utiliser des symboles publics nous permet d'explorer en détail le chemin de code suivi lors de la compilation de l'exemple de requête.
L'instantané ci-dessous montre la partie supérieure de la pile d'appels à un point représentatif du processus :
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Il y a quelques détails intéressants ici. En travaillant de bas en haut, nous voyons que la cardinalité est dérivée à l'aide du CE mis à jour (CCardFrameworkSQL12 ) disponible dans SQL Server 2014 et versions ultérieures (le CE d'origine est CCardFrameworkSQL7 ), pour l'opérateur logique de regroupement par agrégat (CLogOp_GbAgg ).
Le calcul de la cardinalité distincte implique la combinaison (munging) de plusieurs entrées, en utilisant un échantillonnage sans remplacement.
La référence à H et un logarithme (naturel) dans la deuxième méthode à partir du haut montre l'utilisation de l'entropie de Shannon dans le calcul :
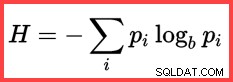
Entropie de Shannon
L'entropie peut être utilisée pour estimer la corrélation informationnelle (information mutuelle) entre deux statistiques :
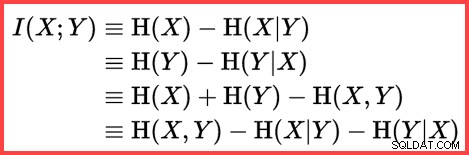
Informations mutuelles
En rassemblant tout cela, nous pouvons construire un script de calcul T-SQL correspondant à la façon dont SQL Server utilise l'échantillonnage sans remplacement, l'entropie de Shannon et les informations mutuelles pour produire l'estimation finale de la cardinalité.
Nous commençons par les nombres d'entrée (cardinalité ambiante et nombre de valeurs distinctes dans chaque colonne) :
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; La fréquence de chaque colonne est le nombre moyen de lignes par valeur distincte :
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; L'échantillonnage sans remplacement (SWR) consiste simplement à soustraire le nombre moyen de lignes par valeur distincte (fréquence) du nombre total de lignes :
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Calculez les entropies (N log N) et les informations mutuelles :
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Maintenant que nous avons estimé à quel point les deux ensembles de statistiques sont corrélés, nous pouvons calculer l'estimation finale :
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Le résultat du calcul est 744,311823994677, soit 744,312 arrondi à trois décimales.
Pour plus de commodité, voici l'intégralité du code en un seul bloc :
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Réflexions finales
L'estimation finale est imparfaite dans ce cas :l'exemple de requête renvoie en fait 441 lignes.
Pour obtenir une meilleure estimation, nous pourrions fournir à l'optimiseur de meilleures informations sur la densité du Bin et Shelf colonnes à l'aide d'une statistique multicolonne. Par exemple :
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Avec cette statistique en place (soit telle qu'elle est donnée, soit comme effet secondaire de l'ajout d'un index multicolonne similaire), l'estimation de cardinalité pour l'exemple de requête est tout à fait correcte. Il est cependant rare de calculer une agrégation aussi simple. Avec des prédicats supplémentaires, la statistique multicolonne peut être moins efficace. Néanmoins, il est important de se rappeler que les informations de densité supplémentaires fournies par les statistiques multicolonnes peuvent être utiles pour les agrégations (ainsi que les comparaisons d'égalité).
Sans statistique multicolonne, une requête agrégée avec des prédicats supplémentaires peut toujours être en mesure d'utiliser la logique essentielle présentée dans cet article. Par exemple, au lieu d'appliquer la formule à la cardinalité de la table, elle peut être appliquée aux histogrammes d'entrée étape par étape.
Contenu connexe :Estimation de la cardinalité d'un prédicat sur une expression COUNT



