Être en bonne santé et en forme est un mode de vie, pas une mode. Les personnes qui réalisent la valeur de la santé en font une priorité, en conservant des enregistrements de tous leurs faits liés à la forme physique. Dans cet article, nous examinerons la conception de la base de données derrière une application de santé et de remise en forme.
Il existe de nombreuses applications qui permettent aux utilisateurs de consigner leurs informations de santé et de forme physique. Quelques grands acteurs comme Apple, Google et Microsoft ont lancé leurs propres API de développement spécifiquement pour ce marché. Par exemple, Google a "Fit" et Microsoft a "HealthVault".
Dans cet article, j'expliquerai le modèle de données derrière une application de dossiers de santé. Tout d'abord, discutons exactement de ce que nous attendons d'une telle application.
Exigences du projet pour une application d'informations sur la santé
Voici quelques fonctionnalités qu'une application d'informations sur la santé doit prendre en charge :
- Les utilisateurs peuvent créer un compte et stocker des informations de santé pour plusieurs profils, c'est-à-dire qu'un individu peut stocker des informations de santé pour tous les membres de sa famille.
- Les utilisateurs peuvent enregistrer l'intégralité de leurs antécédents médicaux, y compris les vaccinations, les résultats de laboratoire antérieurs, les allergies et les antécédents médicaux familiaux .
- Les utilisateurs peuvent stocker diverses mesures de santé et de forme physique, telles que la glycémie (glycémie), la pression artérielle, la composition corporelle et les dimensions, y compris l'indice de masse corporelle (IMC), le cholestérol, la taille, le poids, la santé reproductive, etc.
- Les informations peuvent être enregistrées à l'aide de diverses méthodes et unités de mesure . Par exemple, la glycémie peut être mesurée en mg/dL ou mmol/L.
- Il n'y a aucune limite quant à la quantité d'informations que les utilisateurs peuvent stocker.
- Le système tiendra également compte des normes de santé acceptées, telles que la pression artérielle ou les chiffres de l'IMC, et alertera les utilisateurs si leurs chiffres se situent en dehors des plages "sûres" ou "normales".
- Les utilisateurs peuvent également choisir des informations (telles que la glycémie, la taille, le poids, etc.) à afficher sur leur tableau de bord personnel. De cette façon, ils peuvent surveiller tout ce dont ils ont besoin.
Plutôt que de simplement expliquer ce que fait chaque section et tableau dans le modèle de données, répondons à quelques questions à ce sujet. La fonction des différentes tables deviendra claire au fur et à mesure.
Tout d'abord, vous pouvez consulter le modèle de données complet si vous le souhaitez.
Le modèle de données
Répondre aux questions sur le modèle de données d'informations sur la santé
Comment les utilisateurs peuvent-ils stocker les informations médicales de tous les membres de leur famille individuellement ?
Parlons d'abord de la gestion des comptes et des profils . Ceci peut être réalisé en ayant deux tables différentes; un (user_account ) pour enregistrer les détails des personnes qui s'inscrivent à l'application, et un (user_profile ) pour enregistrer les détails de tous les différents profils créés par un utilisateur enregistré. Les gens peuvent créer un certain nombre de profils - par ex. un pour chacun des membres de leur famille.
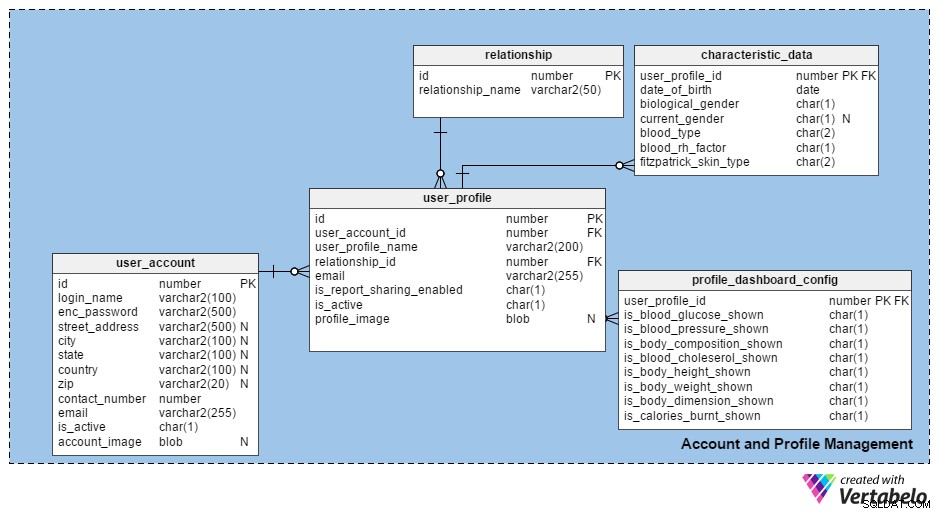
Regardons les différentes tables qui rendent cela possible.
Le user_account table contient des informations de base sur la personne qui s'inscrit à l'application. Ses colonnes sont :
id–Une colonne de clé de substitution pour cette table qui identifie chaque utilisateur de manière unique.login_name– Le nom ou autre ID que l'utilisateur choisit comme nom de connexion. Une contrainte unique doit être imposée sur cette colonne pour s'assurer que chaque nom de connexion est différent.enc_password– Le mot de passe du compte sélectionné par l'utilisateur, sous forme cryptée.- colonnes d'adresse – Stocke l'adresse et les coordonnées des utilisateurs au moment de l'inscription. Ces colonnes incluent
street_address,city,state,country, etzip. Étant donné que ces champs sont facultatifs dans le processus d'inscription, j'ai conservé ces colonnes comme nullables. contact_numberetemail- Stocke le numéro de contact de l'utilisateur (c'est-à-dire le numéro de téléphone) et son adresse e-mail. Ces champs font également partie du processus d'inscription, mais ils ne sont pas nullables.is_active– Contient soit un « Y » soit un « N » pour indiquer si un compte est actuellement actif.account_image– Les utilisateurs sont autorisés à télécharger leurs propres images. Puisqu'un utilisateur peut télécharger zéro ou (max) une image par compte, il s'agit d'une colonne de type BLOB acceptant les valeurs nulles.
Le user_profile table stocke les détails de tous les profils créés par les utilisateurs enregistrés. Les colonnes de ce tableau sont :
id– Un numéro unique attribué à chaque nouveau profil.user_account_id– Indique quel utilisateur a créé le profil.user_profile_name– Stocke le nom de la personne dans le profil. (Nous appellerons cette personne la "personne du profil" et l'utilisateur qui crée les profils le "titulaire du compte".)relationship_id– Indique la relation entre le titulaire du compte et la personne du profil. Cette colonne fait référence à larelationshiptable, qui contient tous les types de relations possibles (comme self , mère , père , sœur , frère , fils , fille , animal de compagnie , etc.).email- Cette colonne contient l'adresse e-mail de la personne du profil. Des rapports ou d'autres informations seraient partagés avec eux via cet e-mail ; des informations seraient également envoyées au titulaire du compte. Par exemple, si Melissa créait un profil pour sa fille Eva, les informations d'Eva seraient envoyées à l'e-mail de Melissa et éventuellement à l'e-mail d'Eva - voir ci-dessous.is_report_sharing_enabled– Les rapports sont toujours partagés avec le titulaire du compte, mais il est facultatif de partager ces données avec la personne du profil. Cette colonne indique si les informations seront partagées avec la personne du profil.is_active– Identifie si un profil est actuellement actif. Il s'agit d'une fonction de suppression réversible en cas de suppression accidentelle de profils.profile_image– Stocke une image de la personne du profil. Cet attribut est facultatif et donc nullable.
Les characteristic_data Le tableau contient des détails de profil individuels (comme le groupe sanguin) qui ne changent jamais au fil du temps. Toutes les colonnes de ce tableau sont explicites sauf fitzpatrick_skin_type , qui classe la nature de la peau de I (brûle toujours, ne bronze jamais) à VI (ne brûle jamais, ne change pas d'aspect en bronzant).
J'ai ajouté deux colonnes pour le sexe ; biological_gender signifie son sexe au moment de la naissance, et current_gender indique le sexe actuel de la personne du profil. Cette deuxième colonne ne s'applique qu'aux personnes transgenres, c'est pourquoi je l'ai gardée nullable.
Quelles informations vitales peuvent être stockées dans ce système ? Comment est-il stocké ?
Passons maintenant à la gestion des données de santé . La composition corporelle, les taux de glycémie et les dimensions corporelles sont stockés dans des tableaux séparés. Cependant, les gens peuvent entrer plus d'un type d'informations à la fois, nous utilisons donc le body_vitals_log tableau pour garder une trace des informations enregistrées dans un profil et du moment où elles sont saisies.

Toutes les statistiques vitales sont conservées dans les tableaux suivants :
body_composition- Stocke des détails sur divers pourcentages de composition corporelle comme la graisse, la masse maigre, les os ou l'eau. Il contient également les valeurs d'IMC (indice de masse corporelle) pour les individus.blood_cholesterol– Contient les détails du cholestérol comme le LDL, le HDL, les triglycérides et le total.body_dimension– Enregistre les dimensions de différentes zones du corps, telles que les mesures de la taille ou de la poitrine.body_weight– Stocke les valeurs du poids corporel.body_height– Contient des valeurs pour la taille d'une personne.blood_pressure– Contient les numéros de tension artérielle (systolique et diastolique).blood_glucose– Enregistre les taux de glycémie.
La plupart des colonnes des tableaux ci-dessus sont explicites, à quelques exceptions près. Vous remarquerez quelques colonnes supplémentaires comme measurement_method_id , compare_to_normal_id , measurement_unit_id et measurement_context dans presque chacun de ces tableaux. J'expliquerai ces colonnes plus tard.
Le body_vitals_log garde une trace des informations enregistrées à un moment donné pour un profil. Les colonnes de ce tableau sont :
user_profile_id– Indique quel profil enregistre les informations.dt_created– Stocke la date et l'heure de saisie des informations.data_source_id– Signifie la source des données, comme un manuel, un appareil électronique, etc.- IDs de diverses statistiques vitales - J'ai gardé toutes ces colonnes nullables, car les utilisateurs sont autorisés à enregistrer un ou plusieurs éléments à la fois. Tous les utilisateurs ne voudront pas suivre les mêmes statistiques de santé.
Comment pouvons-nous faire fonctionner le système dans différentes régions ?
Certaines informations sont mesurées dans différentes unités dans divers domaines. Par exemple, le poids corporel est mesuré en kilogrammes en Asie, mais il est mesuré en livres en Amérique du Nord. Donc, pour que cela fonctionne dans notre base de données, nous avons besoin d'un moyen de suivre les unités de mesure.
id– Sert de clé primaire de cette table, et c'est celle à laquelle les autres tables se réfèrent.measurement_parameter– Indique le type d'informations vitales (telles que le poids, la taille, la tension artérielle, etc.) qu'une unité mesure.unit_name– Stocke le nom de l'unité. Pensez à kilogramme et livre pour le poids, mg/dL et mmol/L pour la glycémie.
Comment les gens sauront-ils si leurs chiffres sont bons ?
Notre système n'est pas d'une grande aide s'il n'alerte pas les gens sur les risques ou les vulnérabilités pour la santé. Nous activons cette fonction en ajoutant le comparison_to_normal_id colonne dans tous les tableaux de données d'informations vitales.
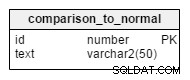
Lorsqu'une nouvelle information vitale est enregistrée dans le système, les enregistrements sont comparés à leurs valeurs de référence correspondantes et cette colonne est définie en conséquence.
Les valeurs possibles pour ce tableau sont :
| Je | Texte |
|---|---|
| 1 | Je ne sais pas |
| 2 | Beaucoup plus bas |
| 3 | Inférieur |
| 4 | Normal |
| 5 | Supérieur |
| 6 | Beaucoup plus haut |
Les utilisateurs peuvent-ils enregistrer le moment où les mesures ont été prises ?
Par exemple, les utilisateurs peuvent avoir besoin d'indiquer quand leur glycémie a été mesurée, c'est-à-dire avant ou après un repas. Ou ils peuvent se peser et enregistrer les résultats avant et après l'exercice. Pour faciliter cela, j'ai ajouté une colonne, measurement_context , dans les tables d'informations vitales qui peuvent nécessiter des informations contextuelles. Certaines valeurs possibles pour cette colonne sont présentées ci-dessous :
| Avant le petit déjeuner |
| Après le petit-déjeuner |
| Avant le déjeuner |
| Après le déjeuner |
| Avant le dîner |
| Après le dîner |
| Avant l'exercice |
| Après l'exercice |
| Jeûne |
| Non-jeûne |
| Après le repas |
| Avant le repas |
| Avant l'heure du coucher |
Que faire si une personne est diabétique et doit surveiller sa glycémie ?
Le système que je propose aura un tableau de bord qui pourra afficher les statistiques vitales sous forme graphique. Les utilisateurs sont autorisés à choisir ce qu'ils aimeraient voir sur leur tableau de bord de profil, et chaque profil a son propre tableau de bord. Les titulaires de compte sont autorisés à voir tous les tableaux de bord de profil qu'ils ont créés.
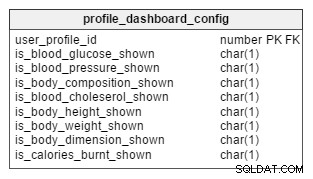
J'ai ajouté une colonne CHAR(1) pour chaque paramètre pouvant être affiché sur un tableau de bord. Par défaut, toutes les colonnes seraient remplies avec 'N' (l'affichage est désactivé) lorsqu'un nouveau profil est créé. Les utilisateurs peuvent modifier ultérieurement la configuration de leur tableau de bord à partir d'une option de l'interface utilisateur de l'application.
Comment ce système aide-t-il les gens à rester en forme ?
En d'autres termes, nous parlons de stockage de données de fitness . Outre les informations sur la santé, le système permet également à leurs utilisateurs d'enregistrer des informations sur leurs routines de fitness et d'exercice.
Le activity_log table est la table principale de ce domaine. Il capture des détails sur chaque type de profil d'activité que les personnes effectuent.
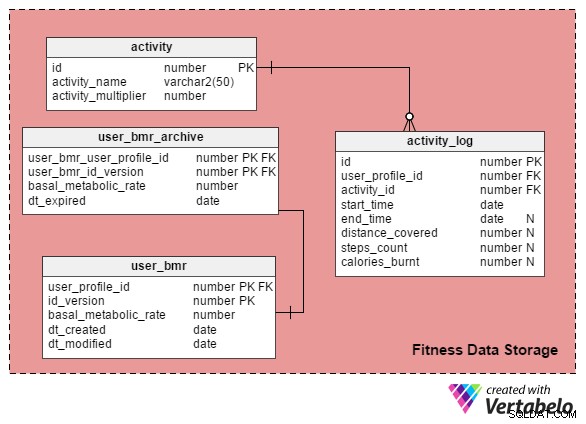
Chaque activité peut être mesurée par un ou plusieurs des trois paramètres suivants :
- Heure de début et de fin – Les activités comme faire du sport ou jouer à des jeux, faire la queue, etc. sont mesurées en termes d'heure de début et de fin. Cela se fait via le
start_timeetend_timecolonnes dansactivity_log. - Distance parcourue – Des activités comme la course à pied ou le vélo sont mesurées en termes de distance parcourue. Ceci est stocké dans la
distance_coveredcolonne. - Nombre de pas – Des activités comme la marche sont mesurées en termes de nombre de pas, et les valeurs sont stockées dans le
steps_countcolonne.
Vous devez vous demander pourquoi les calories_burnt la colonne est dans le activity_log table. Comme son nom l'indique, cette colonne contient la valeur des calories brûlées par la personne du profil lors d'une activité particulière. J'expliquerai comment nous pouvons calculer ces valeurs dans une section ultérieure.
J'ai créé une table nommée activity pour garder une liste de toutes les activités possibles. Les colonnes de ce tableau sont :
id– Attribue un numéro d'identification unique à chaque activité.activity_name– Stocke les noms d'activité.activity_multiplier– Cette colonne joue un rôle clé dans le calcul du nombre de calories brûlées par les personnes pratiquant des activités.
Comment calculez-vous les calories brûlées pour chaque activité ?
Pour comprendre comment calculer les calories brûlées, nous devons d'abord comprendre le BMR ou le taux métabolique de base d'une personne. Cela nous indique combien de calories un corps brûle au repos. Le BMR de chaque personne dépend de son sexe, de son âge, de son poids et de sa taille. Du point de vue de la modélisation des données, un BMR est une dimension qui évolue lentement et, en tant que telle, elle continue de changer avec le temps. Nous stockerons les dernières valeurs BMR individuelles dans le user_bmr table.
Il existe différentes méthodes utilisées pour calculer les valeurs BMR :
Méthode n° 1 :méthode Harris-Benedict
BMR Hommes :66 + (6,23 X poids en livres) + (12,7 X taille en pouces) – (6,8 X âge)
BMR Femmes :655 + (4,35 X poids en livres) + (4,7 X taille en pouces) – (4,7 X âge)
Méthode n° 2 :méthode Katch-McArdle
BMR (Hommes + Femmes) :370 + (21,6 * Masse maigre en kilogramme)
Masse maigre =poids en kilogramme – (poids en kilogramme * pourcentage de graisse corporelle
Nous pouvons utiliser le BMR d'une personne et le multiplicateur d'activité mentionné ci-dessus pour savoir combien de calories une personne brûle lors d'une activité donnée. La formule est :
Calories brûlées =multiplicateur d'activité * BMR
Remarque :Les deux méthodes de calcul BMR ci-dessus utilisent les mêmes valeurs de multiplicateur pour les activités. Pour plus d'informations, consultez cet article.
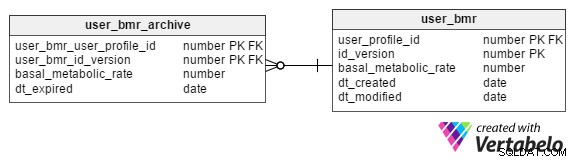
Pouvons-nous conserver les valeurs BMR historiques des profils ?
Oui. Nous pouvons archiver les valeurs BMR dans le user_bmr_archive table.
Nous commençons par ajouter une colonne, id_version , au user_bmr table. Nous continuons d'augmenter cette valeur de 1 chaque fois que la valeur BMR d'une personne de profil est mise à jour.
Le user_bmr_archive table est presque une réplique du user_bmr table. La seule différence est qu'il a un dt_expired colonne au lieu de dt_created et dt_modified Colonnes. Le dt_expired la colonne stocke la date à laquelle la version est devenue invalide, c'est-à-dire lorsque la valeur BMR est mise à jour dans user_bmr .
Que se passe-t-il si les utilisateurs souhaitent conserver une trace de leurs vaccinations, de leurs antécédents médicaux familiaux et de leurs allergies ?
Ce système exploite les tableaux suivants pour donner aux utilisateurs la possibilité de stocker des informations de santé supplémentaires.
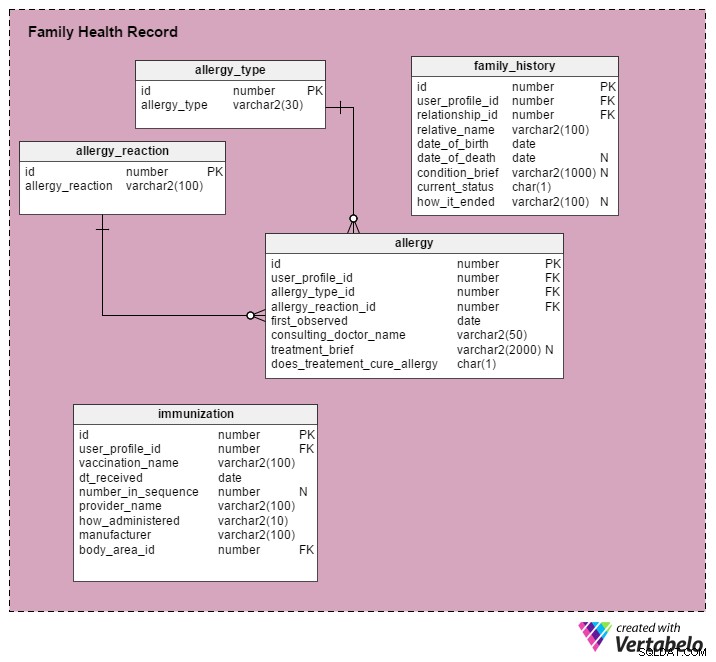
La immunization table stocke des détails sur les vaccinations reçues par les personnes du profil. Après l'exemple, vous verrez une brève description des colonnes que contient ce tableau :
Exemple :John Soo a reçu la deuxième des trois doses d'un vaccin contre l'hépatite B. Il a été administré par le Dr David Moore le 28 novembre 2016. La vaccination a été administrée par une injection dans la main gauche. Il est fabriqué par Cipla (une société pharmaceutique).
id– La clé primaire de cette tableuser_profile_id– Fait référence auuser_profile_IDde John Soovaccination_name– "Hépatite B"dt_received– « 28 novembre 2016 »number_in_sequence– "02"body_area_id– L'identifiant de la main gauche, référé depuis lebody_areatableauprovider_name– « Dr. David Moore"how_administered– "Injecté" (d'autres valeurs possibles incluent spray nasal, comprimé, gouttes, sirop )manufacturer– "Cipla"
L'allergy table stocke des détails sur les allergies subies par les personnes du profil. Vous trouverez ci-dessous la liste des colonnes, avec les valeurs pertinentes données pour chacune selon l'exemple :
Exemple :Alison D'Souza tousse lorsqu'elle mange du yaourt. Elle a eu cette réaction pour la première fois à l'âge de 8 ans. Elle consulte le Dr Bill Smith, qui lui prescrit des médicaments et conseille certaines précautions. Cette allergie persiste toujours, mais son intensité est plus faible maintenant.
id– La clé primaire de la tableuser_profile_id– Rfait référence auuser_profile_idd'Alison D'Souzaallergy_type_id– Fait référence à l'identifiant du type d'allergie "Aliments" dans leallergy_typetable. (Leallergy_typele tableau définit divers types d'allergies comme les aliments, les médicaments, l'environnement, les animaux, les plantes, etc.)allergy_reaction_id– Fait référence à l'identifiant de la réaction allergique "Toux" dans leallergy_reactiontableau.first_observed– La date à laquelle cette réaction a été observée pour la première fois, c'est-à-dire quand Alison avait 8 ans.consulting_doctor_name– « Dr. Bill Smith"treatment_brief– Une brève description des médicaments prescrits et des précautions recommandées.does_treatment_cure_allergy– « Partiellement guéri. Diminution de l'intensité de la réaction."
Le family_history table stocke des détails sur les antécédents médicaux familiaux des utilisateurs. Encore une fois, nous avons répertorié les colonnes et le type d'informations qui y seraient stockées sur la base de l'exemple suivant.
Exemple :Lisa, la mère de Diana, est atteinte de la maladie de Parkinson (un trouble neurologique). Elle a suivi un traitement, mais n'a obtenu aucune amélioration tangible.
id– la clé primaire de la tableuser_profile_id– l'user_profile_IDde Diana à partir duuser_profiletableauRelationship_id– L'identifiant "mère" de larelationshiptableauRelative_name– "Lisa"Date_of_birth– date de naissance de LisaDate_of_death– NULL (Lisa est toujours en vie et se bat avec acharnement contre la maladie.)Condition_brief– Une brève description de comment, quand et où la condition a commencé, les consultations, tout soulagement, etc.Current_status– ‘Actuel’ (Les autres statuts possibles sont ‘Intermittent’ et ‘Passé’.)How_it_ended– NUL
Qu'ajouteriez-vous à ce modèle de données ?
Le système permet aux gens de savoir combien de calories ils brûlent en poursuivant diverses activités, mais il ne suit pas le nombre de calories qu'ils consomment ni la valeur nutritive de leurs choix alimentaires. De plus, le système leur permet d'enregistrer quotidiennement leurs données de condition physique, mais il ne leur permet pas de se fixer un objectif, de formuler un plan et de suivre leurs progrès afin qu'ils restent motivés.
Devrions-nous envisager d'y intégrer ces fonctionnalités ? Quelles modifications doivent être apportées pour ajouter ces fonctionnalités ?
Faites-nous part de vos idées !