Dans mon dernier article, j'ai démontré qu'à de petits volumes, un TVP à mémoire optimisée peut offrir des avantages de performances substantiels aux modèles de requêtes typiques.
Pour tester à une échelle légèrement supérieure, j'ai fait une copie du SalesOrderDetailEnlarged table, que j'avais étendue à environ 5 000 000 de lignes grâce à ce script de Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
J'ai également créé trois versions en mémoire de cette table, chacune avec un nombre de compartiments différent (à la recherche d'un "sweet spot") - 16 384, 131 072 et 1 048 576. (Vous pouvez utiliser des nombres plus arrondis, mais ils sont de toute façon arrondis à la prochaine puissance de 2.) Exemple :
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Remarquez que j'ai changé la taille du seau de l'exemple précédent (256). Lors de la création de la table, vous souhaitez choisir le "sweet spot" pour la taille du compartiment - vous souhaitez optimiser l'index de hachage pour les recherches de points, ce qui signifie que vous souhaitez autant de compartiments que possible avec le moins de lignes possible dans chaque compartiment. Bien sûr, si vous créez ~ 5 millions de buckets (puisque dans ce cas, ce n'est peut-être pas un très bon exemple, il y a ~ 5 millions de combinaisons uniques de valeurs), vous devrez faire face à des compromis en matière d'utilisation de la mémoire et de récupération de place. Cependant, si vous essayez de mettre environ 5 millions de valeurs uniques dans 256 compartiments, vous rencontrerez également des problèmes. En tout cas, cette discussion dépasse largement le cadre de mes tests pour ce post.
Pour tester par rapport à la table standard, j'ai créé des procédures stockées similaires à celles des tests précédents :
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Alors d'abord, pour regarder les plans pour, disons, 1 000 lignes insérées dans les variables de table, puis exécuter les procédures :
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Cette fois, nous voyons que dans les deux cas, l'optimiseur a choisi une recherche d'index clusterisé sur la table de base et une jointure de boucles imbriquées sur le TVP. Certaines mesures de coûts sont différentes, mais sinon, les plans sont assez similaires :
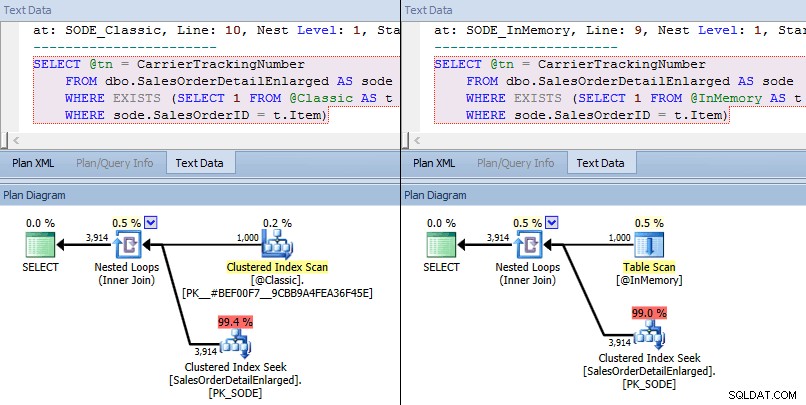 Plans similaires pour la TVP en mémoire par rapport à la TVP classique à plus grande échelle
Plans similaires pour la TVP en mémoire par rapport à la TVP classique à plus grande échelle
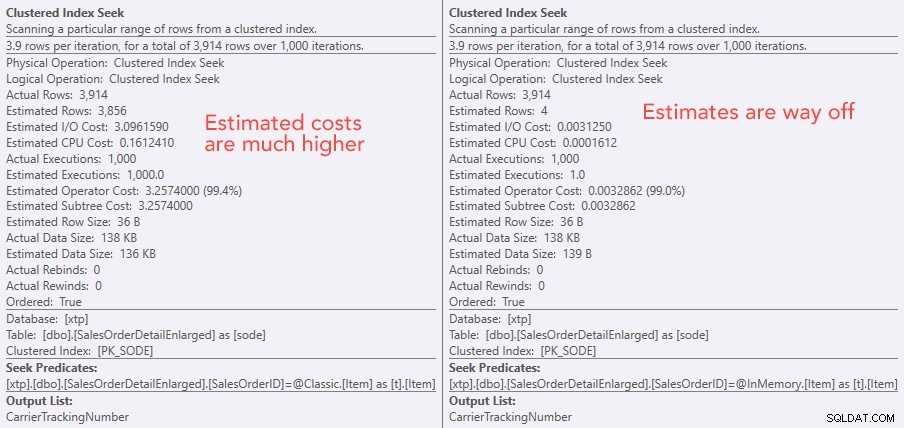 Comparaison des coûts d'opérateur de recherche - Classique à gauche, In-Memory à droite
Comparaison des coûts d'opérateur de recherche - Classique à gauche, In-Memory à droite
La valeur absolue des coûts donne l'impression que le TVP classique serait beaucoup moins efficace que le TVP In-Memory. Mais je me demandais si cela serait vrai dans la pratique (d'autant plus que le chiffre du nombre estimé d'exécutions à droite semblait suspect), alors bien sûr, j'ai effectué quelques tests. J'ai décidé de vérifier par rapport aux valeurs 100, 1 000 et 2 000 à envoyer à la procédure.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Les résultats de performance montrent qu'à un plus grand nombre de recherches de points, l'utilisation d'un TVP en mémoire entraîne des rendements légèrement décroissants, étant légèrement plus lents à chaque fois :
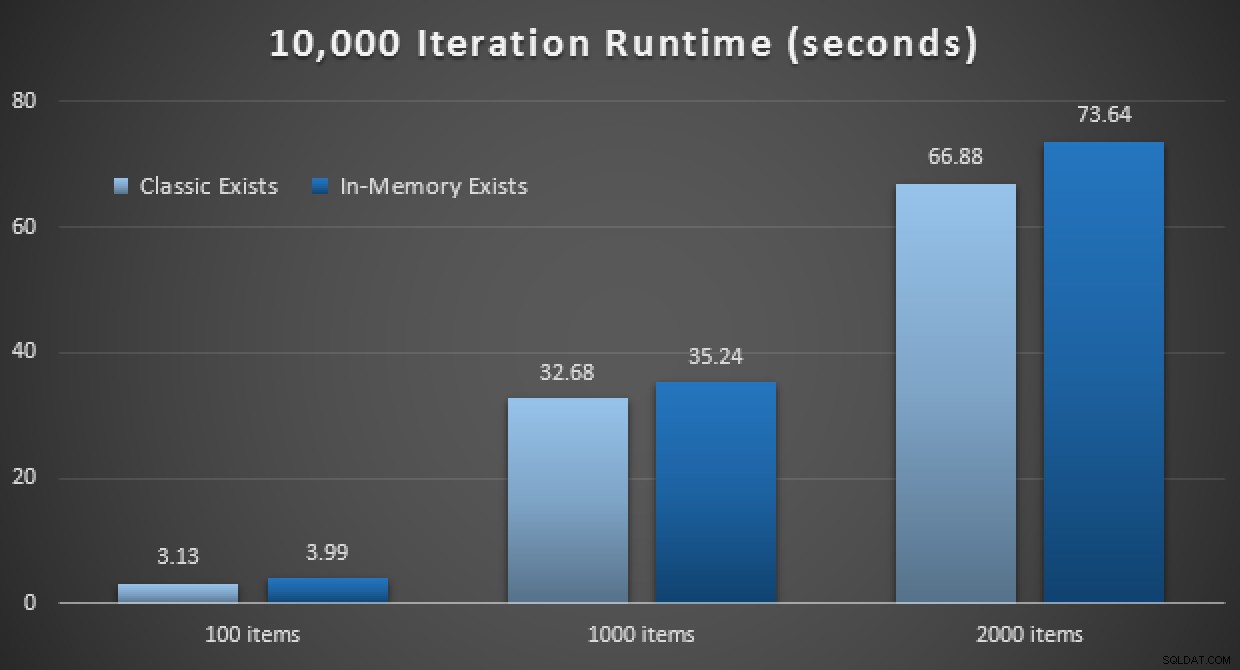
Résultats de 10 000 exécutions à l'aide de TVP classiques et en mémoire
Ainsi, contrairement à l'impression que vous avez pu tirer de mon post précédent, utiliser un TVP en mémoire n'est pas forcément bénéfique dans tous les cas.
Plus tôt, j'ai également examiné les procédures stockées compilées en mode natif et les tables en mémoire, en combinaison avec les TVP en mémoire. Cela pourrait-il faire une différence ici? Spoiler :absolument pas. J'ai créé trois procédures comme celle-ci :
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Autre spoiler :je n'ai pas pu exécuter ces 9 tests avec un nombre d'itérations de 10 000 – cela a pris beaucoup trop de temps. Au lieu de cela, j'ai parcouru et exécuté chaque procédure 10 fois, exécuté cet ensemble de tests 10 fois et pris la moyenne. Voici les résultats :
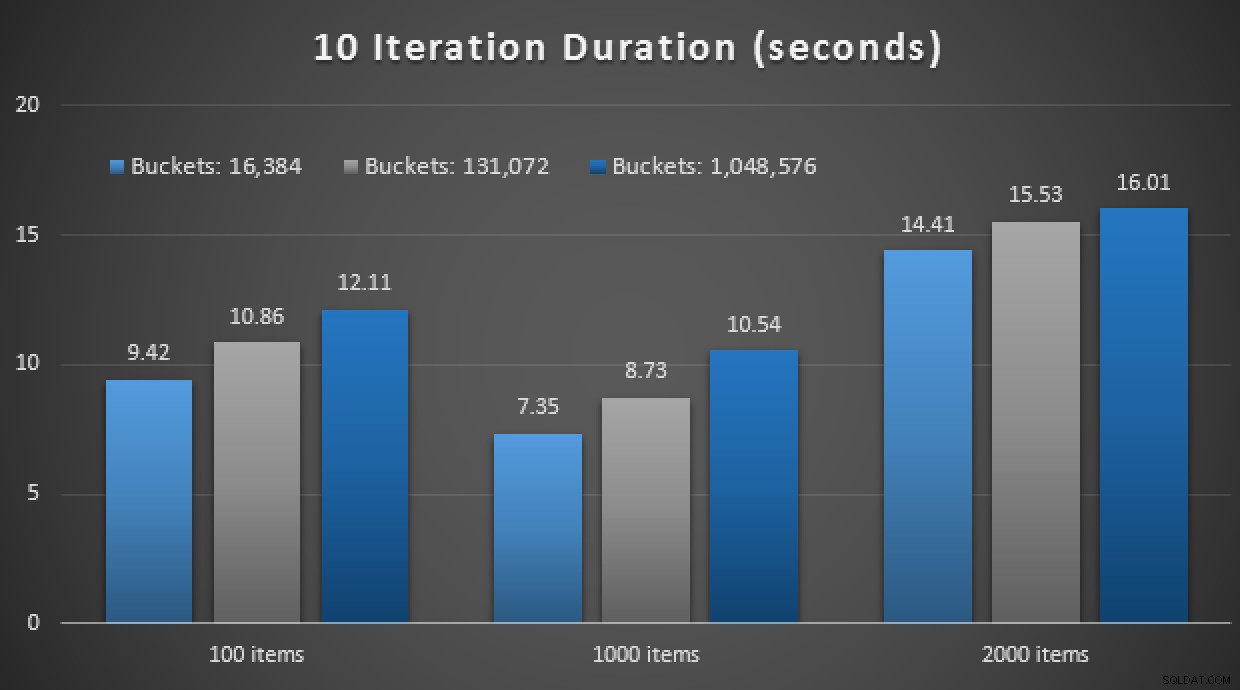
Résultats de 10 exécutions à l'aide de TVP en mémoire et d'un stockage compilé en mode natif procédures
Dans l'ensemble, cette expérience a été plutôt décevante. Rien qu'en regardant l'ampleur de la différence, avec une table sur disque, l'appel de procédure stockée moyen a été effectué en moyenne 0,0036 secondes. Cependant, lorsque tout utilisait des technologies en mémoire, l'appel de procédure stockée moyen était de 1,1662 secondes. Aïe . Il est fort probable que je viens de choisir un mauvais cas d'utilisation pour la démonstration dans l'ensemble, mais cela semblait à l'époque être un "premier essai" intuitif
Conclusion
Il y a beaucoup plus à tester autour de ce scénario, et j'ai d'autres articles de blog à suivre. Je n'ai pas encore identifié le cas d'utilisation optimal pour les TVP en mémoire à plus grande échelle, mais j'espère que ce message servira de rappel que même si une solution semble optimale dans un cas, il n'est jamais sûr de supposer qu'elle est également applicable à différents scénarios. C'est exactement ainsi que l'OLTP en mémoire doit être abordé :comme une solution avec un ensemble restreint de cas d'utilisation qui doivent absolument être validés avant d'être mis en production.