Dans la partie 5 de ma série sur les expressions de table, j'ai fourni la solution suivante pour générer une série de nombres à l'aide de CTE, d'un constructeur de valeur de table et de jointures croisées :
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Il existe de nombreux cas d'utilisation pratiques pour un tel outil, notamment la génération d'une série de valeurs de date et d'heure, la création d'exemples de données, etc. Reconnaissant le besoin commun, certaines plates-formes fournissent un outil intégré, tel que la fonction generate_series de PostgreSQL. Au moment de la rédaction de cet article, T-SQL ne fournit pas un tel outil intégré, mais on peut toujours espérer et voter pour qu'un tel outil soit ajouté à l'avenir.
Dans un commentaire sur mon article, Marcos Kirchner a mentionné qu'il avait testé ma solution avec différentes cardinalités de constructeur de valeur de table et obtenu des temps d'exécution différents pour les différentes cardinalités.
J'ai toujours utilisé ma solution avec une cardinalité de constructeur de valeur de table de base de 2, mais le commentaire de Marcos m'a fait réfléchir. Cet outil est si utile que nous, en tant que communauté, devrions unir nos forces pour essayer de créer la version la plus rapide possible. Tester différentes cardinalités de table de base n'est qu'une dimension à essayer. Il pourrait y en avoir beaucoup d'autres. Je vais vous présenter les tests de performances que j'ai effectués avec ma solution. J'ai principalement expérimenté avec différentes cardinalités de constructeur de valeurs de table, avec un traitement en série ou en parallèle, et avec un traitement en mode ligne ou en mode batch. Cependant, il se pourrait qu'une solution entièrement différente soit encore plus rapide que ma meilleure version. Alors, le défi est lancé ! J'appelle tous les jedi, padawan, sorciers et apprentis. Quelle est la solution la plus performante que vous puissiez évoquer ? Avez-vous le courage de battre la solution la plus rapide publiée jusqu'à présent ? Si tel est le cas, partagez la vôtre en commentaire de cet article et n'hésitez pas à améliorer toute solution publiée par d'autres.
Exigences :
- Mettez en œuvre votre solution en tant que fonction table inline (iTVF) nommée dbo.GetNumsYourName avec les paramètres @low AS BIGINT et @high AS BIGINT. À titre d'exemple, voyez ceux que je soumets à la fin de cet article.
- Vous pouvez créer des tables de support dans la base de données utilisateur si nécessaire.
- Vous pouvez ajouter des conseils si nécessaire.
- Comme mentionné, la solution doit prendre en charge les délimiteurs de type BIGINT, mais vous pouvez supposer une cardinalité de série maximale de 4 294 967 296.
- Pour évaluer les performances de votre solution et la comparer avec d'autres, je vais la tester avec la plage de 1 à 100 000 000, avec l'option Supprimer les résultats après exécution activée dans SSMS.
Bonne chance à nous tous ! Que la meilleure communauté gagne.;)
Différentes cardinalités pour le constructeur de valeur de table de base
J'ai expérimenté différentes cardinalités du CTE de base, en commençant par 2 et en avançant dans une échelle logarithmique, en mettant au carré la cardinalité précédente à chaque étape :2, 4, 16 et 256.
Avant de commencer à expérimenter avec différentes cardinalités de base, il pourrait être utile d'avoir une formule qui, compte tenu de la cardinalité de base et de la cardinalité de plage maximale, vous indiquerait le nombre de niveaux de CTE dont vous avez besoin. Comme étape préliminaire, il est plus facile de trouver d'abord une formule qui, compte tenu de la cardinalité de base et du nombre de niveaux de CTE, calcule la cardinalité maximale de la plage résultante. Voici une telle formule exprimée en T-SQL :
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Avec les exemples de valeurs d'entrée ci-dessus, cette expression donne une cardinalité de plage maximale de 4 294 967 296.
Ensuite, la formule inverse pour calculer le nombre de niveaux CTE nécessaires consiste à imbriquer deux fonctions de log, comme suit :
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Avec les exemples de valeurs d'entrée ci-dessus, cette expression donne 5. Notez que ce nombre s'ajoute au CTE de base qui a le constructeur de valeur de table, que j'ai nommé L0 (pour le niveau 0) dans ma solution.
Ne me demandez pas comment j'en suis arrivé à ces formules. L'histoire à laquelle je m'en tiens est que Gandalf me les a prononcés en elfique dans mes rêves.
Passons aux tests de performance. Assurez-vous que vous activez Ignorer les résultats après l'exécution dans votre boîte de dialogue Options de requête SSMS sous Grille, Résultats. Utilisez le code suivant pour exécuter un test avec une cardinalité CTE de base de 2 (nécessite 5 niveaux supplémentaires de CTE) :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; J'ai obtenu le plan illustré à la figure 1 pour cette exécution.
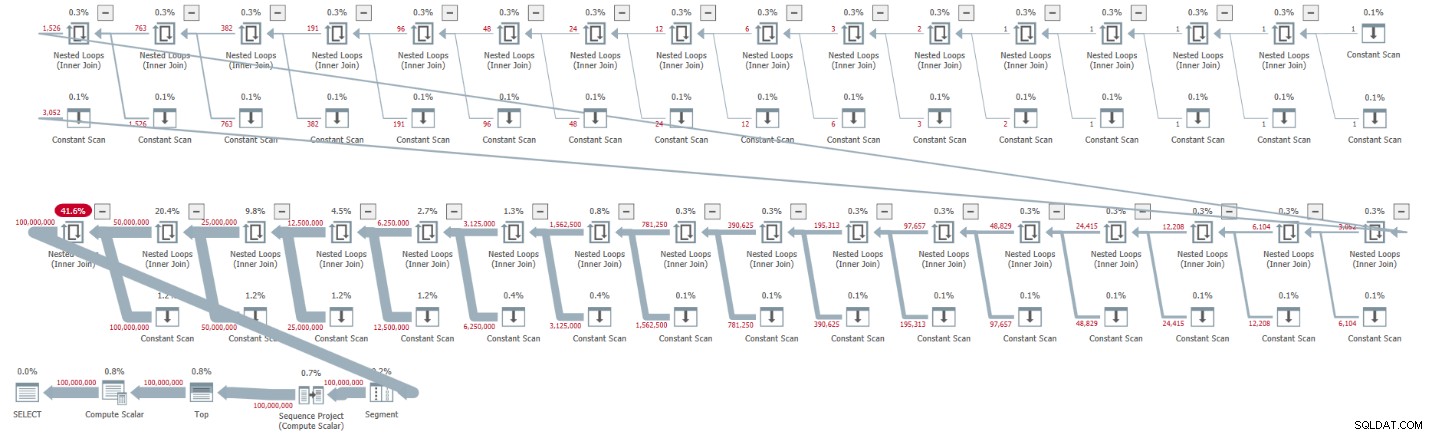 Figure 1 :Plan pour une cardinalité CTE de base de 2
Figure 1 :Plan pour une cardinalité CTE de base de 2
Le plan est en série et tous les opérateurs du plan utilisent le traitement en mode ligne par défaut. Si vous obtenez un plan parallèle par défaut, par exemple, lors de l'encapsulation de la solution dans un iTVF et de l'utilisation d'une large plage, forcez pour l'instant un plan en série avec un indice MAXDOP 1.
Observez comment le déballage des CTE a abouti à 32 instances de l'opérateur Constant Scan, chacune représentant un tableau à deux lignes.
J'ai obtenu les statistiques de performances suivantes pour cette exécution :
CPU time = 30188 ms, elapsed time = 32844 ms.
Utilisez le code suivant pour tester la solution avec une cardinalité CTE de base de 4, qui, selon notre formule, nécessite quatre niveaux de CTE :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; J'ai obtenu le plan illustré à la figure 2 pour cette exécution.
 Figure 2 :Plan pour une cardinalité CTE de base de 4
Figure 2 :Plan pour une cardinalité CTE de base de 4
Le déballage des CTE a donné lieu à 16 opérateurs Constant Scan, chacun représentant un tableau de 4 lignes.
J'ai obtenu les statistiques de performances suivantes pour cette exécution :
CPU time = 23781 ms, elapsed time = 25435 ms.
Il s'agit d'une amélioration décente de 22,5 % par rapport à la solution précédente.
En examinant les statistiques d'attente signalées pour la requête, le type d'attente dominant est SOS_SCHEDULER_YIELD. En effet, le nombre d'attentes a curieusement baissé de 22,8 % par rapport à la première solution (nombre d'attentes de 15 280 contre 19 800).
Utilisez le code suivant pour tester la solution avec une cardinalité CTE de base de 16, qui, selon notre formule, nécessite trois niveaux de CTE :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; J'ai obtenu le plan illustré à la figure 3 pour cette exécution.
 Figure 3 :Plan pour une cardinalité CTE de base de 16
Figure 3 :Plan pour une cardinalité CTE de base de 16
Cette fois, le déballage des CTE a donné lieu à 8 opérateurs Constant Scan, chacun représentant un tableau de 16 lignes.
J'ai obtenu les statistiques de performances suivantes pour cette exécution :
CPU time = 22968 ms, elapsed time = 24409 ms.
Cette solution réduit encore le temps écoulé, quoique de quelques pour cent supplémentaires, soit une réduction de 25,7 pour cent par rapport à la première solution. Encore une fois, le nombre d'attentes du type d'attente SOS_SCHEDULER_YIELD ne cesse de chuter (12 938).
En avançant dans notre échelle logarithmique, le prochain test implique une cardinalité CTE de base de 256. C'est long et moche, mais essayez-le :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; J'ai obtenu le plan illustré à la figure 4 pour cette exécution.
 Figure 4 :Plan pour une cardinalité CTE de base de 256
Figure 4 :Plan pour une cardinalité CTE de base de 256
Cette fois, le déballage des CTE n'a donné lieu qu'à quatre opérateurs Constant Scan, chacun avec 256 lignes.
J'ai obtenu les chiffres de performance suivants pour cette exécution :
CPU time = 23516 ms, elapsed time = 25529 ms.
Cette fois, il semble que les performances se soient un peu dégradées par rapport à la solution précédente avec une cardinalité CTE de base de 16. En effet, le nombre d'attentes du type d'attente SOS_SCHEDULER_YIELD a légèrement augmenté pour atteindre 13 176. Il semblerait donc que nous ayons trouvé notre nombre d'or :16 !
Plans en parallèle ou en série
J'ai essayé de forcer un plan parallèle en utilisant l'indice ENABLE_PARALLEL_PLAN_PREFERENCE, mais cela a fini par nuire aux performances. En fait, lors de la mise en œuvre de la solution en tant qu'iTVF, j'ai obtenu un plan parallèle sur ma machine par défaut pour les grandes plages, et j'ai dû forcer un plan série avec un indice MAXDOP 1 pour obtenir des performances optimales.
Traitement par lots
La principale ressource utilisée dans les plans de mes solutions est le CPU. Étant donné que le traitement par lots consiste à améliorer l'efficacité du processeur, en particulier lorsqu'il s'agit d'un grand nombre de lignes, il vaut la peine d'essayer cette option. L'activité principale ici qui peut bénéficier du traitement par lots est le calcul du numéro de ligne. J'ai testé mes solutions dans SQL Server 2019 Enterprise edition. SQL Server a choisi par défaut le traitement en mode ligne pour toutes les solutions précédemment affichées. Apparemment, cette solution n'a pas réussi l'heuristique requise pour activer le mode batch sur rowstore. Il existe plusieurs façons d'amener SQL Server à utiliser le traitement par lots ici.
L'option 1 consiste à impliquer une table avec un index columnstore dans la solution. Vous pouvez y parvenir en créant une table factice avec un index columnstore et en introduisant une jointure gauche factice dans la requête la plus externe entre notre CTE Nums et cette table. Voici la définition de la table factice :
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Ensuite, révisez la requête externe sur Nums pour utiliser FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Voici un exemple avec une cardinalité CTE de base de 16 :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; J'ai obtenu le plan illustré à la figure 5 pour cette exécution.
 Figure 5 :Plan avec traitement par lots
Figure 5 :Plan avec traitement par lots
Observez l'utilisation de l'opérateur Window Aggregate en mode batch pour calculer les numéros de lignes. Notez également que le plan n'implique pas la table factice. L'optimiseur l'a optimisé.
L'avantage de l'option 1 est qu'elle fonctionne dans toutes les éditions de SQL Server et est pertinente dans SQL Server 2016 ou version ultérieure, puisque l'opérateur d'agrégation de fenêtres en mode batch a été introduit dans SQL Server 2016. L'inconvénient est la nécessité de créer la table factice et d'inclure dans la solution.
L'option 2 pour obtenir le traitement par lots pour notre solution, à condition que vous utilisiez SQL Server 2019 Enterprise Edition, consiste à utiliser l'indice explicite non documenté OVERRIDE_BATCH_MODE_HEURISTICS (détails dans l'article de Dmitry Pilugin), comme suit :
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); L'avantage de l'option 2 est que vous n'avez pas besoin de créer une table factice et de l'impliquer dans votre solution. Les inconvénients sont que vous devez utiliser l'édition Enterprise, utiliser au minimum SQL Server 2019 où le mode batch sur rowstore a été introduit, et la solution implique l'utilisation d'un indice non documenté. Pour ces raisons, je préfère l'option 1.
Voici les chiffres de performance que j'ai obtenus pour les différentes cardinalités CTE de base :
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
La figure 6 présente une comparaison des performances entre les différentes solutions :
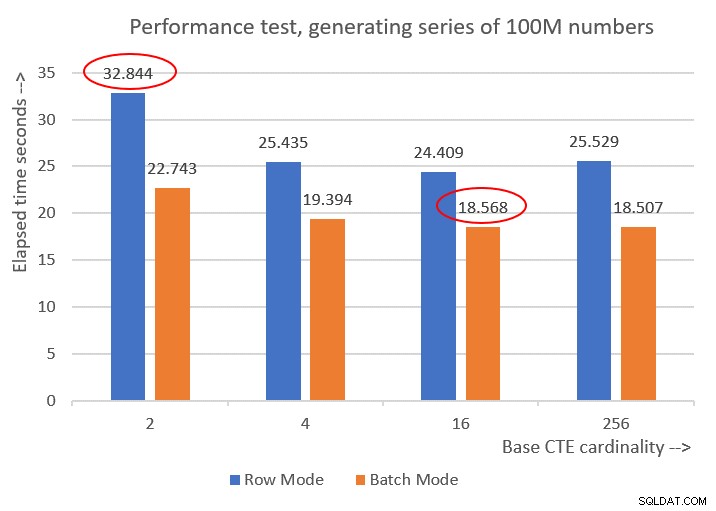 Figure 6 :Comparaison des performances
Figure 6 :Comparaison des performances
Vous pouvez observer une amélioration des performances décente de 20 à 30 % par rapport aux homologues en mode ligne.
Curieusement, avec le traitement en mode batch, la solution avec une cardinalité CTE de base de 256 a donné les meilleurs résultats. Cependant, c'est juste un tout petit peu plus rapide que la solution avec une cardinalité CTE de base de 16. La différence est si mineure, et cette dernière a un net avantage en termes de brièveté du code, que je m'en tiendrai à 16.
Ainsi, mes efforts de réglage ont abouti à une amélioration de 43,5 % par rapport à la solution d'origine avec la cardinalité de base de 2 en utilisant le traitement en mode ligne.
Le défi est lancé !
Je soumets deux solutions comme contribution de ma communauté à ce défi. Si vous utilisez SQL Server 2016 ou une version ultérieure et que vous pouvez créer une table dans la base de données utilisateur, créez la table factice suivante :
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Et utilisez la définition iTVF suivante :
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Utilisez le code suivant pour le tester (assurez-vous d'avoir coché Supprimer les résultats après l'exécution) :
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ce code se termine en 18 secondes sur ma machine.
Si, pour une raison quelconque, vous ne pouvez pas répondre aux exigences de la solution de traitement par lots, je soumets la définition de fonction suivante comme deuxième solution :
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Utilisez le code suivant pour le tester :
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Ce code se termine en 24 secondes sur ma machine.
A votre tour !