MySQL Replication a été la solution la plus courante et la plus largement utilisée pour la haute disponibilité par de grandes organisations telles que Github, Twitter et Facebook. Bien que facile à configurer, il existe des défis lors de l'utilisation de cette solution à partir de la maintenance, notamment les mises à niveau logicielles, la dérive des données ou l'incohérence des données entre les nœuds de réplique, les changements de topologie, le basculement et la récupération. Lorsque MySQL a publié la version 5.6, elle a apporté un certain nombre d'améliorations significatives, en particulier à la réplication qui inclut les identifiants de transaction globaux (GTID), les sommes de contrôle d'événements, les esclaves multithreads et les esclaves/maîtres anti-crash. La réplication s'est encore améliorée avec MySQL 5.7 et MySQL 8.0.
La réplication permet aux données d'un serveur MySQL (le principal/maître) d'être répliquées sur un ou plusieurs serveurs MySQL (les répliques/esclaves). La réplication MySQL est très facile à configurer et est utilisée pour faire évoluer les charges de travail de lecture, fournir une haute disponibilité et une redondance géographique, et décharger les sauvegardes et les tâches d'analyse.
La réplication MySQL dans la nature
Voyons un bref aperçu du fonctionnement de la réplication MySQL dans la nature. La réplication MySQL est vaste et il existe plusieurs façons de la configurer et de l'utiliser. Par défaut, il utilise la réplication asynchrone, qui fonctionne lorsque la transaction est terminée dans l'environnement local. Il n'y a aucune garantie que n'importe quel événement atteindra jamais n'importe quel esclave. Il s'agit d'une relation maître-esclave faiblement couplée, où :
-
Le primaire n'attend pas de réplique.
-
La réplique détermine la quantité à lire et à partir de quel point dans le journal binaire.
-
Le réplica peut être arbitrairement en retard sur le maître dans la lecture ou l'application des modifications.
Si le primaire tombe en panne, les transactions qu'il a validées peuvent ne pas avoir été transmises à une réplique. Par conséquent, le basculement du principal vers le réplica le plus avancé, dans ce cas, peut entraîner un basculement vers le principal souhaité qui manque en fait de transactions par rapport au serveur précédent.
La réplication asynchrone offre une latence d'écriture plus faible puisqu'une écriture est acquittée localement par un maître avant d'être écrite sur les esclaves. Il est idéal pour la mise à l'échelle de la lecture, car l'ajout de plusieurs répliques n'a pas d'impact sur la latence de réplication. Les bons cas d'utilisation de la réplication asynchrone incluent le déploiement d'instances dupliquées en lecture pour la mise à l'échelle de la lecture, la copie de sauvegarde en direct pour la reprise après sinistre et l'analyse/la création de rapports.
Réplication semi-synchrone MySQL
MySQL prend également en charge la réplication semi-synchrone, où le maître ne confirme pas les transactions au client tant qu'au moins un esclave n'a pas copié la modification dans son journal de relais et l'a vidé sur le disque. Pour activer la réplication semi-synchrone, des étapes supplémentaires d'installation du plug-in sont nécessaires et doivent être activées sur les nœuds maître et esclave MySQL désignés.
Semi-synchrone semble être une bonne solution pratique pour de nombreux cas où une haute disponibilité et aucune perte de données sont importantes. Mais vous devez considérer que le mode semi-synchrone a un impact sur les performances en raison de l'aller-retour supplémentaire et ne fournit pas de garanties solides contre la perte de données. Lorsqu'un commit revient avec succès, on sait que les données existent à au moins deux endroits (sur le maître et au moins un esclave). Si le maître s'engage mais qu'un plantage se produit alors que le maître attend l'accusé de réception d'un esclave, il est possible que la transaction n'ait atteint aucun esclave. Ce n'est pas un si gros problème car le commit ne sera pas renvoyé à l'application dans ce cas. C'est la tâche de l'application de réessayer la transaction à l'avenir. Il est essentiel de garder à l'esprit que lorsque le maître tombe en panne et qu'un esclave a été promu, l'ancien maître ne peut pas rejoindre la chaîne de réplication. Dans certaines circonstances, cela peut entraîner des conflits avec les données sur les esclaves, c'est-à-dire lorsque le maître s'est écrasé après que l'esclave a reçu l'événement de journal binaire mais avant que le maître n'ait reçu l'accusé de réception de l'esclave). Ainsi, le seul moyen sûr consiste à supprimer les données de l'ancien maître et à le provisionner à partir de zéro en utilisant les données du maître nouvellement promu.
Utilisation incorrecte du format de réplication
Depuis MySQL 5.7.7, le format de journal binaire par défaut ou la variable binlog_format utilise ROW, qui était STATEMENT avant la version 5.7.7. Les différents formats de réplication correspondent à la méthode utilisée pour enregistrer les événements du journal binaire de la source. La réplication fonctionne car les événements écrits dans le journal binaire sont lus à partir de la source, puis traités sur la réplique. Les événements sont enregistrés dans le journal binaire dans différents formats de réplication en fonction du type d'événement. Ne pas savoir avec certitude quoi utiliser peut être un problème. MySQL propose trois formats de méthodes de réplication :STATEMENT, ROW et MIXED.
-
Le format de réplication basée sur STATEMENT (SBR) est exactement ce qu'il est :un flux de réplication de chaque instruction exécutée sur le maître qui sera rejoué sur le nœud esclave. Par défaut, la réplication MySQL traditionnelle (asynchrone) n'exécute pas les transactions répliquées vers les esclaves en parallèle. Cela signifie que l'ordre des instructions dans le flux de réplication peut ne pas être identique à 100 %. De plus, la relecture d'une instruction peut donner des résultats différents lorsqu'elle n'est pas exécutée en même temps que lorsqu'elle est exécutée à partir de la source. Cela conduit à un état incohérent par rapport au primaire et à ses répliques. Ce n'était pas un problème pendant de nombreuses années, car peu d'entre eux exécutaient MySQL avec de nombreux threads simultanés. Cependant, avec les architectures multi-processeurs modernes, cela est devenu hautement probable sur une charge de travail quotidienne normale.
-
Le format de réplication ROW fournit des solutions qui manquent au SBR. Lors de l'utilisation du format de journalisation de la réplication basée sur les lignes (RBR), la source écrit des événements dans le journal binaire qui indiquent comment les lignes de table individuelles sont modifiées. La réplication de la source vers le réplica fonctionne en copiant les événements représentant les modifications apportées aux lignes de la table vers le réplica. Cela signifie que davantage de données peuvent être générées, affectant l'espace disque dans la réplique et affectant le trafic réseau et les E/S disque. Considérez si une instruction modifie de nombreuses lignes, disons avec une instruction UPDATE, RBR écrit plus de données dans le journal binaire même pour les instructions qui sont annulées. L'exécution d'instantanés ponctuels peut également prendre plus de temps. Des problèmes de simultanéité peuvent entrer en jeu étant donné les temps de verrouillage nécessaires pour écrire de gros morceaux de données dans le journal binaire.
-
Ensuite, il existe une méthode entre ces deux; réplication en mode mixte. Ce type de réplication répliquera toujours les instructions, sauf lorsque la requête contient la fonction UUID(), les déclencheurs, les procédures stockées, les UDF et quelques autres exceptions. Le mode mixte ne résoudra pas le problème de la dérive des données et, avec la réplication basée sur les instructions, doit être évité.
Vous prévoyez d'avoir une configuration multi-maîtres ?
La réplication circulaire (également connue sous le nom de topologie en anneau) est une configuration connue et courante pour la réplication MySQL. Il est utilisé pour exécuter une configuration multi-maître (voir l'image ci-dessous) et est souvent nécessaire si vous avez un environnement multi-centre de données. Étant donné que l'application ne peut pas attendre que le maître de l'autre centre de données reconnaisse les écritures, un maître local est préférable. Normalement, le décalage d'incrémentation automatique est utilisé pour éviter les conflits de données entre les maîtres. Faire en sorte que deux maîtres effectuent des écritures l'une sur l'autre de cette manière est une solution largement acceptée.
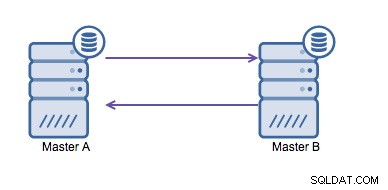
Cependant, si vous devez écrire dans plusieurs centres de données dans la même base de données , vous vous retrouvez avec plusieurs maîtres qui doivent écrire leurs données les uns aux autres. Avant MySQL 5.7.6, il n'existait aucune méthode pour effectuer une réplication de type maillage, donc l'alternative serait d'utiliser une réplication en anneau circulaire à la place.
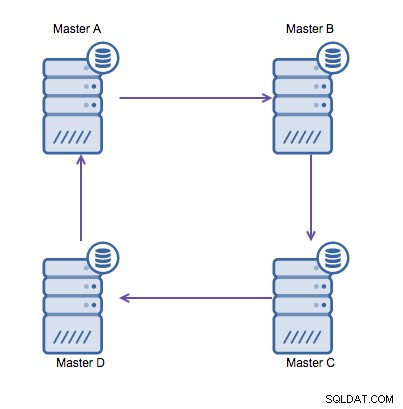
La réplication en anneau dans MySQL est problématique pour les raisons suivantes :latence, haute disponibilité , et la dérive des données. L'écriture de certaines données sur le serveur A prendrait trois sauts pour se retrouver sur le serveur D (via les serveurs B et C). Étant donné que la réplication MySQL (traditionnelle) est monothread, toute requête de longue durée dans la réplication peut bloquer l'ensemble de l'anneau. De plus, si l'un des serveurs tombait en panne, l'anneau serait rompu et, actuellement, aucun logiciel de basculement ne peut réparer les structures en anneau. Ensuite, une dérive des données peut se produire lorsque des données sont écrites sur le serveur A et sont modifiées simultanément sur le serveur C ou D.
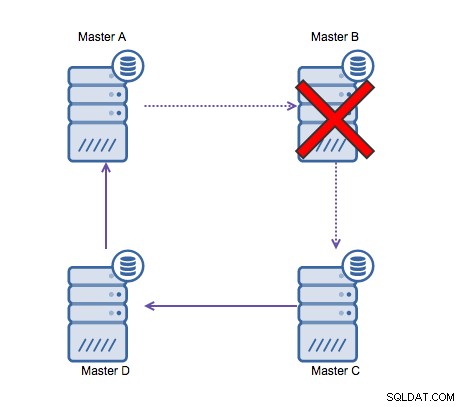
En général, la réplication circulaire ne convient pas à MySQL et devrait être à éviter à tout prix. Comme il a été conçu dans cet esprit, Galera Cluster serait une bonne alternative pour les écritures multi-centres de données.
Bloquer votre réplication avec des mises à jour volumineuses
Diverses tâches de maintenance par lots effectuent souvent diverses tâches, allant du nettoyage des anciennes données au calcul des moyennes des "j'aime" extraits d'une autre source. Cela signifie qu'un travail créera beaucoup d'activité de base de données à des intervalles définis et, très probablement, réécrira beaucoup de données dans la base de données. Naturellement, cela signifie que l'activité au sein du flux de réplication augmentera également.
La réplication basée sur les instructions répliquera les requêtes exactes utilisées dans les travaux par lots, donc si la requête prenait une demi-heure à traiter sur le maître, le thread esclave serait bloqué pendant au moins la même quantité de temps. Cela signifie qu'aucune autre donnée ne peut être répliquée et que les nœuds esclaves commenceront à être en retard sur le maître. Si cela dépasse le seuil de votre outil de basculement ou de votre proxy, il peut supprimer ces nœuds esclaves des serveurs disponibles dans le cluster. Si vous utilisez la réplication basée sur des instructions, vous pouvez éviter cela en analysant les données de votre travail en lots plus petits.
Maintenant, vous pouvez penser que la réplication basée sur les lignes n'est pas affectée par cela, car elle répliquera les informations de ligne au lieu de la requête. Cela est en partie vrai car, pour les modifications DDL, la réplication revient à un format basé sur des instructions. De plus, un grand nombre d'opérations CRUD (créer, lire, mettre à jour, supprimer) affectera le flux de réplication. Dans la plupart des cas, il s'agit toujours d'une opération à un seul thread, et donc chaque transaction attendra que la précédente soit rejouée via la réplication. Cela signifie que si vous avez une forte simultanéité sur le maître, l'esclave peut se bloquer sur la surcharge de transactions lors de la réplication.
Pour contourner ce problème, MariaDB et MySQL proposent une réplication parallèle. L'implémentation peut différer selon le fournisseur et la version. MySQL 5.6 offre une réplication parallèle tant que les requêtes sont séparées par le schéma. MariaDB 10.0 et MySQL 5.7 peuvent tous deux gérer la réplication parallèle entre les schémas, mais ont d'autres limites. L'exécution de requêtes via des threads esclaves parallèles peut accélérer votre flux de réplication si vous écrivez beaucoup. Sinon, il serait préférable de s'en tenir à la réplication traditionnelle à un seul thread.
Gérer votre changement de schéma ou vos DDL
Depuis la sortie de la version 5.7, la gestion du changement de schéma ou du changement DDL (Data Definition Language) dans MySQL s'est beaucoup améliorée. Jusqu'à MySQL 8.0, les algorithmes de modification DDL pris en charge sont COPY et INPLACE.
-
COPY :cet algorithme crée une nouvelle table temporaire avec le schéma modifié. Une fois qu'il a complètement migré les données vers la nouvelle table temporaire, il permute et supprime l'ancienne table.
-
INPLACE :cet algorithme effectue des opérations en place sur la table d'origine et évite la copie et la reconstruction de la table dans la mesure du possible.
-
INSTANT :cet algorithme a été introduit depuis MySQL 8.0 mais a encore des limitations.
Dans MySQL 8.0, l'algorithme INSTANT a été introduit, apportant des modifications de table instantanées et sur place pour l'ajout de colonnes et permettant un DML simultané avec une réactivité et une disponibilité améliorées dans les environnements de production occupés. Cela permet d'éviter d'énormes retards et blocages dans la réplique qui étaient généralement de gros problèmes du point de vue de l'application, entraînant la récupération de données obsolètes car les lectures de l'esclave n'ont pas encore été mises à jour en raison d'un décalage.
Bien qu'il s'agisse d'une amélioration prometteuse, il y a encore des limitations avec eux, et parfois il n'est pas possible d'appliquer ces algorithmes INSTANT et INPLACE. Par exemple, pour les algorithmes INSTANT et INPLACE, la modification du type de données d'une colonne est également une tâche habituelle du DBA, en particulier dans la perspective du développement d'applications en raison de la modification des données. Ces occasions sont inévitables; ainsi, vous ne pouvez pas continuer avec l'algorithme COPY car cela verrouille la table, ce qui entraîne des retards dans l'esclave. Cela impacte également le serveur primaire/maître lors de cette exécution car il accumule les transactions entrantes qui font également référence à la table affectée. Vous ne pouvez pas effectuer un ALTER direct ou un changement de schéma sur un serveur occupé car cela accompagne les temps d'arrêt ou corrompt éventuellement votre base de données si vous perdez patience, surtout si la table cible est énorme.
Il est vrai que l'exécution de modifications de schéma sur une configuration de production en cours d'exécution est toujours une tâche difficile. Une solution de contournement fréquemment utilisée consiste à appliquer d'abord le changement de schéma aux nœuds esclaves. Cela fonctionne bien pour la réplication basée sur les instructions, mais cela ne peut fonctionner que jusqu'à un certain degré pour la réplication basée sur les lignes. La réplication basée sur les lignes permet à des colonnes supplémentaires d'exister à la fin de la table, donc tant qu'elle peut écrire les premières colonnes, tout ira bien. Tout d'abord, appliquez la modification à tous les esclaves, puis basculez vers l'un des esclaves, puis appliquez la modification au maître et attachez-le en tant qu'esclave. Si votre modification implique l'insertion d'une colonne au milieu ou la suppression d'une colonne, cela fonctionnera avec la réplication basée sur les lignes.
Il existe des outils disponibles qui peuvent effectuer des modifications de schéma en ligne de manière plus fiable. Le changement de schéma en ligne Percona (connu sous le nom de pt-osc) et gh-ost de Schlomi Noach sont couramment utilisés par les DBA. Ces outils gèrent efficacement les modifications de schéma en regroupant les lignes affectées en blocs, et ces blocs peuvent être configurés en conséquence en fonction du nombre que vous souhaitez regrouper.
Si vous allez sauter avec pt-osc, cet outil créera une table fantôme avec la nouvelle structure de table, insérera de nouvelles données via des déclencheurs et remplira les données en arrière-plan. Une fois la création de la nouvelle table terminée, il remplacera simplement l'ancienne par la nouvelle table dans une transaction. Cela ne fonctionne pas dans tous les cas, surtout si votre table existante a déjà des déclencheurs.
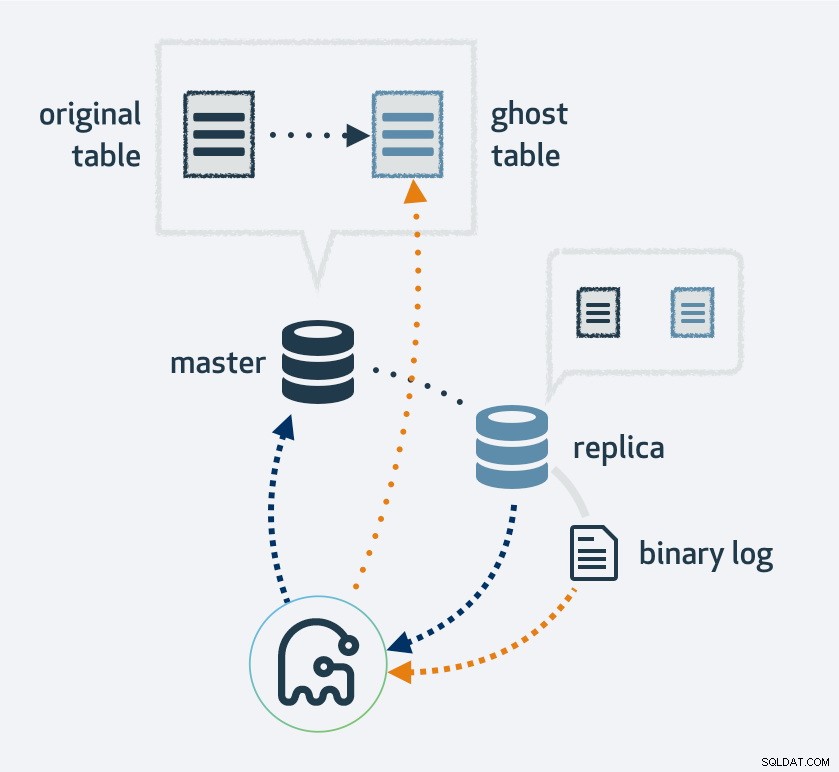
L'utilisation de gh-ost fera d'abord une copie de votre disposition de table existante, modifiez la table avec la nouvelle mise en page, puis raccordez le processus en tant que réplique MySQL. Il utilisera le flux de réplication pour trouver de nouvelles lignes qui ont été insérées dans la table d'origine et, en même temps, remplira la table. Une fois le remblayage terminé, les tables d'origine et les nouvelles basculeront. Naturellement, toutes les opérations sur la nouvelle table se retrouveront dans le flux de réplication; ainsi, sur chaque réplica, la migration se produit simultanément.
Tables de mémoire et réplication
Alors que nous parlons de DDL, un problème courant est la création de tables de mémoire. Les tables mémoire sont des tables non persistantes, leur structure de table demeure, mais elles perdent leurs données après un redémarrage de MySQL. Lors de la création d'une nouvelle table mémoire à la fois sur un maître et un esclave, ils auront une table vide, qui fonctionnera parfaitement bien. Une fois l'un ou l'autre redémarré, la table sera vidée et des erreurs de réplication se produiront.
La réplication basée sur les lignes s'arrêtera une fois que les données du nœud esclave renvoient des résultats différents, et la réplication basée sur les instructions s'arrêtera une fois qu'elle tentera d'insérer des données qui existent déjà. Pour les tables de mémoire, il s'agit d'un briseur de réplication fréquent. La solution est simple :faites une nouvelle copie des données, changez le moteur pour InnoDB, et il devrait maintenant être répliqué en toute sécurité.
Définition de read_only={True|1}
C'est, bien sûr, un cas possible lorsque vous utilisez une topologie en anneau, et nous déconseillons l'utilisation de la topologie en anneau si possible. Nous avons décrit précédemment que le fait de ne pas avoir les mêmes données dans les nœuds esclaves peut interrompre la réplication. Souvent, cela est dû à quelque chose (ou quelqu'un) modifiant les données sur le nœud esclave mais pas sur le nœud maître. Une fois que les données du nœud maître sont modifiées, elles seront répliquées sur l'esclave où il ne peut pas appliquer la modification, ce qui provoque l'interruption de la réplication. Cela peut également entraîner une corruption des données au niveau du cluster, en particulier si l'esclave a été promu ou a échoué en raison d'un plantage. Cela peut être un désastre.
Une prévention simple consiste à s'assurer que read_only et super_read_only (uniquement sur> 5.6) sont définis sur ON ou 1. Vous avez peut-être compris en quoi ces deux variables diffèrent et comment cela affecte si vous désactivez ou activez eux. Avec super_read_only (depuis MySQL 5.7.8) désactivé, l'utilisateur root peut empêcher toute modification de la cible ou du réplica. Ainsi, lorsque les deux sont désactivés, cela empêchera quiconque d'apporter des modifications aux données, à l'exception de la réplication. La plupart des gestionnaires de basculement, tels que ClusterControl, définissent cet indicateur automatiquement pour empêcher les utilisateurs d'écrire sur le maître utilisé pendant le basculement. Certains d'entre eux le conservent même après le basculement.
Activation du GTID
Dans la réplication MySQL, démarrer l'esclave à partir de la position correcte dans les journaux binaires est essentiel. L'obtention de cette position peut être effectuée lors d'une sauvegarde (xtrabackup et mysqldump le supportent) ou lorsque vous avez arrêté l'asservissement sur un nœud dont vous faites une copie. Le démarrage de la réplication avec la commande CHANGE MASTER TO ressemblerait à ceci :
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Démarrer la réplication au mauvais endroit peut avoir des conséquences désastreuses :les données peuvent être écrites en double ou ne pas être mises à jour. Cela provoque une dérive des données entre le nœud maître et le nœud esclave.
En outre, le basculement d'un maître vers un esclave implique de trouver la position correcte et de changer le maître en hôte approprié. MySQL ne conserve pas les journaux et les positions binaires de son maître, mais crée à la place ses propres journaux et positions binaires. Cela pourrait devenir un problème sérieux pour réaligner un nœud esclave sur le nouveau maître. La position exacte du maître lors du basculement doit être trouvée sur le nouveau maître, puis tous les esclaves peuvent être réalignés.
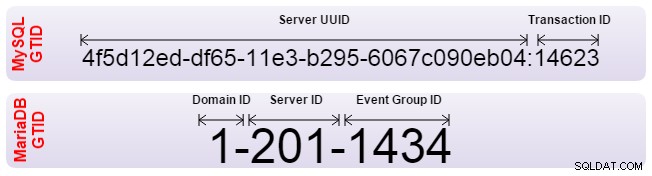
Oracle MySQL et MariaDB ont implémenté le Global Transaction Identifier (GTID) pour résoudre ce problème. Les GTID permettent l'alignement automatique des esclaves, et le serveur détermine par lui-même quelle est la position correcte. Cependant, les deux ont implémenté le GTID différemment et sont donc incompatibles. Si vous devez configurer la réplication de l'un à l'autre, la réplication doit être configurée avec un positionnement de journal binaire traditionnel. De plus, votre logiciel de basculement doit être averti de ne pas utiliser de GTID.
Esclave anti-crash
Crash safe signifie que même si un MySQL/OS esclave tombe en panne, vous pouvez récupérer l'esclave et continuer la réplication sans restaurer les bases de données MySQL sur l'esclave. Pour que l'esclave fonctionne en toute sécurité, vous devez utiliser uniquement le moteur de stockage InnoDB et, dans la version 5.6, vous devez définir relay_log_info_repository=TABLE et relay_log_recovery=1.
Conclusion
La pratique rend vraiment parfait, mais sans une formation et une connaissance adéquates de ces techniques vitales, cela pourrait être gênant ou conduire à un désastre. Ces pratiques sont généralement respectées par les experts de MySQL et sont adaptées par les grandes industries dans le cadre de leur travail de routine quotidien lors de l'administration de la réplication MySQL dans les serveurs de base de données de production.
Si vous souhaitez en savoir plus sur la réplication MySQL, consultez ce tutoriel sur la réplication MySQL pour la haute disponibilité.
Pour plus d'informations sur les solutions de gestion de base de données et les meilleures pratiques pour vos bases de données open source, suivez-nous sur Twitter et LinkedIn et abonnez-vous à notre newsletter.