Le modèle de conception de la nomenclature est d'une simplicité trompeuse, mais incroyablement puissant. Cet article présentera un exemple, familier aux professionnels de l'informatique, que vous n'auriez peut-être pas pensé correspondre au modèle de nomenclature. Il présentera également des concepts pour vous montrer comment rendre vos structures de nomenclature plus flexibles et beaucoup plus faciles à gérer.
Un bref récapitulatif de la nomenclature
Une nomenclature a ses racines dans la fabrication. Il s'agit d'une liste des matières premières, des sous-ensembles, des assemblages intermédiaires, des sous-composants, des pièces et des quantités de chacun nécessaires à la fabrication d'un produit final.
Dans sa forme la plus simple, la structure de nomenclature classique ressemble à ceci :
Cependant, le même type de structure peut être utilisé pour une multitude de objectifs différents , qui vont de quelque chose de strictement hiérarchique et étroitement couplé à quelque chose d'assez plat et peu couplé. Pour plus d'informations sur la structure de la nomenclature, consultez cet article.
Schémas :un exemple quotidien
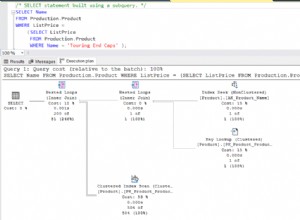
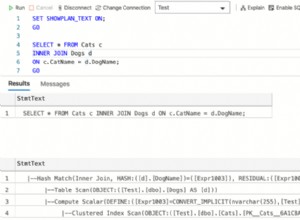
Croyez-le ou non, le triplet classe-attribut-type et le triplet table-colonne-type suivent également le modèle BOM. Le modèle physique de données ci-dessous contient les tables de base d'un dictionnaire de données.
| Table | Description |
|---|---|
| dd_attribute | Un attribut unique, indépendant de toute implémentation. |
| dd_attr_instance | Une instance d'un attribut. L'instance a deux relations distinctes : 1) La classe à laquelle elle appartient, qui peut être un objet logique ou physique. L'instance est unique à cette classe. 2) Le type de données, qui peut être soit un type natif, soit un autre type de classe. |
| dd_class | Une classe ou un objet au sens générique - l'implémentation réelle étant donnée par class_type – qui a un ensemble d'attributs. |
Un dictionnaire de données, ou référentiel de métadonnées, est défini dans l'IBM Dictionary of Computing comme "un référentiel centralisé d'informations sur les données telles que la signification, les relations avec d'autres données, l'origine, l'utilisation et le format".
Considérons maintenant la définition de schéma XML (XSD) suivante pour une application Java :
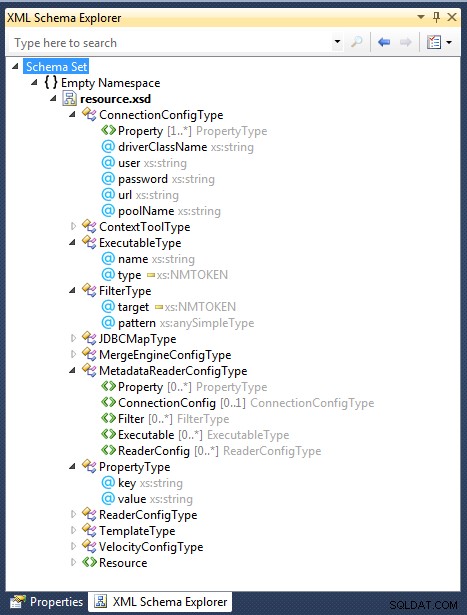
Il définit les types complexes XSD qui ont les attributs de l'un ou l'autre des types XML natifs - par ex. chaîne , NMTOKEN , toutSimpleType – ou d'autres types complexes.
Pour commencer à remplir le dictionnaire de données pour le XSD ci-dessus, nous devons d'abord saisir les types de données natifs XML en tant que classes :
| class_name | stéréotype |
|---|---|
| booléen | Natif |
| date | Natif |
| dateHeure | Natif |
| chaîne | Natif |
| version | Natif |
| NMTOKEN | Natif |
| toutSimpleType | Natif |
Nous avons maintenant tout ce dont nous avons besoin pour commencer à remplir notre dictionnaire de données. Dans l'exemple ci-dessous, juste assez est montré pour définir complètement le ConnectionConfigType type complexe.
| dd_attribute | of_class (via dd_attr_instance) | type_class (via dd_attr_instance) | ||
|---|---|---|---|---|
| attr_name | class_name | stéréotype | class_name | stéréotype |
| clé | Type de propriété | XSDcomplexType | chaîne | Natif |
| valeur | Type de propriété | XSDcomplexType | chaîne | Natif |
| Propriété | ConnectionConfigType | XSDcomplexType | Type de propriété | XSDcomplexType |
| driverClassName | ConnectionConfigType | XSDcomplexType | chaîne | Natif |
| utilisateur | ConnectionConfigType | XSDcomplexType | chaîne | Natif |
| mot de passe | ConnectionConfigType | XSDcomplexType | chaîne | Natif |
| poolName | ConnectionConfigType | XSDcomplexType | chaîne | Natif |
Notez comment le type de données de ConnectionConfigType.Property l'attribut est un autre type complexe, PropertyType . En XML, les types complexes peuvent être constitués d'autres types complexes. Il n'est pas rare de trouver des types complexes imbriqués dans les documents XML, en particulier dans WSDL.
Et alors ? tu demandes. Eh bien, étant donné que XML est une structure hiérarchique et que les types complexes peuvent être réutilisés, XML suit naturellement le modèle BOM .
Et ce phénomène ne se limite pas à XML. D'autres schémas, comme ceux des JSON et des bases de données relationnelles objet, suivent également le modèle BOM .
Intégrer la flexibilité dans une nomenclature
Dans la structure de nomenclature de produit classique, trois concepts plus fins sont impliqués dans la modélisation de ce qui se passe dans le monde réel. Ce sont des alternatives , variantes , et révisions .
Une alternative est un substitut à un article particulier. Par exemple, un constructeur automobile peut avoir différents fournisseurs pour certains articles. Concrètement, cela signifie que le fabricant peut obtenir des pompes à carburant équivalentes auprès de plusieurs sources. Habituellement, le client n'a pas cette option, mais cela donne de la flexibilité au fabricant.
Nous avons utilisé des pompes à carburant comme éléments dans le tableau d'exemple ci-dessous, avec Bosch et Lucas comme alternatives. Avoir une alternative à la pompe à carburant signifie qu'une et une seule des assemblages seront sélectionnés au moment de la fabrication du moteur.
| élément | Alternative | |
|---|---|---|
| Parent | Enfant | Quantité |
| V6 (Assemblage) | Pompe à carburant (alternative) | 1 |
| Pompe à carburant (alternative) | Pompe Bosch (assemblage) | |
| Pompe à carburant (alternative) | Pompe Lucas (Assemblage) | |
Une variante est un autre type d'article, mais cette fois c'est le client qui fait le choix. Un acheteur de voiture peut choisir différents styles de carrosserie - 3 portes, 5 portes ou un break (break ou break). Ils peuvent également choisir parmi deux types de moteurs différents - un V6 ou un V8. Dans notre exemple, l'acheteur doit choisir un et un seul des ensembles en dessous de la variante.
| élément | Variante | ||
|---|---|---|---|
| Parent | Enfant | Choix minimum | Choix maximum |
| Voiture (Assemblage) | Corps (variante) | 1 | 1 |
| Corps (Variante) | 3 portes (assemblage) | ||
| Corps (Variante) | 5 portes (assemblage) | ||
| Corps (Variante) | Estate (Assemblée) | ||
| Voiture (Assemblage) | Moteur (variante) | 1 | 1 |
| Moteur (Variante) | V6 (Assemblage) | ||
| Moteur (Variante) | V8 (Assemblage) | ||
Dans d'autres domaines, le nombre de choix est plus varié. Prenons l'exemple de l'éducation. Pour obtenir une qualification particulière, un étudiant doit compléter un nombre défini de groupes. Pour chaque groupe, ils peuvent choisir parmi plusieurs modules.
Par exemple, supposons qu'un étudiant doive compléter deux groupes pour obtenir un diplôme. Ils peuvent choisir deux modules parmi une liste de six pour compléter le premier groupe. Ensuite, ils doivent choisir trois modules parmi cinq pour compléter le deuxième groupe. (S'il s'agit d'un secteur que vous souhaitez voir plus en détail, une conception flexible a été publiée par l'Information Standard Board du Royaume-Uni.)
Les deux exemples ci-dessus suivent le modèle simple illustré ci-dessous. Ce modèle se prête à des structures assez statiques. Des variantes et des alternatives sont insérées dans la hiérarchie pour indiquer qu'une sorte de choix doit être fait parmi les éléments immédiatement en dessous.
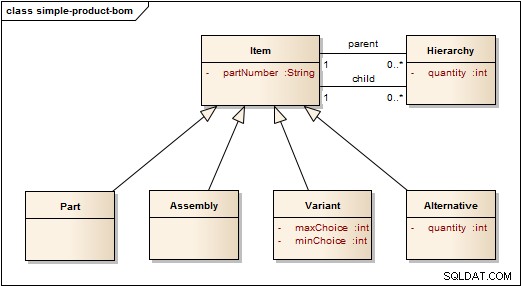
Là où les choses ont tendance à changer avec le temps, le modèle suivant est plus flexible et plus facile à maintenir. En revanche, il est un peu plus difficile à traverser (ou à naviguer).
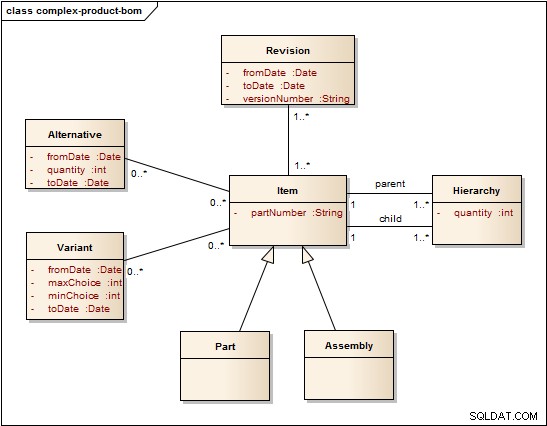
En transformant le modèle logique ci-dessus en modèle physique, les choses commencent à ressembler à ceci :
Dans ce modèle, un article est soit une pièce indivisible, soit un assemblage. Les pièces et les assemblages sont organisés en hiérarchies. Cependant, les alternatives , variantes et révisions ont leurs propres relations distinctes car elles ont tendance à changer un peu avec le temps. Cela minimise la réorganisation de la hiérarchie.
Par exemple, les constructeurs automobiles développent continuellement leurs voitures. Il s'ensuit que les alternatives de pièces évoluent dans le temps, tout comme les variantes mises à la disposition du client. Lorsqu'un changement se produit dans un assemblage, l'assemblage est révisé. Une révision indique l'historique des modifications de l'élément. Prenons cet exemple :
| Numéro de pièce | Version | Précédent | Suivant |
|---|---|---|---|
| 123456-1 | 1 | 123456-1 | 123456-1 |
| 123456-2 | 2 | 123456-1 | 123456-2 |
| 123456-3 | 3 | 123456-2 | 123456-3 |
| 123456-4 | 4 | 123456-1 | 123456-4 |
| 123456-5 | 5 | 123456-2, 123456-3 | 123456-5 |
Le récit du tableau ci-dessus se présente comme suit :un élément a au moins une révision - sa version originale. La version originale du produit est utilisée pour créer la deuxième version. La seconde a été développée plus avant pour créer la version trois, qui n'a pas fonctionné. Les ingénieurs ont donc révisé la version originale, créant la version quatre. Après des tests approfondis, cela s'est également avéré loin d'être idéal. Les ingénieurs ont donc décidé de reprendre certains aspects des deuxième et troisième versions et de créer la cinquième version, le produit final.
Si vous regardez les clés précédentes et suivantes, vous comprendrez pourquoi l'historique des modifications nécessite un plusieurs à plusieurs relation entre les éléments et les révisions. Le même principe s'applique entre les articles, les alternatives et les variantes.
Un dernier mot sur le modèle de nomenclature
J'espère que cette série d'articles vous a aidé à reconnaître le modèle de nomenclature. Lorsqu'il apparaîtra dans vos projets, vous comprendrez comment le modéliser au mieux dans votre domaine spécifique.
Veuillez noter, cependant, que la structure stricte de la nomenclature a des avantages et des inconvénients. Avantage :les hiérarchies sont réutilisables. Inconvénient :les hiérarchies sont réutilisables. Cela peut ou non être une mauvaise chose dans votre cas, mais c'est certainement quelque chose dont il faut être conscient.
Ce qui est bien, c'est que les hiérarchies n'ont pas besoin d'être gravées dans le marbre. À l'aide d'alternatives, de variantes et de révisions, vous pouvez modéliser des domaines où des options existent, où la position historique doit être conservée et, finalement, où la seule constante est le changement.