En cette ère de concurrence féroce, les portails d'emploi ne sont pas seulement des plateformes de publication et de recherche d'emploi. Ils tirent parti de services et de fonctionnalités avancés pour maintenir l'engagement de leurs clients. Plongeons-nous dans certaines fonctionnalités avancées et créons un modèle de données capable de les gérer.
J'ai expliqué les fonctionnalités de base nécessaires à un site Web de portail d'emploi dans un article précédent. Le modèle est présenté ci-dessous. Nous considérerons ce modèle comme une base, que nous modifierons pour répondre aux nouvelles exigences. Voyons d'abord quelles devraient être ces exigences (ou améliorations).
Qu'ajoutons-nous au modèle de données du portail d'emploi en ligne ?
En bref, nous allons ajouter quatre améliorations à notre ancien modèle de données :
- Un tableau de bord personnel pour les demandeurs d'emploi. Cela permet de suivre toutes leurs candidatures et fournit des mises à jour en temps réel sur tout changement de statut (c'est-à-dire qu'une candidature passe de la réception à l'examen).
- Un tableau de bord de profil. Cela détaille qui visite le profil d'un demandeur d'emploi et combien de fois son CV a été téléchargé au cours du dernier jour, semaine ou mois.
- Gestion des services payants. Les portails d'emploi proposent souvent des services tels que la préparation de CV par des experts, la gestion des profils sociaux, le conseil en carrière, etc. Nos nouvelles fonctionnalités pourront prendre en charge les offres payantes.
- Gestion des formulaires de pré-demande. Lorsque les candidats soumettent une demande d'emploi, ils peuvent être invités à remplir un court questionnaire relatif aux heures de travail, aux lieux et à la vérification des antécédents. Nous créerons des moyens pour que ce formulaire soit personnalisé par les recruteurs et que les questions et réponses soient capturées par le système.
Amélioration 1 :Tableau de bord personnel
Questions à répondre : Quel est le statut actuel d'une candidature soumise ? Est-il présélectionné pour un entretien ? A-t-il déjà été visionné ?
Nous pouvons garder une trace des candidatures en mettant le job_application_status_id colonne dans le job_post_activity table. Cette colonne contient l'état actuel d'une demande d'emploi. Nous devons créer une autre table, job_application_status , pour contenir tous les statuts d'application possibles. Certains statuts peuvent être "soumis", "en cours d'examen", "archivé", "rejeté", "présélectionné pour un entretien", "en cours de recrutement", etc.
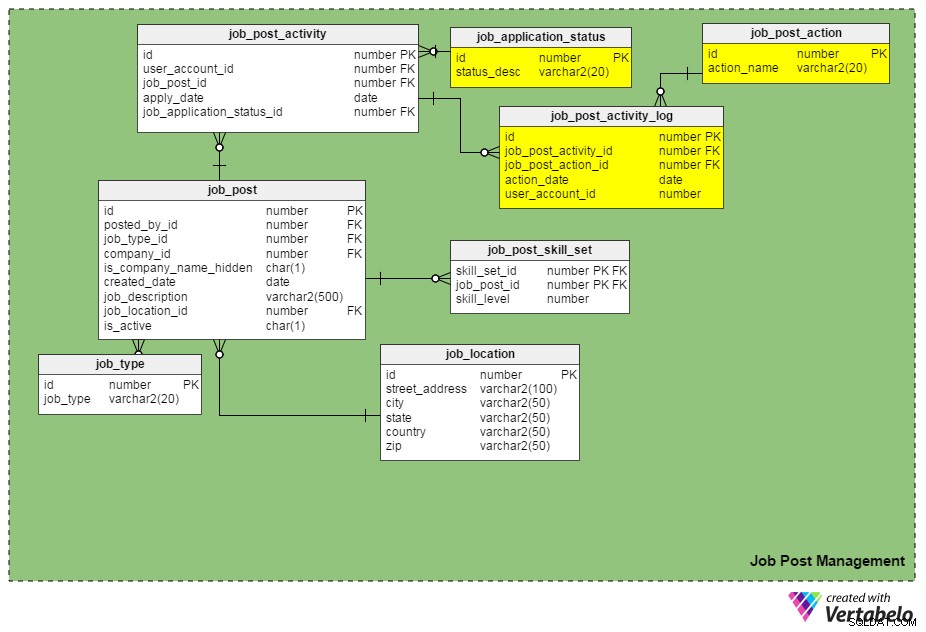
Un autre nouveau tableau, job_post_activity_log , stocke des informations concernant toutes les actions effectuées sur les candidatures, qui a effectué l'action et quand elle a été effectuée. Ce tableau contient les colonnes suivantes :
identifiant– La clé primaire de la table.job_post_activity_id– L'ID de l'application sur laquelle l'action est effectuée.job_post_action_id– L'ID de l'action effectuée. Il s'agit d'une clé étrangère liée aujob_post_actiontable. Les types d'actions que nous pouvons stocker ici incluent "soumis", "vu", "interviewé", "test écrit passé", "offre en cours", "offre envoyée", "offre acceptée", etc.action_date– La date à laquelle une action a été effectuée.user_account_id– L'identifiant de la personne qui a effectué l'action.
Est-ce que "job_post_action" est identique à "job_application_status" ? En quoi sont-ils différents ?
Ils semblent identiques au premier abord, mais ils sont en effet différents. Il existe des raisons valables pour lesquelles nous avons besoin de deux champs similaires :
- Un candidat est interviewé séparément par deux personnes ou plus. Dans ce cas, le statut de la demande d'emploi reste le même (c'est-à-dire « processus de recrutement en cours ») jusqu'à ce que toutes les séries d'entretiens soient terminées. Cependant, les enregistrements de chaque intervieweur individuel sont insérés dans le
job_post_activity_logtable, et ils ont l'action "interviewé". - Une candidature peut être consultée par plusieurs recruteurs d'une même entreprise. En utilisant ces deux attributs, vous ne perdrez pas les informations d'un candidat.
- Faire une offre à un candidat sélectionné est sujet à plusieurs approbations (c'est-à-dire l'approbation de l'équipe des finances, l'approbation du responsable du service d'embauche, etc.). Dans ce cas, le statut d'une candidature reste "offre en cours d'examen", mais la base de données peut enregistrer les approbations qui ont été approuvées et celles qui ne l'ont pas été au moyen du
job_post_activity_logtableau.
Amélioration n° 2 :un tableau de bord de profil
Questions à répondre : Qui a trouvé mon profil récemment ? Combien de fois a-t-il été consulté par les recruteurs au cours du dernier mois, de la semaine ou de la journée ? Les recruteurs des meilleures entreprises ont-ils consulté mon profil ?
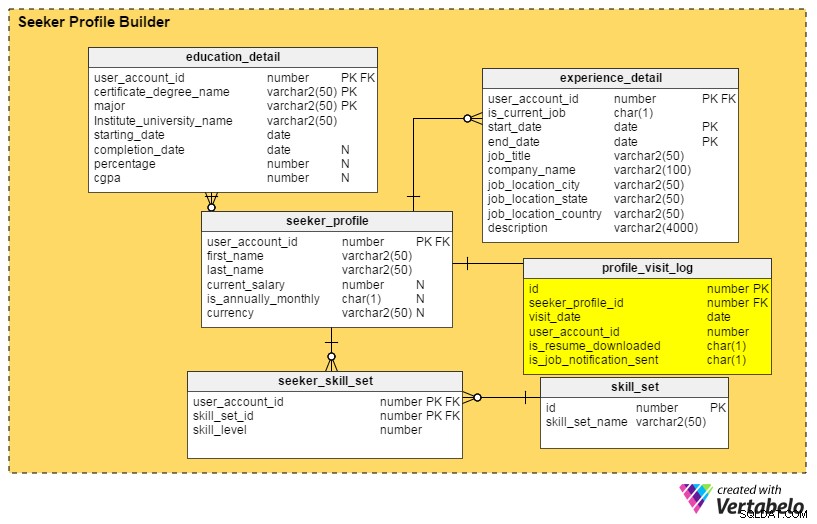
Les réponses à toutes ces questions se trouvent dans le profile_visit_log table. Ce tableau capture toutes les données de visite de profil, y compris qui a visité un profil, quand il a été consulté, etc. Les colonnes de ce tableau sont :
identifiant– La clé primaire de la table.seeker_profile_id– Quel profil a été visité.date_visite– Quand le profil a été accédé.user_account_id– Qui a vu le profil.is_resume_downloaded– Une colonne d'indicateur qui indique si le CV associé a été téléchargé lors de la visite. Cette colonne nous aidera à déterminer combien de fois un CV est téléchargé par les recruteurs.is_job_notification_sent– Une autre colonne d'indicateur, celle-ci indiquant si une notification d'emploi a été envoyée au propriétaire du profil.
Amélioration n° 3 :gestion des services payants
Question à répondre : Comment les portails en ligne peuvent-ils tirer parti de services payants supplémentaires ?
Outre une plate-forme de publication et de recherche d'emplois, de nombreux portails en ligne proposent d'autres services, tels que la création de CV d'experts, le conseil en carrière, etc. Ils proposent également des produits pour aider les demandeurs d'emploi à trouver l'emploi de leurs rêves dans la ville de leurs rêves. Par exemple, l'un des principaux sites d'emploi propose un produit qui maintient votre profil en haut des listes des recruteurs afin que vous puissiez obtenir plus d'offres d'entretien. La plupart de ces produits ou services sont disponibles sur abonnement. Lorsqu'un utilisateur achète un service ou un produit, il paie sur une période spécifique (c'est-à-dire un mois, trois mois, un an) pour l'utilisation de ce produit ou service.
En regardant ces portails d'emploi, j'ai remarqué que pratiquement aucun produit ou service n'est proposé individuellement. Pour la plupart, plusieurs produits et services sont regroupés dans un package, et ce package est proposé aux demandeurs d'emploi ou aux recruteurs.
En tenant compte de tous ces points, j'ai proposé le modèle de données suivant pour intégrer des services et des produits payants dans notre site d'emploi en ligne existant :
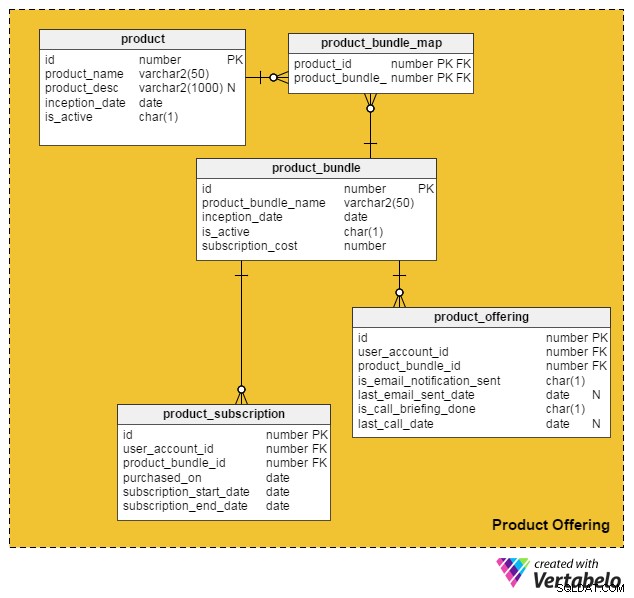
Le produit table contient des détails sur les produits individuels. (Nous appellerons les produits et les services des « produits »). Les colonnes de ce tableau sont :
identifiant– La clé primaire de cette table, qui donne un identifiant unique à chaque produit proposé sur notre portail.nom_du_produit– Contient le nom du produit.product_desc– Stocke une brève description du produit.date_création– La date à laquelle un produit a été introduit.is_active– Si un produit est actif ou non.
Étant donné que les produits et services peuvent être regroupés dans un bundle et proposés aux clients, j'ai créé le product_bundle table pour stocker les enregistrements de tous ces bundles. Les attributs sont :
identifiant– La clé primaire de la table, qui fournit un ID unique pour chaque lot de produits.product_bundle_name– Stocke le nom du bundle.date_création– La date à laquelle le lot a été introduit.is_active– Indique si un groupe est actif ou non.abonnement_coût– Stocke le prix demandé pour le lot.
Un seul produit peut-il être proposé aux clients ?
Oui. Dans ce modèle de données, un seul produit peut être son propre « bundle ». Les tableaux suivants gèrent cela et quelques autres fonctionnalités importantes.
Le product_bundle_map table stocke une liste de tous les produits qui font partie d'un bundle. Ses attributs sont explicites.
Le tableau suivant, product_subscription , entre en jeu lorsque les clients s'abonnent à des offres groupées. Il enregistre les détails de quels clients ont souscrit à quels forfaits. Les colonnes de ce tableau sont :
identifiant– La clé primaire de la table.user_account_id– L'utilisateur qui a acheté le lot.product_bundle_id– Le lot de produits acheté par l'utilisateur.acheté_sur– La date d'achat.subscription_start_date– La date de début de l'abonnement. Notez que la date d'achat du produit et la date de début de l'abonnement peuvent différer. Ainsi, nous avons deux colonnes différentes pour ceux-ci.subscription_end_date– Quand l'abonnement prendra fin.
Le tableau final, product_offering , est principalement utilisé pour le marketing. Habituellement, les portails d'emploi analysent les activités récentes des utilisateurs (à la fois les demandeurs d'emploi et les recruteurs) et décident ensuite quels produits seront bénéfiques pour quels utilisateurs. Ils utilisent ensuite des e-mails ou des appels téléphoniques pour contacter les clients avec des offres sélectionnées. Les colonnes de ce tableau sont :
identifiant– La clé primaire de la table.user_account_id– L'utilisateur ciblé par le portail d'emploi.product_bundle_id– L'offre groupée de produits que les spécialistes du marketing du portail ont adaptée à l'utilisateur.is_email_notification_sent– Si un e-mail concernant l'offre de produits a été envoyé.last_email_sent_date– La date à laquelle l'utilisateur a reçu pour la dernière fois un e-mail produit de la part de l'équipe marketing. Il est courant que les spécialistes du marketing envoient plusieurs notifications à un utilisateur et en envoient d'autres périodiquement. Cette colonne stocke la date à laquelle la dernière notification a été envoyée.is_call_briefing_done– Si le client a reçu un appel téléphonique l'informant d'un produit.date_dernier_appel–La date du dernier appel téléphonique. Plusieurs appels (appels de suivi) peuvent être passés aux clients.
Amélioration # 4 :Gestion des formulaires de pré-candidature
Question à répondre : Comment un recruteur peut-il obtenir un formulaire de consentement personnalisé rempli par tous les candidats potentiels ?
Souvent, les demandeurs d'emploi doivent répondre à des questions spécifiques lorsqu'ils postulent à un poste. Cela inclut généralement des choses comme le consentement à une vérification des antécédents criminels. Cependant, il existe divers autres types de consentements qui peuvent être nécessaires. Par exemple, un emploi dans le marketing peut nécessiter de nombreux déplacements; les emplois dans l'externalisation des processus métier (BPO) peuvent obliger les employés à travailler des quarts de nuit (c'est-à-dire tard dans la nuit). Celles-ci sont traitées dans les formulaires de pré-candidature.
Il est toujours préférable d'obtenir le consentement lorsque la demande d'emploi est soumise. De cette façon, les candidats qui ne souhaitent pas satisfaire à ces exigences ne postuleront pas au poste.
Avant de passer au modèle de données, permettez-moi de souligner quelques faits de base sur les formulaires de consentement :
- Une offre d'emploi peut avoir plusieurs formulaires de consentement.
- Chaque formulaire de consentement comporte diverses questions associées à diverses sections.
- Une question peut être définie comme obligatoire ou facultative, selon la façon dont la question est balisée dans le formulaire. Une question peut être facultative dans un formulaire et obligatoire dans un autre.
- Chaque question peut être répondue par (1) oui, (2) non ou (3) sans objet.
- Toutes les réponses seront enregistrées.
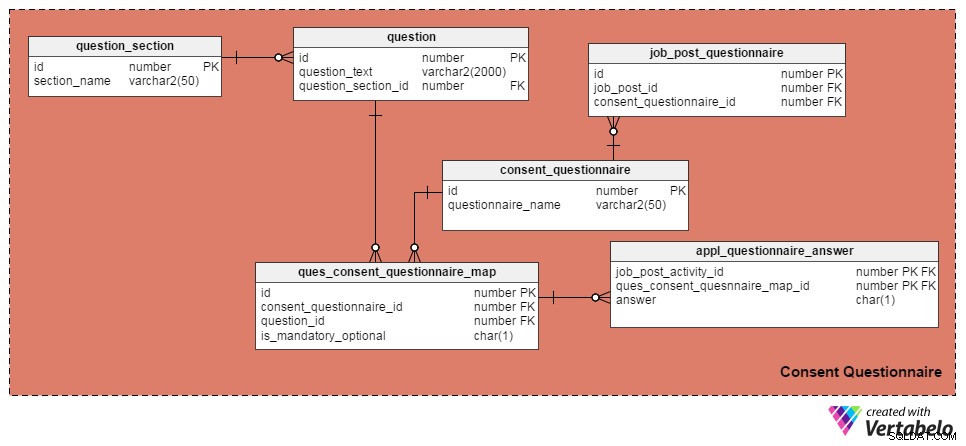
J'ai utilisé les quatre tableaux suivants pour gérer les questions et les formulaires de consentement. La première, la question table, contient une liste de questions. Il a ces attributs :
identifiant– La clé primaire de la table, qui donne un numéro d'identification unique à chaque question.question_text– Stocke le texte réel de la question.question_section_id– La section où la question apparaît. (Par exemple, "Avez-vous travaillé dans le développement de logiciels pendant au moins cinq ans ?" apparaîtrait dans la section "Expérience professionnelle".) tableau.
La question_section table stocke les informations de section. C'est une façon de regrouper les questions liées au même sujet. Mis à part le id , qui est la clé primaire de la table, le seul attribut est section_name , qui est explicite.
Le consent_questionnaire table contient les noms des formulaires de consentement. Ses deux attributs sont également explicites.
Le ques_consent_questionnaire_map table est au cœur de ce domaine. Tous les autres tableaux de ce domaine lui sont directement ou indirectement liés. Son but est de conserver une liste de questions associées aux formulaires de consentement. Les colonnes de ce tableau sont :
identifiant– La clé primaire de cette table.consent_questionnaire_id– Le numéro d'identification du formulaire de consentement.id_question– Le numéro d'identification de la question.is_mandatory_optional– Signifie si la question est obligatoire ou facultative pour un formulaire de consentement donné. Une question peut faire partie de plusieurs formulaires de consentement, mais elle peut être obligatoire dans certains et facultative dans d'autres. C'est la seule raison pour laquelle cette colonne est conservée ici au lieu de l'avoir dans laquestiontableau.
Dans les prochains tableaux, nous discuterons des formulaires de consentement des balises pour les offres d'emploi individuelles et enregistrerons les réponses des candidats. Commençons par le job_post_questionnaire table, qui stocke des informations sur les formulaires de consentement faisant partie d'une offre d'emploi. Il peut y avoir un ou plusieurs formulaires de consentement associés à une offre d'emploi. Les colonnes de ce tableau sont :
identifiant– La clé primaire de la table.job_post_id– Indique avec quelle publication d'emploi le formulaire de consentement est associé.consent_questionnaire_id– Le formulaire de consentement associé à une offre d'emploi.
Ensuite, le appl_questionnaire_answer Le tableau enregistre les réponses individuelles de chaque question du formulaire de consentement telles que remplies par les candidats. Les colonnes de ce tableau sont :
job_post_activity_id– Une colonne de clé étrangère référencée depuis lejob_post_activitytable. Il stocke des informations sur le candidat qui a répondu à la question.quest_consent_quesnnaire_map_id– Une autre colonne de clé étrangère référencée à partir duquest_consent_questionnaire_maptable. Il stocke quelle question à partir de quel formulaire de consentement est répondu.répondre– La réponse réelle du demandeur d'emploi. Je l'ai conservée sous la forme d'une colonne CHAR(1) car toutes les questions de notre modèle peuvent être répondues par "Oui" (réponse ='O'), "Non" (réponse ='N') ou "Non applicable" (réponse ='X').
Le nouveau modèle de données amélioré du portail d'emploi en ligne
Vous pouvez voir le modèle de données complet ci-dessous.
Qu'ajouteriez-vous ?
Pouvez-vous penser à d'autres fonctionnalités à ajouter à notre portail d'emploi en ligne ? Veuillez partager vos points de vue dans la section des commentaires.



