Les bases de données de séries chronologiques, comme leur nom l'indique, sont conçues pour stocker des données qui changent avec le temps. Il peut s'agir de n'importe quel type de données collectées au fil du temps. Il peut s'agir de mesures collectées à partir de certains systèmes, et en fait, tous les systèmes de tendance sont des exemples de données de séries chronologiques.
Nous avons différents types de bases de données de séries chronologiques, lesquelles devons-nous utiliser ?
Dans ce blog, nous verrons quelles sont les principales différences entre deux des principales options, TimescaleDB et InfluxDB.
InfluxDB
InfluxDB a été créé par InfluxData. Il s'agit d'une base de données de séries temporelles NoSQL personnalisée, open source, écrite en Go. Le magasin de données fournit un langage de type SQL pour interroger les données, appelé InfluxQL, ce qui facilite l'intégration des développeurs dans leurs applications. Il dispose également d'un nouveau langage de requête personnalisé appelé Flux, ce langage peut faciliter certaines tâches, mais il y a toujours une courbe d'apprentissage lors de l'adoption d'un langage de requête personnalisé.
Voici un exemple de requête Flux :
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()Dans cette base de données, chaque mesure a un horodatage et un ensemble de balises et un ensemble de champs associés. Le champ représente les valeurs réelles de lecture des mesures, tandis que la balise représente les métadonnées pour décrire les mesures. Les types de données de champ sont limités aux flottants, entiers, chaînes et booléens, et ne peuvent pas être modifiés sans réécrire les données. Les valeurs des balises sont indexées. Ils sont représentés sous forme de chaînes et ne peuvent pas être mis à jour.
InfluxDB est assez facile à démarrer, car vous n'avez pas à vous soucier de la création de schémas ou d'index. Cependant, il est assez rigide et limité, sans possibilité de créer des index supplémentaires, des index sur des champs continus, de mettre à jour les métadonnées après coup, d'appliquer la validation des données, etc.
Ce n'est pas sans schéma. Il existe un schéma sous-jacent qui est créé automatiquement à partir des données d'entrée.
InfluxDB doit implémenter à partir de zéro plusieurs outils de tolérance aux pannes, comme la réplication, la haute disponibilité et la sauvegarde/restauration, et il est responsable de sa fiabilité sur disque. Nous sommes limités à l'utilisation de ces outils et bon nombre de ces fonctionnalités, comme la haute disponibilité, ne sont disponibles que dans la version entreprise.
L'outil de sauvegarde InfluxDB peut effectuer une sauvegarde complète ou incrémentielle, et il peut être utilisé pour une récupération ponctuelle.
InfluxDB offre également une compression sur disque bien meilleure que PostgreSQL et TimescaleDB.
TimescaleDB
TimescaleDB est une base de données de séries chronologiques open source optimisée pour l'ingestion rapide et les requêtes complexes qui prend en charge le SQL complet. Il est basé sur PostgreSQL et offre le meilleur des mondes NoSQL et relationnel pour les données de séries temporelles.
Voici un exemple de requête TimescaleDB :
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
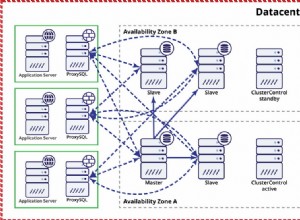
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, en tant qu'extension PostgreSQL, est une base de données relationnelle. Cela permet d'avoir une courbe d'apprentissage courte pour les nouveaux utilisateurs, et d'hériter d'outils comme pg_dump ou pg_backup pour la sauvegarde, et d'outils de haute disponibilité, ce qui est un avantage face aux autres bases de données chronologiques. Il prend également en charge la réplication en continu comme méthode principale de réplication, qui peut être utilisée dans une configuration à haute disponibilité. En termes de basculement et de sauvegardes, vous pouvez automatiser ce processus en utilisant un système externe comme ClusterControl.
Dans TimescaleDB, chaque mesure de série chronologique est enregistrée dans sa propre ligne, avec un champ de temps suivi d'un nombre quelconque d'autres champs, qui peuvent être des flottants, des entiers, des chaînes, des booléens, des tableaux, des blobs JSON, des dimensions géospatiales, date/heure/ horodatages, devises, données binaires, etc.
Vous pouvez créer des index sur n'importe quel champ (index standard) ou sur plusieurs champs (index composites), ou sur des expressions telles que des fonctions, ou même limiter un index à un sous-ensemble de lignes (index partiel). N'importe lequel de ces champs peut être utilisé comme clé étrangère pour les tables secondaires, qui peuvent ensuite stocker des métadonnées supplémentaires.
De cette façon, vous devez choisir un schéma et décider des index dont vous aurez besoin pour votre système.
Performances
Si nous parlons de performances, nous pouvons consulter le super blog de comparaison TimescaleDB. Vous y trouverez une comparaison détaillée des performances entre les deux bases de données avec des graphiques et des mesures. Voyons quelques-unes des informations les plus importantes de ce blog.
Encarts
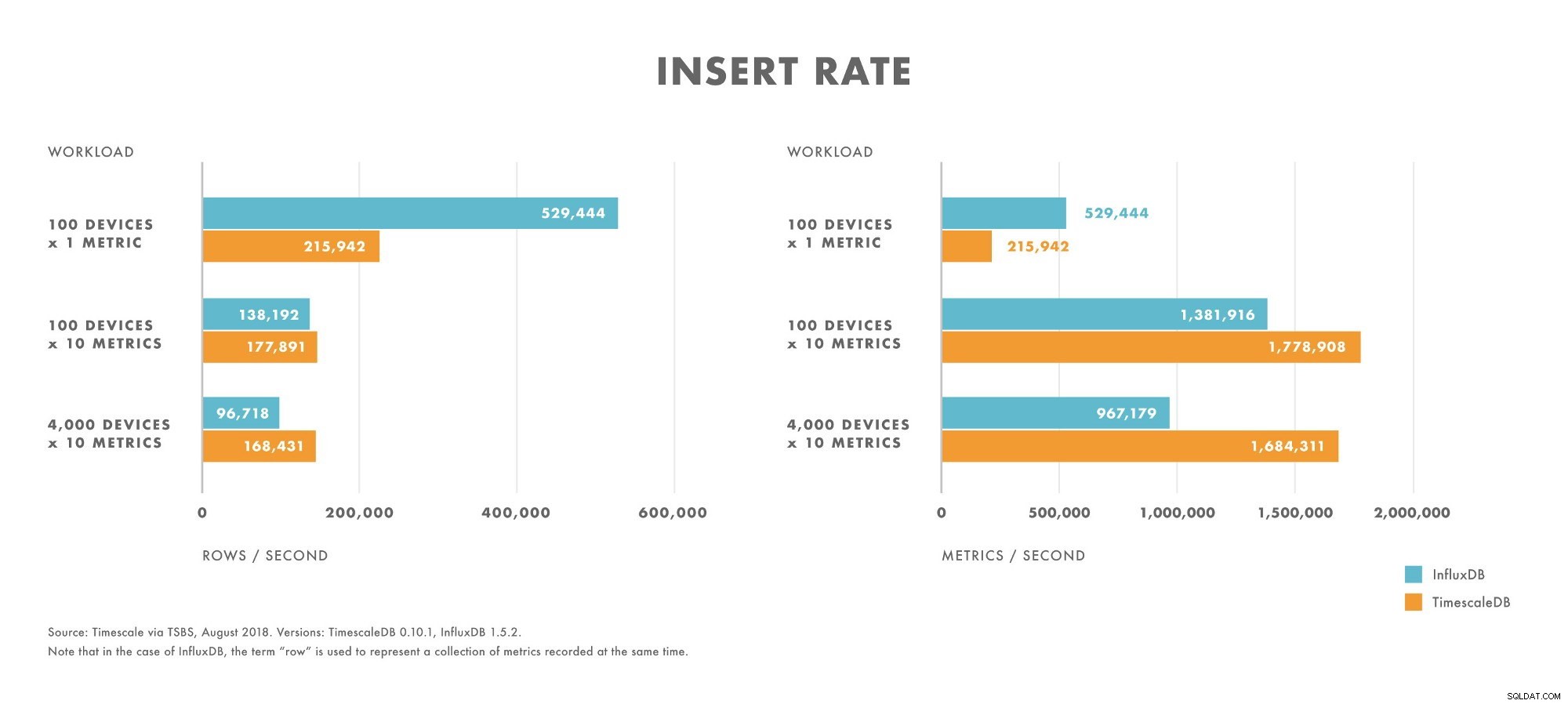
- Pour les charges de travail à très faible cardinalité (par exemple, 100 appareils), InfluxDB surpasse TimescaleDB.
- À mesure que la cardinalité augmente, les performances d'insertion d'InfluxDB chutent plus rapidement que sur TimescaleDB.
- Pour les charges de travail avec une cardinalité modérée à élevée (par exemple, 100 appareils envoyant 10 métriques), TimescaleDB surpasse InfluxDB.

Latence de lecture
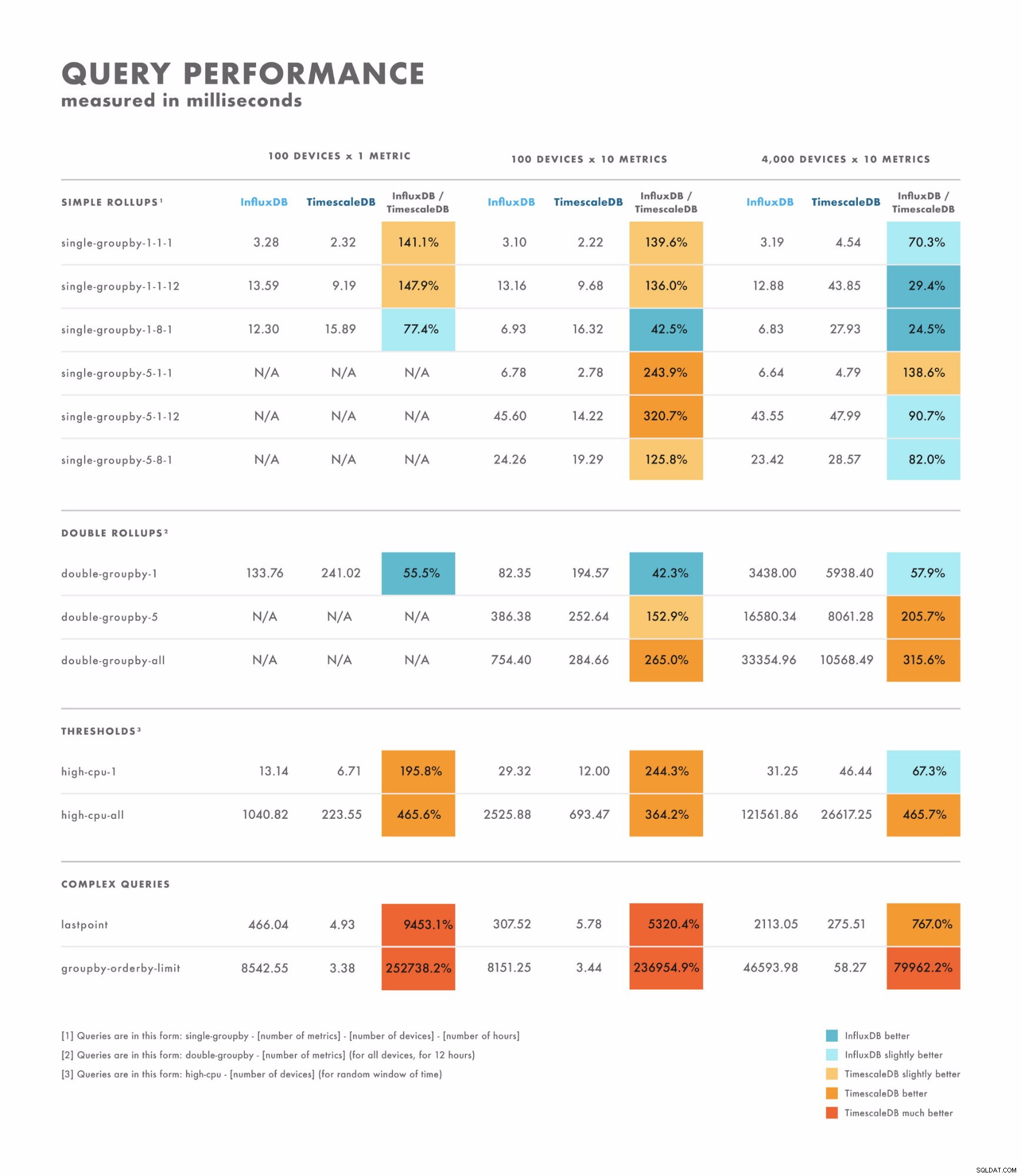
- Pour les requêtes simples, les résultats varient assez :pour certaines, une base de données est clairement meilleure que l'autre, tandis que pour d'autres, cela dépend de la cardinalité de votre ensemble de données. La différence ici est souvent de l'ordre des millisecondes à un chiffre et à deux chiffres.
- Pour les requêtes complexes, TimescaleDB surpasse largement InfluxDB et prend en charge un plus large éventail de types de requêtes. La différence ici est souvent de l'ordre de quelques secondes à des dizaines de secondes.
- Dans cet esprit, la meilleure façon de tester correctement consiste à comparer les requêtes que vous prévoyez d'exécuter.
Problèmes de stabilité
- InfluxDB présente des problèmes de stabilité et de performances à des cardinalités élevées (plus de 100 000).
Conclusion
Si vos données correspondent au modèle de données InfluxDB et que vous ne vous attendez pas à changer à l'avenir, vous devriez envisager d'utiliser InfluxDB car ce modèle est plus facile à démarrer et, comme la plupart des bases de données qui utilisent une approche orientée colonne, offre une meilleure compression sur disque que PostgreSQL et TimescaleDB.
Cependant, le modèle relationnel est plus polyvalent et offre plus de fonctionnalités, de flexibilité et de contrôle que le modèle InfluxDB. Ceci est particulièrement important à mesure que votre application évolue. Et lors de la planification de votre système, vous devez tenir compte à la fois de ses besoins actuels et futurs.
Dans ce blog, nous avons pu voir une courte comparaison entre TimescaleDB et InfluxDB, et nous pourrions dire que TimescaleDB en tant qu'extension PostgreSQL, semble assez mature et riche en fonctionnalités car il hérite beaucoup de PostgreSQL. Mais vous pouvez prendre votre propre décision en fonction des avantages et des inconvénients mentionnés précédemment dans ce blog et vous assurer de comparer votre propre charge de travail. Bonne chance dans ce nouveau monde de bases de données de séries chronologiques !