Le moteur d'exécution des requêtes SQL Server propose deux manières d'implémenter une opération logique « union all », à l'aide des opérateurs physiques de concaténation et de fusion, de jointure et de concaténation. Bien que l'opération logique soit la même, il existe des différences importantes entre les deux opérateurs physiques qui peuvent faire une énorme différence dans l'efficacité de vos plans d'exécution.
L'optimiseur de requête fait un travail raisonnable en choisissant entre les deux options dans de nombreux cas, mais il est loin d'être parfait dans ce domaine. Cet article décrit les opportunités de réglage des requêtes présentées par Merge Join Concatenation et détaille les comportements internes et les considérations dont vous devez être conscient pour en tirer le meilleur parti.
Concaténation

L'opérateur de concaténation est relativement simple :sa sortie est le résultat d'une lecture complète de chacune de ses entrées en séquence. L'opérateur de concaténation est un n-aire opérateur physique, ce qui signifie qu'il peut avoir '2…n' entrées. Pour illustrer, revoyons l'exemple basé sur AdventureWorks de mon article précédent, "Réécriture des requêtes pour améliorer les performances":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
La requête suivante répertorie les ID de produit et de transaction pour six produits particuliers :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Il produit un plan d'exécution comportant un opérateur de concaténation avec six entrées, comme on le voit dans SQL Sentry Plan Explorer :
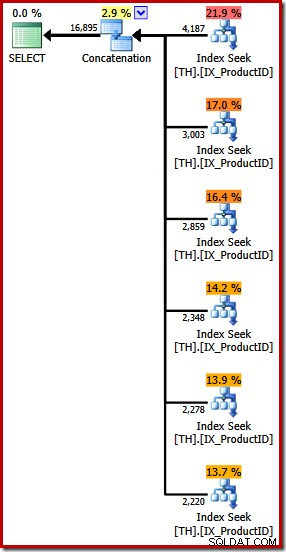
Le plan ci-dessus comporte une recherche d'index distincte pour chaque ID de produit répertorié, dans le même ordre que celui spécifié dans la requête (lecture de haut en bas). La recherche d'index la plus haute est pour le produit 870, la suivante pour le produit 873, puis 921 et ainsi de suite. Bien sûr, rien de tout cela n'est un comportement garanti, c'est juste quelque chose d'intéressant à observer.
J'ai mentionné précédemment que l'opérateur de concaténation forme sa sortie en lisant à partir de ses entrées en séquence. Lorsque ce plan est exécuté, il y a de fortes chances que le jeu de résultats affiche d'abord les lignes du produit 870, puis 873, 921, 712, 707 et enfin le produit 711. Encore une fois, cela n'est pas garanti car nous n'avons pas spécifié de commande Clause BY, mais elle montre comment la concaténation fonctionne en interne.
Un "plan d'exécution" SSIS
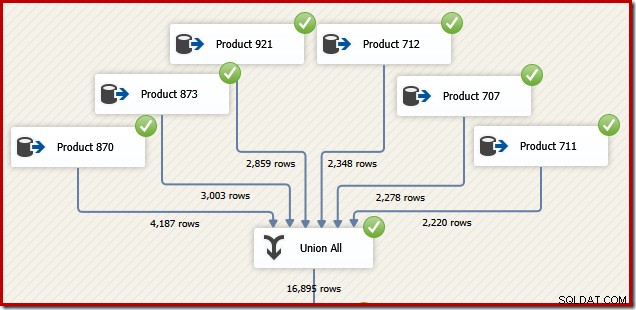
Pour des raisons qui auront du sens dans un instant, réfléchissez à la façon dont nous pourrions concevoir un package SSIS pour effectuer la même tâche. Nous pourrions certainement aussi écrire le tout sous la forme d'une seule instruction T-SQL dans SSIS, mais l'option la plus intéressante consiste à créer une source de données distincte pour chaque produit et à utiliser un composant SSIS "Union All" à la place de la concaténation SQL Server. opérateur :
Imaginons maintenant que nous ayons besoin de la sortie finale de ce flux de données dans l'ordre des ID de transaction. Une option serait d'ajouter un composant Sort explicite après Union All :
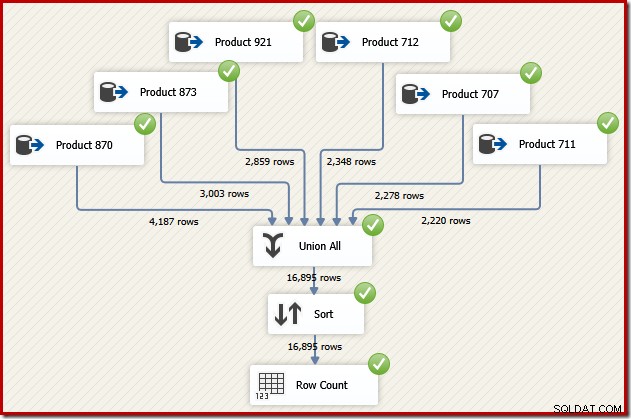
Cela ferait certainement l'affaire, mais un concepteur SSIS qualifié et expérimenté se rendrait compte qu'il existe une meilleure option :lisez les données source de chaque produit dans l'ordre de l'ID de transaction (en utilisant l'index), puis utilisez une opération de préservation de l'ordre pour combiner les ensembles. .
Dans SSIS, le composant qui combine les lignes de deux flux de données triés en un seul flux de données trié est appelé "Fusionner". Un flux de données SSIS repensé qui utilise la fusion pour renvoyer les lignes souhaitées dans l'ordre des ID de transaction suit :
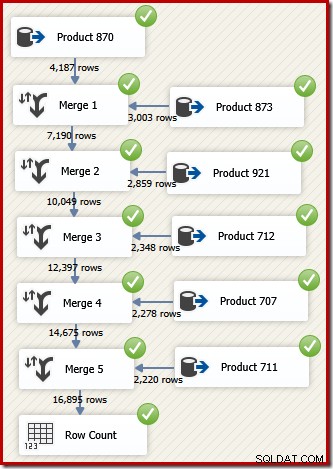
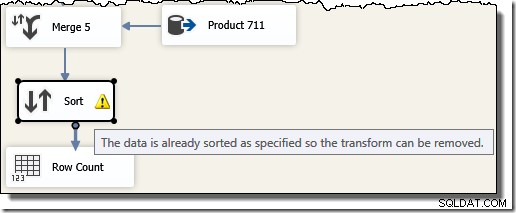
Notez que nous avons besoin de cinq composants Merge distincts car Merge est un composant binaire, contrairement au composant SSIS "Union All", qui était n-ary . Le nouveau flux de fusion produit des résultats dans l'ordre des ID de transaction, sans nécessiter de composant de tri coûteux (et bloquant). En effet, si nous essayons d'ajouter un ID de tri sur transaction après la fusion finale, SSIS affiche un avertissement pour nous faire savoir que le flux est déjà trié de la manière souhaitée :
Le point de l'exemple SSIS peut maintenant être révélé. Regardez le plan d'exécution choisi par l'optimiseur de requête SQL Server lorsque nous lui demandons de renvoyer les résultats de la requête T-SQL d'origine dans l'ordre des ID de transaction (en ajoutant une clause ORDER BY) :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
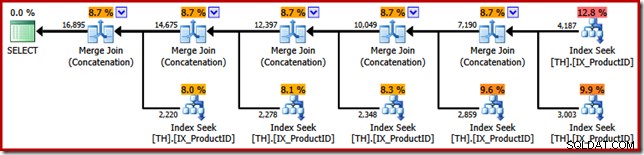
Les similitudes avec le package SSIS Merge sont frappantes. même jusqu'à la nécessité de cinq opérateurs binaires "Merge". La seule différence importante est que SSIS a des composants distincts pour "Merge Join" et "Merge" alors que SQL Server utilise le même opérateur de base pour les deux.
Pour être clair, les opérateurs Merge Join (Concaténation) dans le plan d'exécution SQL Server ne sont pas effectuer une jointure ; le moteur réutilise simplement le même opérateur physique pour implémenter l'union préservant l'ordre tout.
Rédaction de plans d'exécution dans SQL Server
SSIS n'a pas de langage de spécification de flux de données, ni d'optimiseur pour transformer une telle spécification en une tâche de flux de données exécutable. Il appartient au concepteur de packages SSIS de se rendre compte qu'une fusion préservant l'ordre est possible, de définir les propriétés des composants (telles que les clés de tri) de manière appropriée, puis de comparer les performances. Cela demande plus d'efforts (et de compétences) de la part du concepteur, mais cela offre un degré de contrôle très fin.
La situation dans SQL Server est l'inverse :nous écrivons une spécification de requête en utilisant le langage T-SQL, puis dépendez de l'optimiseur de requête pour explorer les options d'implémentation et en choisir une efficace. Nous n'avons pas la possibilité de construire directement un plan d'exécution. La plupart du temps, cela est hautement souhaitable :SQL Server serait sans doute un peu moins populaire si chaque requête nous obligeait à écrire un package de type SSIS.
Néanmoins (comme expliqué dans mon post précédent), le plan choisi par l'optimiseur peut être sensible au T-SQL utilisé pour décrire les résultats souhaités. En répétant l'exemple de cet article, nous aurions pu écrire la requête T-SQL d'origine en utilisant une syntaxe alternative :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Cette requête spécifie exactement le même jeu de résultats qu'auparavant, mais l'optimiseur ne considère pas un plan de préservation de l'ordre (concaténation de fusion), choisissant d'analyser l'index clusterisé à la place (une option beaucoup moins efficace) :
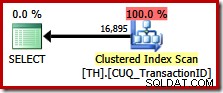
Exploiter la préservation des commandes dans SQL Server
Éviter les tris inutiles peut entraîner des gains d'efficacité significatifs, qu'il s'agisse de SSIS ou de SQL Server. Atteindre cet objectif peut être plus compliqué et difficile dans SQL Server car nous n'avons pas un contrôle aussi précis sur le plan d'exécution, mais il y a encore des choses que nous pouvons faire.
Plus précisément, comprendre le fonctionnement interne de l'opérateur SQL Server Merge Join Concatenation peut nous aider à continuer à écrire du T-SQL relationnel clair, tout en encourageant l'optimiseur de requêtes à envisager des options de traitement préservant l'ordre (fusion) le cas échéant.
Fonctionnement de la concaténation par fusion/joindre

Une jointure de fusion standard nécessite que les deux entrées soient triées sur les clés de jointure. Merge Join Concatenation, d'autre part, fusionne simplement deux flux déjà ordonnés en un seul flux ordonné - il n'y a pas de jointure en tant que telle.
Cela soulève la question :quel est exactement "l'ordre" qui est préservé ?
Dans SSIS, nous devons définir les propriétés de la clé de tri sur les entrées de fusion pour définir l'ordre. SQL Server n'a pas d'équivalent à cela. La réponse à la question ci-dessus est un peu compliquée, nous allons donc procéder étape par étape.
Prenons l'exemple suivant, qui demande une concaténation de fusion de deux tables de tas non indexées (le cas le plus simple) :
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Ces deux tables n'ont pas d'index et il n'y a pas de clause ORDER BY. Quel ordre la concaténation de jointure de fusion « préservera-t-elle » ? Pour vous donner un moment pour y réfléchir, examinons d'abord le plan d'exécution produit pour la requête ci-dessus dans les versions de SQL Server avant 2012 :
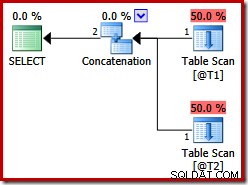
Il n'y a pas de concaténation de jointure de fusion, malgré l'indicateur de requête :avant SQL Server 2012, cet indicateur ne fonctionne qu'avec UNION, pas UNION ALL. Pour obtenir un plan avec l'opérateur de fusion souhaité, nous devons désactiver l'implémentation d'un UNION ALL logique (UNIA) à l'aide de l'opérateur physique de concaténation (CON). Veuillez noter que les éléments suivants ne sont pas documentés et ne sont pas pris en charge pour une utilisation en production :
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Cette requête produit le même plan que SQL Server 2012 et 2014 avec l'indicateur de requête MERGE UNION seul :
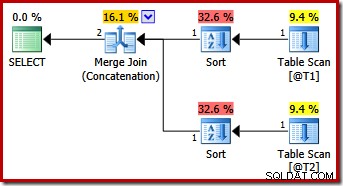
Peut-être de manière inattendue, le plan d'exécution comporte des tris explicites sur les deux entrées de la fusion. Les propriétés de tri sont :
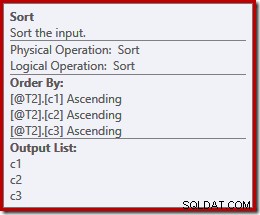
Il est logique qu'une fusion préservant l'ordre nécessite un ordre d'entrée cohérent, mais pourquoi a-t-elle choisi (c1, c2, c3) au lieu de, disons (c3, c1, c2) ou (c2, c3, c1) ? Comme point de départ, les entrées de concaténation de fusion sont triées sur la liste de projection de sortie. L'étoile de sélection dans la requête se développe en (c1, c2, c3) de sorte que c'est l'ordre choisi.
Trier par liste de projection de sortie de fusion
Pour illustrer davantage ce point, nous pouvons développer nous-mêmes l'étoile de sélection (comme il se doit !) en choisissant un ordre différent (c3, c2, c1) pendant que nous y sommes :
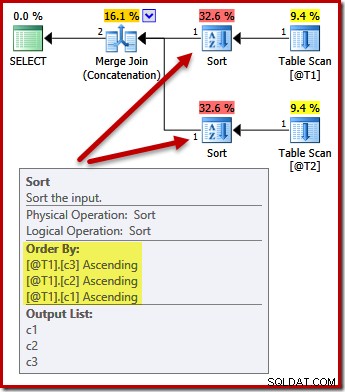
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Les tris changent maintenant pour correspondre (c3, c2, c1):
Encore une fois, la requête résultat order (en supposant que nous devions ajouter des données aux tables) n'est pas garanti d'être trié comme indiqué, car nous n'avons pas de clause ORDER BY. Ces exemples visent simplement à montrer comment l'optimiseur sélectionne un ordre de tri d'entrée initial, en l'absence de toute autre raison de trier.
Ordres de tri conflictuels
Considérons maintenant ce qui se passe si nous laissons la liste de projection comme (c3, c2, c1) et ajoutons une exigence pour ordonner les résultats de la requête par (c1, c2, c3). Les entrées de la fusion seront-elles toujours triées sur (c3, c2, c1) avec un tri post-fusion sur (c1, c2, c3) pour satisfaire ORDER BY ?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Non. L'optimiseur est suffisamment intelligent pour éviter de trier deux fois :
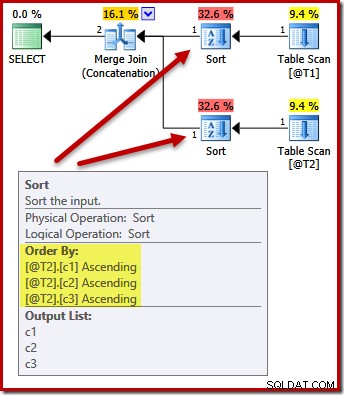
Le tri des deux entrées sur (c1, c2, c3) est parfaitement acceptable pour la concaténation de fusion, donc aucun double tri n'est requis.
Notez que ce plan fait garantir que l'ordre des résultats sera (c1, c2, c3). Le plan ressemble aux plans précédents sans ORDER BY, mais tous les détails internes ne sont pas présentés dans les plans d'exécution visibles par l'utilisateur.
L'effet d'unicité
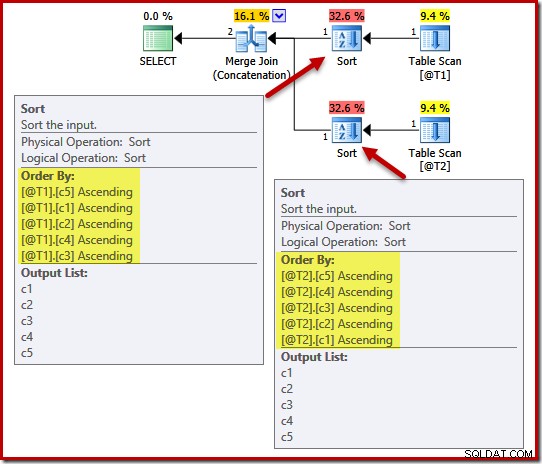
Lors du choix d'un ordre de tri pour les entrées de fusion, l'optimiseur est également affecté par toutes les garanties d'unicité qui existent. Considérez l'exemple suivant, avec cinq colonnes, mais notez les différents ordres de colonnes dans l'opération UNION ALL :
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Le plan d'exécution comprend des tris sur (c5, c1, c2, c4, c3) pour la table @T1 et (c5, c4, c3, c2, c1) pour la table @T2 :
Pour démontrer l'effet de l'unicité sur ces tris, nous allons ajouter une contrainte UNIQUE à la colonne c1 de la table T1, et à la colonne c4 de la table T2 :
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
L'intérêt de l'unicité est que l'optimiseur sait qu'il peut arrêter le tri dès qu'il rencontre une colonne dont l'unicité est garantie. Trier par colonnes supplémentaires après avoir rencontré une clé unique n'affectera pas l'ordre de tri final, par définition.
Avec les contraintes UNIQUE en place, l'optimiseur peut simplifier la liste de tri (c5, c1, c2, c4, c3) pour T1 à (c5, c1) car c1 est unique. De même, la liste de tri (c5, c4, c3, c2, c1) pour T2 est simplifiée en (c5, c4) car c4 est une clé :
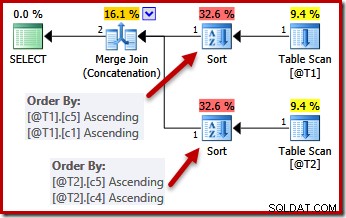
Parallélisme
La simplification due à une clé unique n'est pas parfaitement mise en œuvre. Dans un plan parallèle, les flux sont partitionnés de sorte que toutes les lignes d'une même instance de la fusion se retrouvent sur le même thread. Ce partitionnement du jeu de données est basé sur les colonnes de fusion, et non simplifié par la présence d'une clé.
Le script suivant utilise l'indicateur de trace non pris en charge 8649 pour générer un plan parallèle pour la requête précédente (qui reste inchangé autrement) :
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
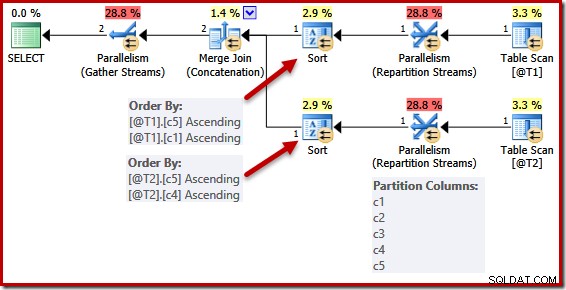
Les listes de tri sont simplifiées comme auparavant, mais les opérateurs Repartition Streams partitionnent toujours toutes les colonnes. Si cette simplification était implémentée de manière cohérente, les opérateurs de repartitionnement fonctionneraient également sur (c5, c1) et (c5, c4) seuls.
Problèmes avec les index non uniques
La façon dont l'optimiseur raisonne sur les exigences de tri pour la concaténation des fusions peut entraîner des problèmes de tri inutiles, comme le montre l'exemple suivant :
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
En regardant la requête et les index disponibles, nous nous attendrions à un plan d'exécution qui effectue une analyse ordonnée des index clusterisés, en utilisant la concaténation de jointure de fusion pour éviter le besoin de tout tri. Cette attente est pleinement justifiée, car les index clusterisés fournissent l'ordre spécifié dans la clause ORDER BY. Malheureusement, le plan que nous obtenons comprend en fait deux types :
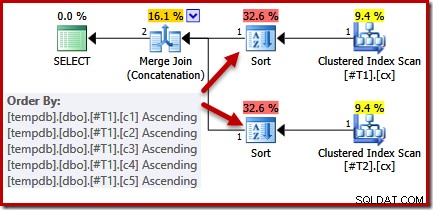
Il n'y a aucune bonne raison pour ces tris, ils n'apparaissent que parce que la logique de l'optimiseur de requête est imparfaite. La liste de colonnes de sortie de fusion (c1, c2, c3, c4, c5) est un sur-ensemble de ORDER BY, mais il n'y a pas d'élément unique clé pour simplifier cette liste. En raison de cette lacune dans le raisonnement de l'optimiseur, il conclut que la fusion nécessite son entrée triée sur (c1, c2, c3, c4, c5).
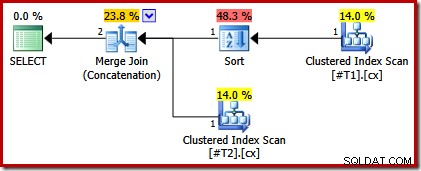
Nous pouvons vérifier cette analyse en modifiant le script pour rendre unique l'un des index clusterisés :
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Le plan d'exécution n'a plus qu'un tri au-dessus de la table avec l'index non unique :
Si nous faisons maintenant les deux index clusterisés uniques, aucun tri n'apparaît :
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Avec les deux index uniques, les listes de tri d'entrée de fusion initiales peuvent être simplifiées à la seule colonne c1. La liste simplifiée correspond alors exactement à la clause ORDER BY, donc aucun tri n'est nécessaire dans le plan final :
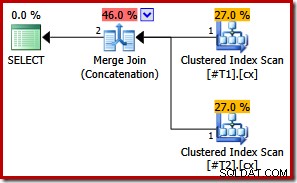
Notez que nous n'avons même pas besoin de l'indicateur de requête dans ce dernier exemple pour obtenir le plan d'exécution optimal.
Réflexions finales
Éliminer les tris dans un plan d'exécution peut être délicat. Dans certains cas, cela peut être aussi simple que de modifier un index existant (ou d'en fournir un nouveau) pour fournir des lignes dans l'ordre requis. L'optimiseur de requête fait globalement un travail raisonnable lorsque les index appropriés sont disponibles.
Dans (de nombreux) autres cas cependant, éviter les tris peut nécessiter une compréhension beaucoup plus approfondie du moteur d'exécution, de l'optimiseur de requêtes et des opérateurs de plan eux-mêmes. Éviter les tris est sans aucun doute un sujet avancé de réglage des requêtes, mais aussi un sujet incroyablement gratifiant lorsque tout se passe bien.