De nos jours, la réplication est une donnée dans un environnement à haute disponibilité et tolérant aux pannes pour pratiquement toutes les technologies de base de données que vous utilisez. C'est un sujet que nous avons vu maintes et maintes fois, mais qui ne vieillit jamais.
Si vous utilisez TimescaleDB, le type de réplication le plus courant est la réplication en continu, mais comment ça marche ?
Dans ce blog, nous allons passer en revue certains concepts liés à la réplication et nous nous concentrerons sur la réplication en continu pour TimescaleDB, qui est une fonctionnalité héritée du moteur PostgreSQL sous-jacent. Ensuite, nous verrons comment ClusterControl peut nous aider à le configurer.
Ainsi, la réplication en continu est basée sur la livraison des enregistrements WAL et leur application au serveur de secours. Voyons d'abord ce qu'est WAL.
WAL
Write Ahead Log (WAL) est une méthode standard pour assurer l'intégrité des données, elle est automatiquement activée par défaut.
Les WAL sont les journaux REDO dans TimescaleDB. Mais que sont les journaux REDO ?
Les journaux REDO contiennent toutes les modifications apportées à la base de données et sont utilisés par la réplication, la restauration, la sauvegarde en ligne et la restauration ponctuelle (PITR). Toutes les modifications qui n'ont pas été appliquées aux pages de données peuvent être rétablies à partir des journaux REDO.
L'utilisation de WAL réduit considérablement le nombre d'écritures sur disque, car seul le fichier journal doit être vidé sur le disque pour garantir qu'une transaction est validée, plutôt que tous les fichiers de données modifiés par la transaction.
Un enregistrement WAL précisera, bit par bit, les modifications apportées aux données. Chaque enregistrement WAL sera ajouté dans un fichier WAL. La position d'insertion est un numéro de séquence de journal (LSN) qui est un décalage d'octets dans les journaux, augmentant à chaque nouvel enregistrement.
Les WAL sont stockés dans le répertoire pg_wal, sous le répertoire data. Ces fichiers ont une taille par défaut de 16 Mo (la taille peut être modifiée en modifiant l'option de configuration --with-wal-segsize lors de la construction du serveur). Ils ont un nom incrémentiel unique, au format suivant :"00000001 00000000 00000000".
Le nombre de fichiers WAL contenus dans pg_wal dépendra de la valeur attribuée aux paramètres min_wal_size et max_wal_size dans le fichier de configuration postgresql.conf.
Un paramètre que nous devons configurer lors de la configuration de toutes nos installations TimescaleDB est le wal_level. Il détermine la quantité d'informations écrites dans le WAL. La valeur par défaut est minimale, qui n'écrit que les informations nécessaires pour récupérer d'un plantage ou d'un arrêt immédiat. Archive ajoute la journalisation requise pour l'archivage WAL ; hot_standby ajoute en outre les informations requises pour exécuter des requêtes en lecture seule sur un serveur de secours ; et, enfin, logique ajoute les informations nécessaires pour prendre en charge le décodage logique. Ce paramètre nécessite un redémarrage, il peut donc être difficile de le modifier sur les bases de données de production en cours d'exécution si nous l'avons oublié.
Réplication en continu
La réplication en continu est basée sur la méthode d'envoi de journaux. Les enregistrements WAL sont directement déplacés d'un serveur de base de données vers un autre pour être appliqués. On peut dire que c'est un PITR continu.
Ce transfert est effectué de deux manières différentes, en transférant les enregistrements WAL un fichier (segment WAL) à la fois (envoi de journaux basé sur fichier) et en transférant les enregistrements WAL (un fichier WAL est composé d'enregistrements WAL) à la volée (enregistrement basé log shipping), entre un serveur maître et un ou plusieurs serveurs esclaves, sans attendre que le fichier WAL soit rempli.
En pratique, un processus appelé récepteur WAL, s'exécutant sur le serveur esclave, se connectera au serveur maître à l'aide d'une connexion TCP/IP. Dans le serveur maître, un autre processus existe, nommé WAL sender, et est chargé d'envoyer les registres WAL au serveur esclave au fur et à mesure qu'ils se produisent.
La réplication en continu peut être représentée comme suit :
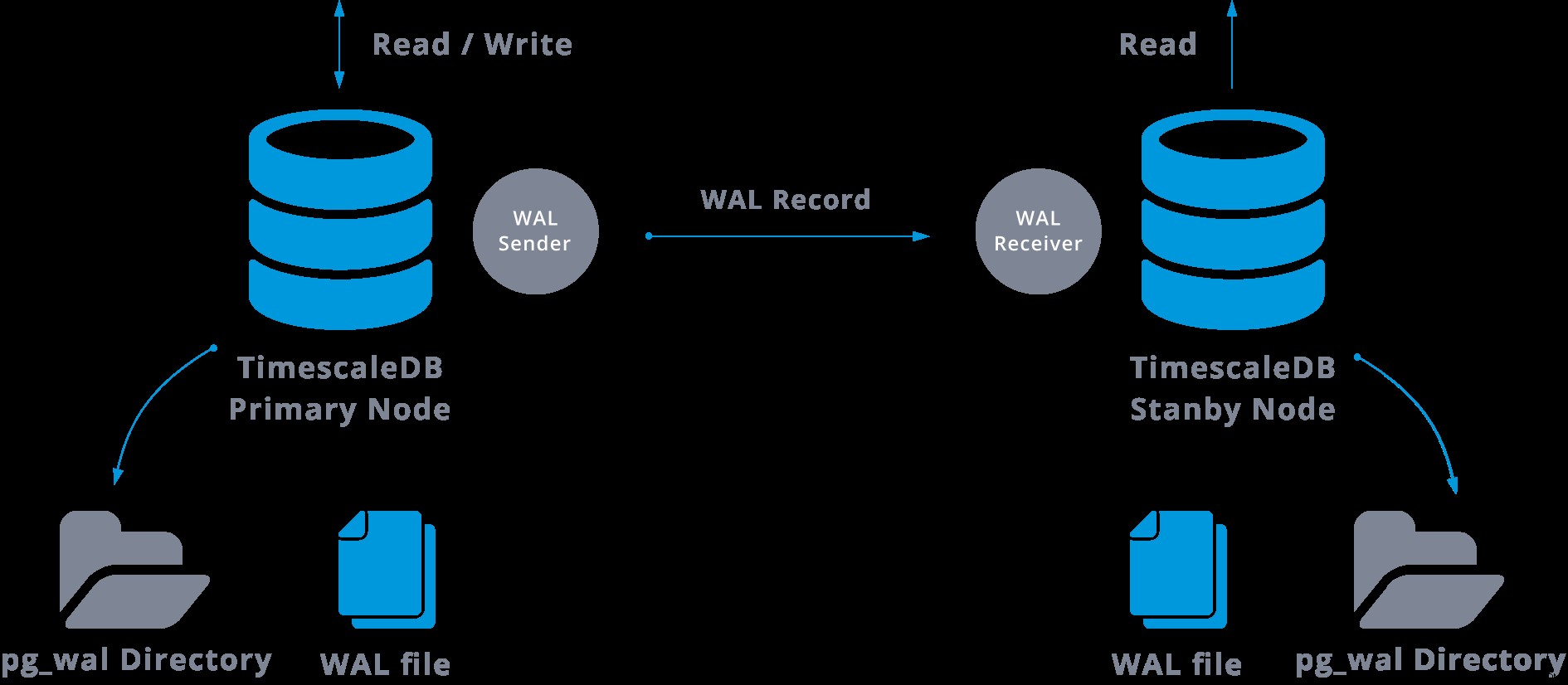
En regardant le diagramme ci-dessus, nous pouvons penser, que se passe-t-il lorsque la communication entre l'expéditeur WAL et le récepteur WAL échoue ?
Lors de la configuration de la réplication en continu, nous avons la possibilité d'activer l'archivage WAL.
Cette étape n'est en fait pas obligatoire, mais est extrêmement importante pour une configuration de réplication robuste, car il est nécessaire d'éviter que le serveur principal ne recycle d'anciens fichiers WAL qui n'ont pas encore été appliqués à l'esclave. Si cela se produit, nous devrons recréer la réplique à partir de zéro.
Lors de la configuration de la réplication avec archivage continu, nous partons d'une sauvegarde et, pour atteindre l'état de synchronisation avec le maître, nous devons appliquer toutes les modifications hébergées dans le WAL qui se sont produites après la sauvegarde. Au cours de ce processus, le standby restaurera d'abord tous les WAL disponibles dans l'emplacement de l'archive (fait en appelant restore_command). La commande restore_command échouera lorsque nous atteindrons le dernier enregistrement WAL archivé, donc après cela, le standby va regarder dans le répertoire pg_wal pour voir si le changement existe là-bas (ceci est en fait fait pour éviter la perte de données lorsque les serveurs maîtres se bloquent et certains les modifications qui ont déjà été déplacées dans la réplique et qui y ont été appliquées n'ont pas encore été archivées).
Si cela échoue et que l'enregistrement demandé n'y existe pas, il commencera à communiquer avec le maître via la réplication en continu.
Chaque fois que la réplication en continu échoue, elle revient à l'étape 1 et restaure à nouveau les enregistrements à partir de l'archive. Cette boucle de récupération à partir de l'archive, pg_wal, et via la réplication en continu se poursuit jusqu'à ce que le serveur soit arrêté ou que le basculement soit déclenché par un fichier déclencheur.
Ce sera un schéma d'une telle configuration :
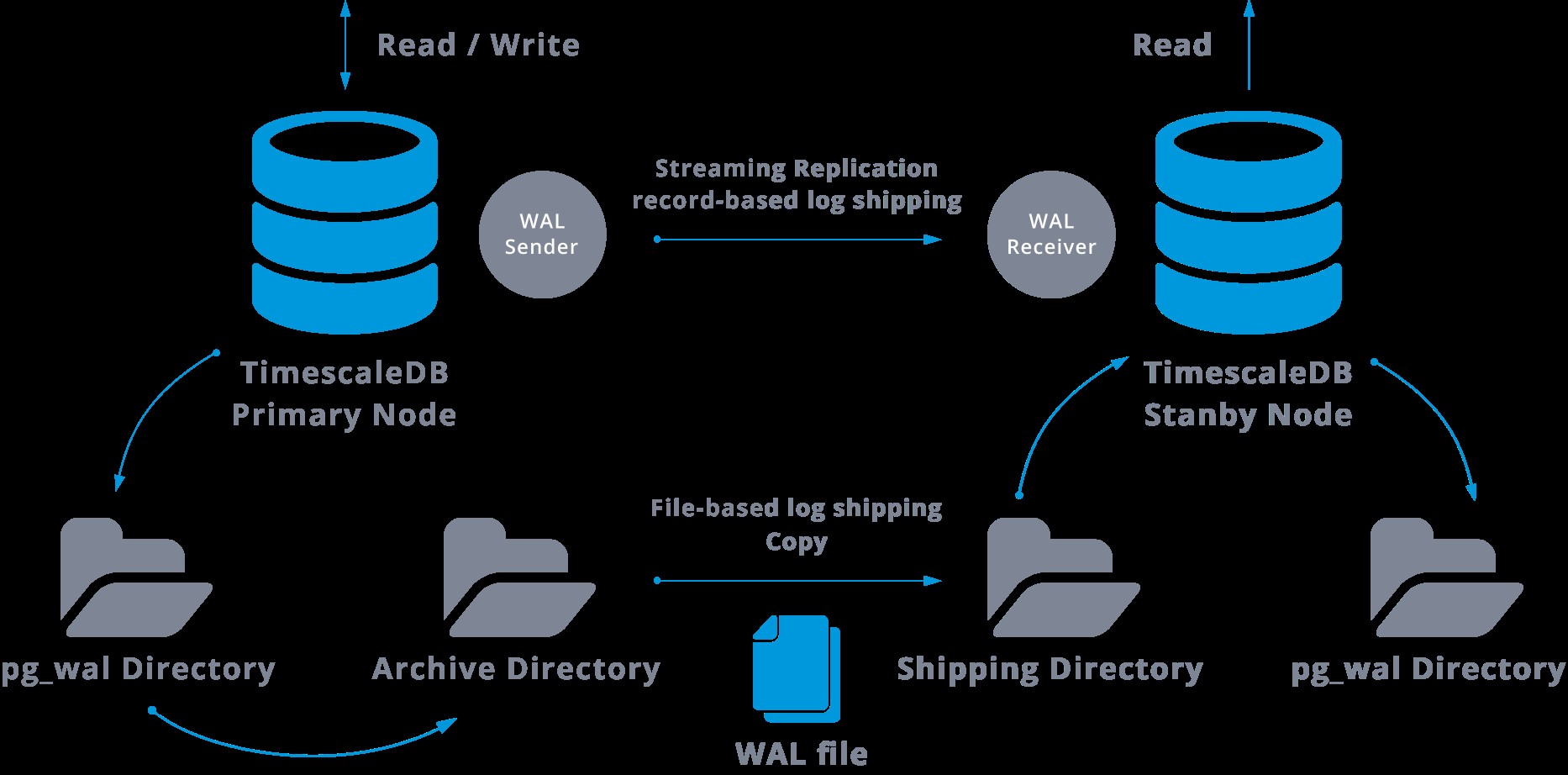
La réplication en continu est asynchrone par défaut, donc à un moment donné, nous pouvons avoir des transactions qui peuvent être validées dans le maître et pas encore répliquées dans le serveur de secours. Cela implique une perte potentielle de données.
Cependant, ce délai entre la validation et l'impact des modifications dans la réplique est censé être très faible (quelques millisecondes), en supposant bien sûr que le serveur de réplique soit suffisamment puissant pour suivre la charge.
Pour les cas où même le risque d'une petite perte de données n'est pas tolérable, nous pouvons utiliser la fonctionnalité de réplication synchrone.
Dans la réplication synchrone, chaque validation d'une transaction d'écriture attendra jusqu'à ce que la confirmation soit reçue que la validation a été écrite dans le journal d'écriture anticipée sur le disque du serveur principal et du serveur de secours.
Cette méthode minimise la possibilité de perte de données, car pour que cela se produise, nous aurons besoin que le maître et le standby échouent en même temps.
L'inconvénient évident de cette configuration est que le temps de réponse pour chaque transaction d'écriture augmente, car nous devons attendre que toutes les parties aient répondu. Ainsi, le temps d'un commit est, au minimum, l'aller-retour entre le maître et la réplique. Les transactions en lecture seule ne seront pas affectées par cela.
Pour configurer la réplication synchrone, nous avons besoin que chacun des serveurs de secours spécifie un nom d'application dans le primary_conninfo du fichier recovery.conf :primary_conninfo ='...aplication_name=slaveX' .
Il faut aussi préciser la liste des serveurs standby qui vont participer à la réplication synchrone :synchronous_standby_name ='slaveX,slaveY'.
Nous pouvons configurer un ou plusieurs serveurs synchrones, et ce paramètre spécifie également la méthode (FIRST et ANY) pour choisir les standbys synchrones parmi ceux listés.
Pour déployer TimescaleDB avec des configurations de réplication en continu (synchrone ou asynchrone), nous pouvons utiliser ClusterControl, comme nous pouvons le voir ici.
Une fois que nous avons configuré notre réplication et qu'elle est opérationnelle, nous aurons besoin de fonctionnalités supplémentaires pour la surveillance et la gestion des sauvegardes. ClusterControl nous permet de surveiller et de gérer les sauvegardes/rétentions de notre cluster TimescaleDB depuis le même endroit sans aucun outil externe.
Comment configurer la réplication en continu sur TimescaleDB
La configuration de la réplication en continu est une tâche qui nécessite de suivre attentivement certaines étapes. Si vous souhaitez le configurer manuellement, vous pouvez suivre notre blog à ce sujet.
Cependant, vous pouvez déployer ou importer votre TimescaleDB actuel sur ClusterControl, puis configurer la réplication en continu en quelques clics. Voyons comment pouvons-nous le faire.
Pour cette tâche, nous supposerons que votre cluster TimescaleDB est géré par ClusterControl. Accédez à ClusterControl -> Sélectionnez Cluster -> Actions de cluster -> Ajouter un esclave de réplication.
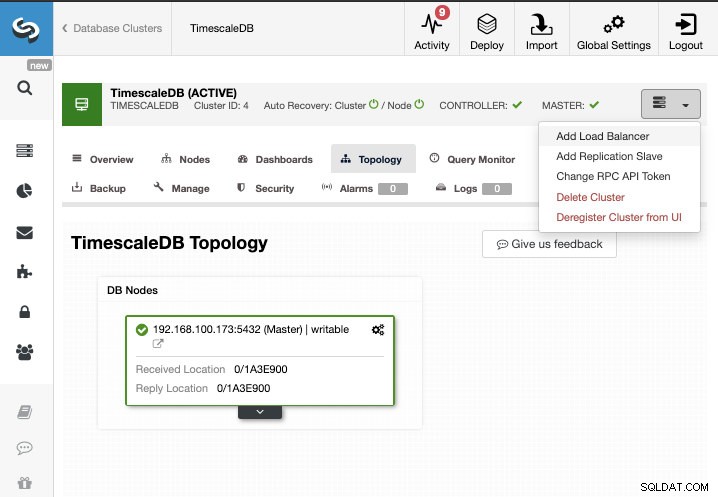
Nous pouvons créer un nouvel esclave de réplication (standby) ou nous pouvons en importer un existant. Dans ce cas, nous en créerons un nouveau.
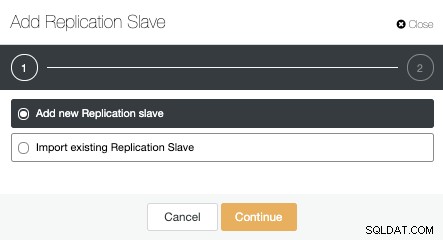
Maintenant, nous devons sélectionner le nœud maître, ajouter l'adresse IP ou le nom d'hôte du nouveau serveur de secours et le port de la base de données. Nous pouvons également spécifier si nous voulons que ClusterControl installe le logiciel et si nous voulons configurer la réplication de flux synchrone ou asynchrone.
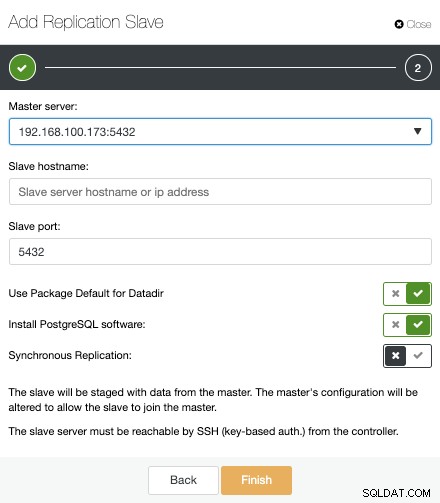
C'est tout. Nous n'avons qu'à attendre que ClusterControl termine le travail. Nous pouvons surveiller le statut à partir de la section Activité.
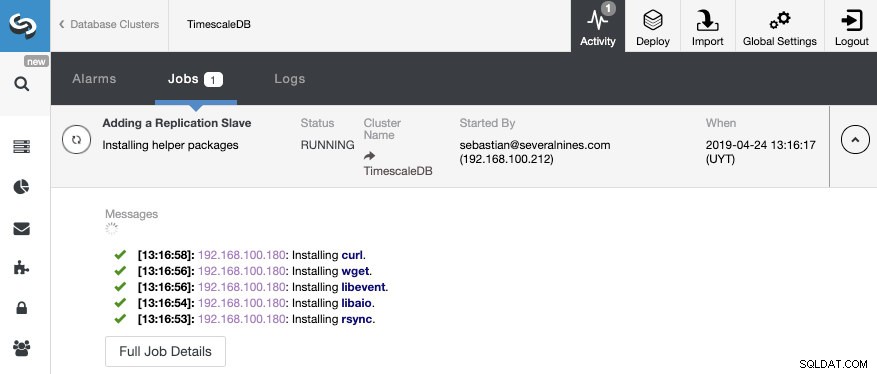
Une fois le travail terminé, nous devrions avoir configuré la réplication en continu et nous pouvons vérifier la nouvelle topologie dans la section Vue de la topologie de ClusterControl.
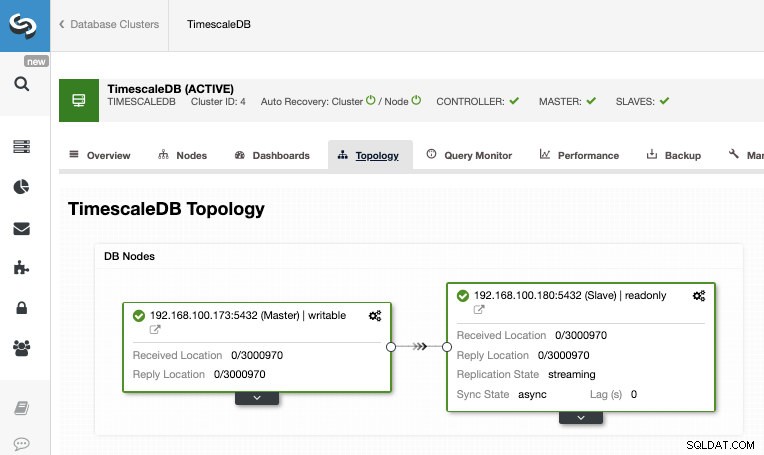
En utilisant ClusterControl, vous pouvez également effectuer plusieurs tâches de gestion sur votre TimescaleDB comme la sauvegarde, la surveillance et l'alerte, le basculement automatique, l'ajout de nœuds, l'ajout d'équilibreurs de charge, et bien plus encore.
Basculement
Comme nous avons pu le voir, TimescaleDB utilise un flux d'enregistrements de journal à écriture anticipée (WAL) pour maintenir la synchronisation des bases de données de secours. Si le serveur principal tombe en panne, le serveur de secours contient la quasi-totalité des données du serveur principal et peut rapidement devenir le nouveau serveur maître de la base de données. Cela peut être synchrone ou asynchrone et ne peut être effectué que pour l'ensemble du serveur de base de données.
Pour assurer efficacement une haute disponibilité, il ne suffit pas d'avoir une architecture maître-secours. Nous devons également activer une forme de basculement automatique, donc si quelque chose échoue, nous pouvons avoir le plus petit retard possible dans la reprise des fonctionnalités normales.
TimescaleDB n'inclut pas de mécanisme de basculement automatique pour identifier les défaillances sur la base de données maître et notifier à l'esclave de prendre possession, ce qui nécessitera un peu de travail du côté du DBA. Vous n'aurez également qu'un seul serveur en fonctionnement, donc la recréation de l'architecture maître-veille doit être faite, donc nous revenons à la même situation normale que nous avions avant le problème.
ClusterControl inclut une fonction de basculement automatique pour TimescaleDB afin d'améliorer le temps moyen de réparation (MTTR) dans votre environnement à haute disponibilité. En cas d'échec, ClusterControl promeut l'esclave le plus avancé en maître et reconfigure le ou les esclaves restants pour se connecter au nouveau maître. HAProxy peut également être déployé automatiquement afin d'offrir un point de terminaison de base de données unique aux applications, afin qu'elles ne soient pas impactées par un changement de serveur maître.
Limites
Ressources associées ClusterControl pour TimescaleDB Comment déployer facilement TimescaleDB Réplication en continu PostgreSQL – Analyse approfondieNous avons certaines limitations bien connues lors de l'utilisation de la réplication en continu :
- Nous ne pouvons pas répliquer dans une version ou une architecture différente
- Nous ne pouvons rien changer sur le serveur de secours
- Nous n'avons pas beaucoup de précision sur ce que nous pouvons répliquer
Donc, pour surmonter ces limitations, nous avons la fonction de réplication logique. Pour en savoir plus sur ce type de réplication, vous pouvez consulter le blog suivant.
Conclusion
Une topologie maître-veille a de nombreuses utilisations différentes comme l'analyse, la sauvegarde, la haute disponibilité, le basculement. Dans tous les cas, il est nécessaire de comprendre comment fonctionne la réplication en streaming sur TimescaleDB. Il est également utile d'avoir un système pour gérer tout le cluster et de vous donner la possibilité de créer cette topologie de manière simple. Dans ce blog, nous avons vu comment y parvenir en utilisant ClusterControl, et nous avons passé en revue quelques concepts de base sur la réplication en continu.