Auteur invité :Andy Mallon (@AMtwo)
Non, sérieusement. Qu'est-ce qu'un DTU ?
Lorsque vous déployez une application, l'une des premières questions qui se pose est « Combien cela coûtera-t-il ? La plupart d'entre nous sont passés par ce genre d'exercice pour dimensionner une installation SQL Server à un moment donné, mais que se passe-t-il si vous déployez dans le cloud ? Avec les déploiements Azure IaaS, peu de choses ont changé :vous construisez toujours un serveur basé sur le nombre de CPU, une certaine quantité de mémoire et la configuration du stockage pour vous donner suffisamment d'IOPS pour votre charge de travail. Cependant, lorsque vous passez au PaaS, Azure SQL Database est dimensionné avec différents niveaux de service, où les performances sont mesurées en DTU. Qu'est-ce qu'un DTU ?
Je sais ce qu'est un BTU. Peut-être que DTU signifie Database Thermal Unit ? Est-ce la quantité de puissance de traitement nécessaire pour augmenter la température du centre de données d'un degré ? Au lieu de deviner, vérifions la documentation et voyons ce que Microsoft a à dire :
Une [unité de transaction de base de données] est une mesure combinée du processeur, de la mémoire, des E/S de données et des E/S du journal des transactions dans un rapport déterminé par une charge de travail de référence OLTP conçue pour être typique des charges de travail OLTP réelles. Doubler les DTU en augmentant le niveau de performance d'une base de données équivaut à doubler l'ensemble des ressources disponibles pour cette base de données.OK, c'était ma deuxième supposition, mais qu'est-ce que la "mesure combinée" ? Comment puis-je traduire ce que je sais sur le dimensionnement d'un serveur en dimensionnement d'une base de données SQL Azure ? Malheureusement, il n'existe aucun moyen simple de traduire "2 cœurs de processeur et 4 Go de mémoire" en une mesure DTU.
N'y a-t-il pas un calculateur de DTU ?
Oui! Microsoft nous donne un calculateur de DTU pour estimer le niveau de service approprié d'Azure SQL Database. Pour l'utiliser, vous téléchargez et exécutez un script PowerShell (sql-perfmon.ps1) sur le serveur tout en exécutant une charge de travail dans SQL Server. Le script génère un fichier CSV qui contient quatre compteurs de performances :(1) % de temps processeur total, (2) lectures totales sur disque/seconde, (3) écritures totales sur disque par seconde et (4) octets de journal totaux vidés/seconde. Cette sortie CSV est ensuite téléchargée vers le calculateur DTU, qui estime quel niveau de service répondra le mieux à vos besoins. Les seules données que le calculateur DTU prend en plus du CSV sont le nombre de cœurs de processeur sur le serveur qui a généré le fichier. Le calculateur DTU est encore un peu une boîte noire - il n'est pas facile de mapper ce que nous savons de nos bases de données sur site dans Azure.
Je tiens à souligner que la définition d'un DTU est qu'il s'agit "d'une mesure mixte de CPU, mémoire , et les E/S de données et les E/S du journal des transactions…" Aucun des compteurs de performances utilisés par le calculateur DTU ne prend en compte la mémoire, mais il est clairement indiqué dans la définition comme faisant partie du calcul. Ce n'est pas nécessairement un problème, mais c'est la preuve que le calculateur de DTU ne sera pas parfait.
Je vais télécharger une charge synthétique dans le calculateur DTU et voir si je peux comprendre comment fonctionne cette boîte noire. En fait, je vais complètement fabriquer les CSV afin de pouvoir contrôler totalement les nombres de performances que nous chargeons dans le calculateur DTU. Passons en revue une métrique à la fois. Pour chaque métrique, nous téléchargeons 25 minutes (1 500 secondes, j'aime les chiffres ronds) de données fabriquées, et nous voyons comment ces données perfmon sont converties en DTU.
Processeur
Je vais créer un CSV qui simule un serveur à 16 cœurs, augmentant lentement l'utilisation du processeur jusqu'à ce qu'il soit fixé à 100 %. Étant donné que je vais simuler la montée en puissance sur un serveur à 16 cœurs, je vais créer mon fichier CSV pour augmenter 1/16e à la fois, en simulant essentiellement un cœur au maximum, puis un deuxième au maximum, puis le troisième, etc. Pendant tout ce temps, le CSV affichera zéro lecture, écriture et vidage du journal. Un serveur ne générerait jamais réellement une charge de travail comme celle-ci, mais c'est le point. J'isole complètement l'utilisation du processeur afin de pouvoir voir comment le processeur affecte les DTU.
Je vais créer un fichier CSV contenant une ligne par seconde, et toutes les 94 secondes, j'augmenterai le compteur de temps processeur total % d'environ 6 %. Les trois autres compteurs seront à zéro dans tous les cas. Maintenant, je télécharge ce fichier sur le calculateur DTU (et dis au calculateur DTU de prendre en compte 16 cœurs), et voici le résultat :
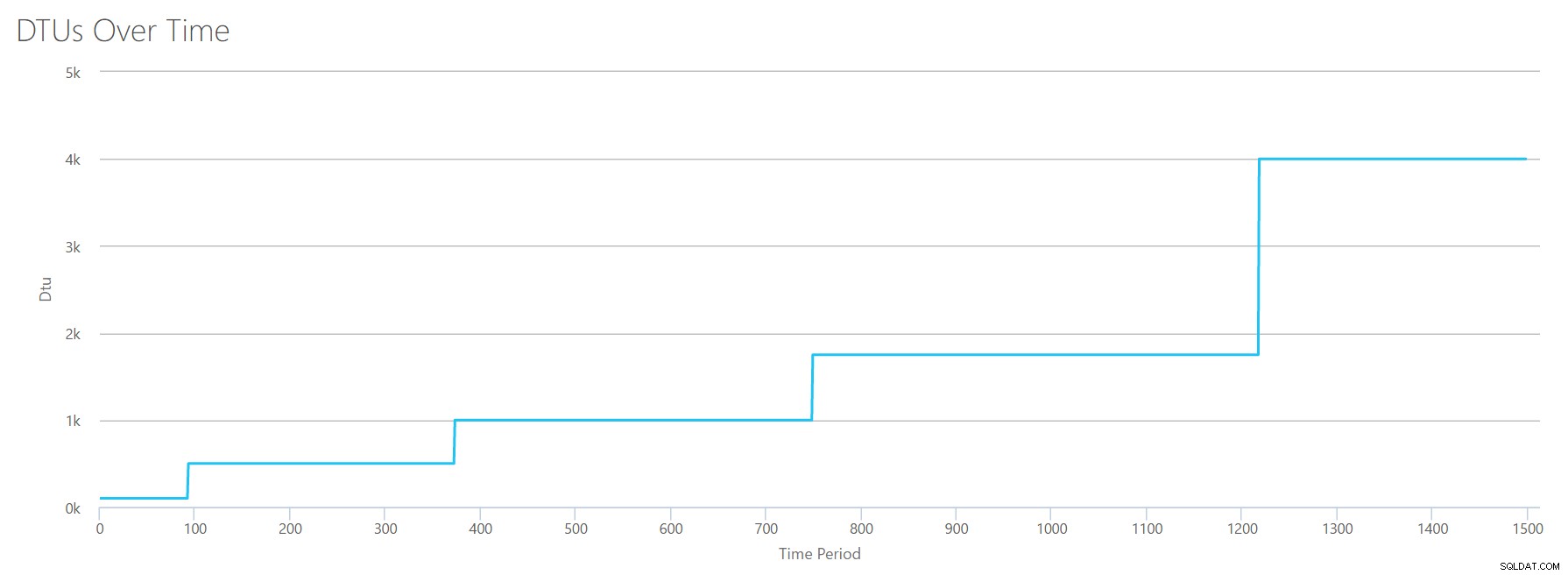
Attendre? N'ai-je pas augmenté l'utilisation du processeur en 16 étapes paires ? Ce graphique DTU ne montre que cinq étapes. Je dois avoir foiré. Non, mon CSV avait 16 étapes paires, mais cela (apparemment) ne se traduit pas uniformément en DTU. Du moins pas selon le DTU Calculator. Sur la base de notre test de CPU au maximum, notre mappage CPU-DTU-niveau de service ressemblerait à ceci :
| Nombre de cœurs | DTU | Niveau de service |
|---|---|---|
| 1 | 100 | Norme – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
L'examen de ces données nous apprend plusieurs choses :
- Un cœur de processeur utilisé à 100 % équivaut à 100 DTU.
- les DTU augmentent un peu linéairement à mesure que le CPU augmente, mais apparemment par à-coups.
- Les niveaux de service De base et Standard correspondent à moins d'un seul cœur de processeur.
- Tout serveur multicœur se traduirait par une certaine taille au sein du niveau de service Premium.
Lire
Cette fois, je vais utiliser la même méthodologie. Je vais générer un CSV avec des nombres croissants pour le compteur de lectures/seconde, avec les autres compteurs perfmon à zéro. J'augmenterai lentement le nombre au fil du temps. Cette fois, passons par tranches de 2000, toutes les 100 secondes, jusqu'à ce que nous atteignions 30000. Cela nous donne le même temps total de 25 minutes - cependant, cette fois, j'ai 15 pas au lieu de 16. (J'aime les chiffres ronds.)
Lorsque nous téléchargeons ce CSV dans le calculateur de DTU, cela nous donne ce graphique DTU :
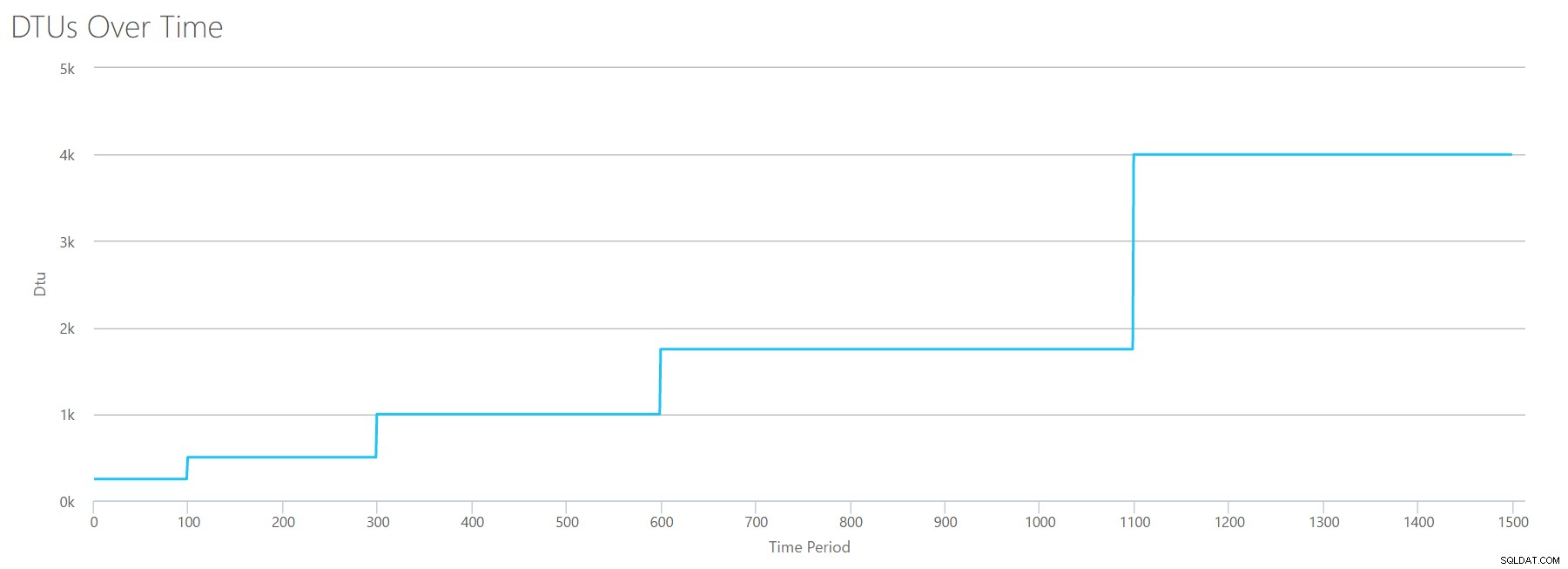
Attendez une seconde… cela ressemble assez au premier graphique. Encore une fois, il s'intensifie en 5 incréments inégaux, même si j'avais 15 étapes paires dans mon fichier. Regardons-le sous forme de tableau :
| Lectures/s | DTU | Niveau de service |
|---|---|---|
| 2 000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Encore une fois, nous constatons que les niveaux de base et standard sont dépassés assez rapidement (moins de 2 000 lectures/s), mais le niveau Premium est assez large, couvrant 2 000 à 30 000 lectures par seconde. Dans le tableau ci-dessus, les "Lectures/sec" pourraient probablement être considérées comme des "IOPS"… Ou, techniquement, juste "OPS" puisqu'il n'y a pas d'écritures pour constituer la partie "entrée" des IOPS.
Écrit
Si nous créons un CSV en utilisant la même formule que celle que nous avons utilisée pour les lectures et téléchargeons ce CSV dans le calculateur de DTU, nous obtiendrons un graphique identique au graphique des lectures :
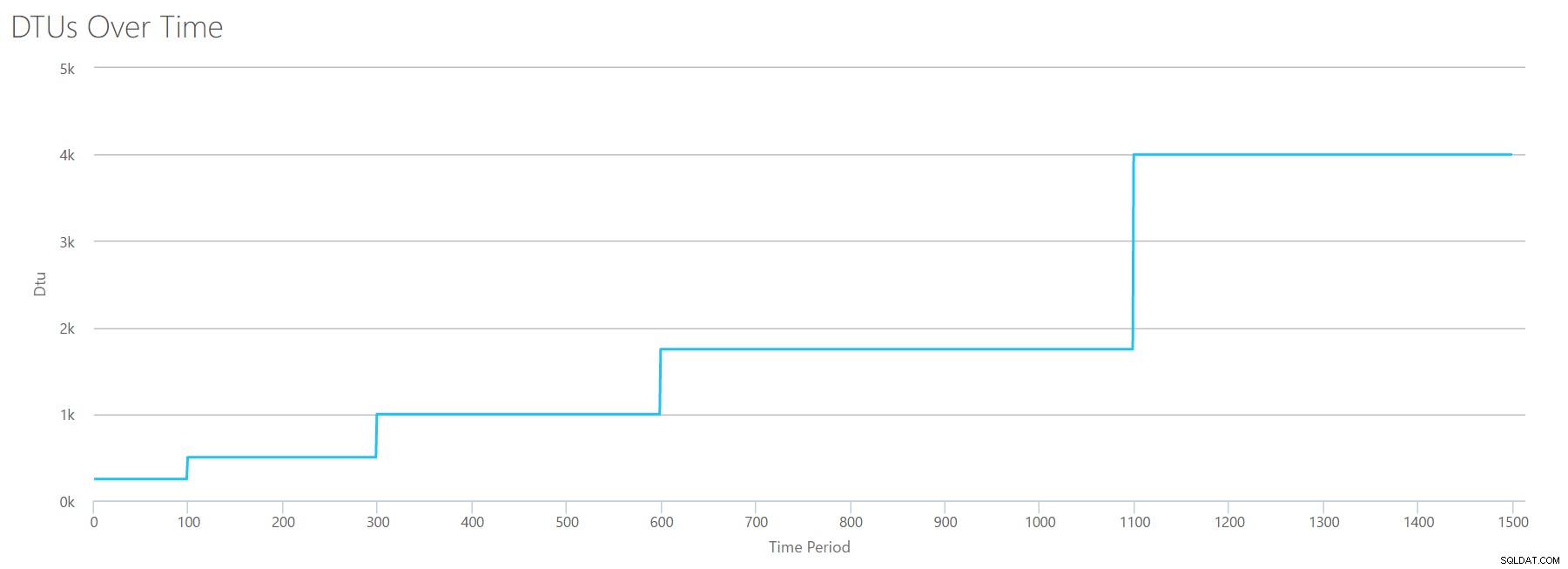
Les IOPS sont des IOPS, donc qu'il s'agisse d'une lecture ou d'une écriture, il semble que le calcul DTU le considère de manière égale. Tout ce que nous savons (ou pensons savoir) sur les lectures semble s'appliquer également aux écritures.
Octets de journal vidés
Nous en sommes au dernier compteur perfmon :octets de journal vidés par seconde. Il s'agit d'une autre mesure des E/S, mais spécifique au journal des transactions SQL Server. Au cas où vous ne l'auriez pas encore compris, je crée ces fichiers CSV afin que les valeurs élevées soient calculées comme une base de données Azure P15, puis je divise simplement la valeur pour la diviser en étapes égales. Cette fois, nous allons passer de 5 millions à 75 millions, par paliers de 5 millions. Comme nous l'avons fait sur tous les tests précédents, les autres compteurs de perfmon seront à zéro. Étant donné que ce compteur de performances est en octets par seconde et que nous mesurons en millions, nous pouvons penser à cela dans l'unité avec laquelle nous sommes le plus à l'aise :les mégaoctets par seconde.
Nous téléchargeons ce CSV dans le calculateur de DTU, et nous obtenons le graphique suivant :
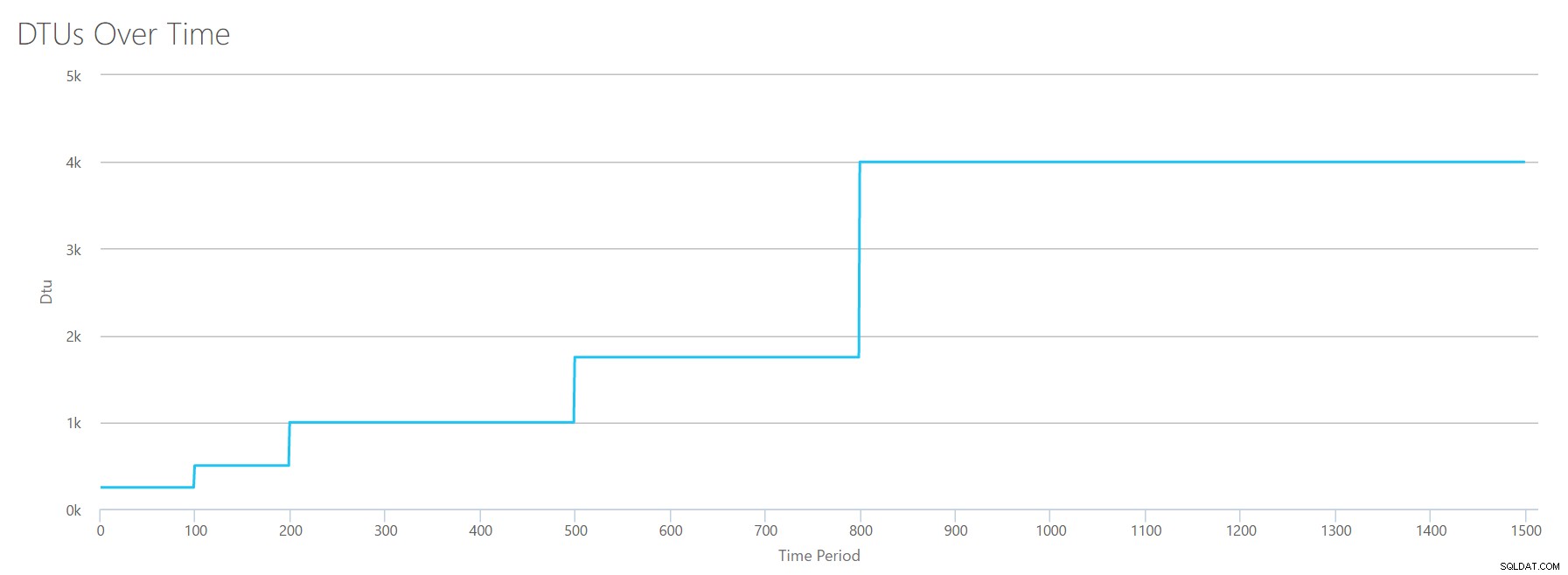
| Log Mégaoctets vidés/s | DTU | Niveau de service |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
La forme de ce graphique devient assez prévisible. Sauf que cette fois, nous franchissons les niveaux un peu plus rapidement, atteignant P15 après seulement 8 étapes (contre 11 pour IO et 12 pour CPU). Cela pourrait vous amener à penser :"Ce sera mon goulot d'étranglement le plus étroit !" mais je n'en serais pas si sûr. À quelle fréquence générez-vous 75 Mo de journal par seconde ? ? Cela représente 4,5 Go par minute . C'est beaucoup d'activité de base de données. Ma charge de travail synthétique n'est pas nécessairement une charge de travail réaliste.
Tout combiner
OK, maintenant que nous avons vu où certaines des limites supérieures sont isolées, je vais combiner les données et voir comment elles se comparent lorsque le processeur, les E/S et les E/S du journal des transactions se produisent tous en même temps, après tout , n'est-ce pas ainsi que les choses se passent ?
Pour construire ce CSV, j'ai simplement pris les valeurs existantes que nous avons utilisées pour chaque test individuel ci-dessus, et j'ai combiné ces valeurs en un seul CSV, ce qui donne ce joli graphique :
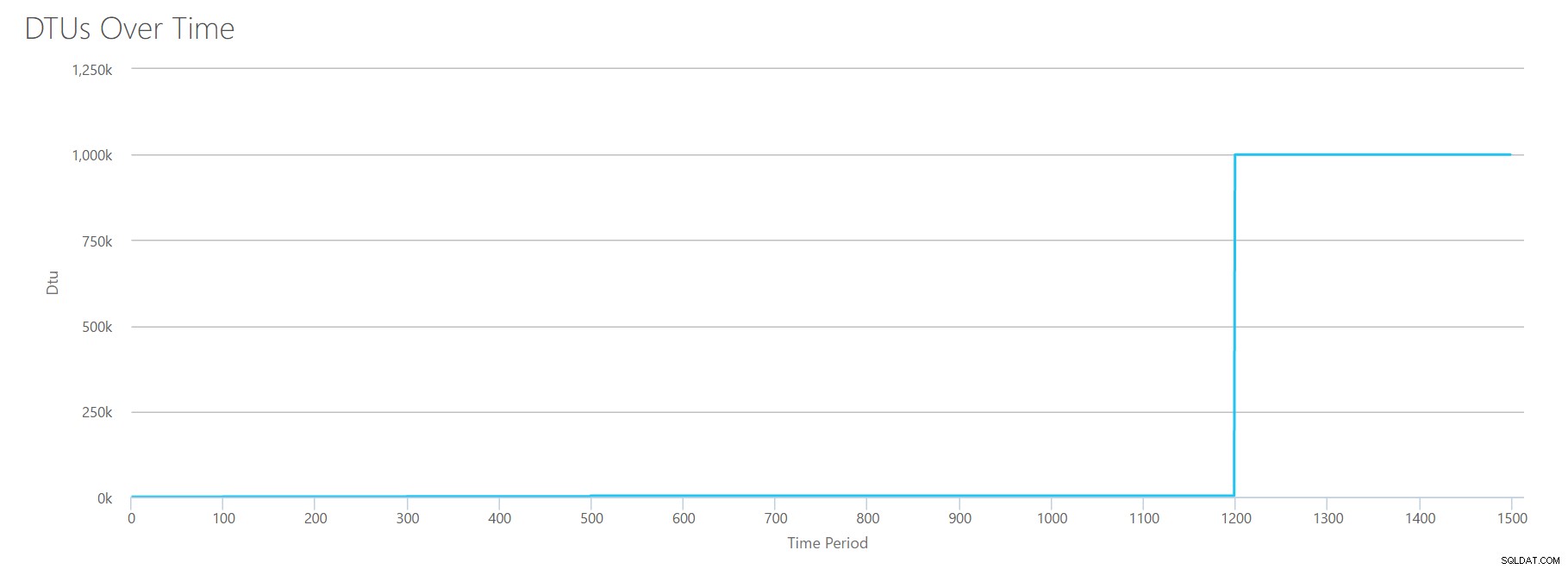
Il donne également le message :
En fonction de l'utilisation de votre base de données, votre charge de travail SQL Server est hors plage . À l'heure actuelle, aucun niveau de service/niveau de performance ne couvre votre utilisation.Si vous regardez l'axe des ordonnées, vous verrez que nous atteignons "1 000 000 k" (c'est-à-dire 1 million) de DTU à 1 200 secondes. Cela semble… euh… faux ? Si nous regardons les tests ci-dessus, la marque de 1200 secondes était lorsque les 4 mesures individuelles ont atteint la marque de 4000 DTU, niveau P15. Il est logique que nous soyons hors de portée, mais la forme du graphique n'a pas tout à fait de sens pour moi - je pense que le calculateur DTU vient de lever les mains et de dire:"Peu importe, Andy. C'est beaucoup. C'est trop C'est un milliard de DTU. Cette charge de travail ne convient pas à Azure SQL Database."
OK, alors que se passe-t-il avant la barre des 1200 secondes ? Réduisons le CSV et renvoyons-le à la calculatrice avec seulement les 1200 premières secondes. Les valeurs maximales pour chaque colonne sont :81 % de processeur (ou environ 13 cœurs à 100 %), 24 000 lectures/s, 24 000 écritures/s et 60 Mo de vidage de journal/s.
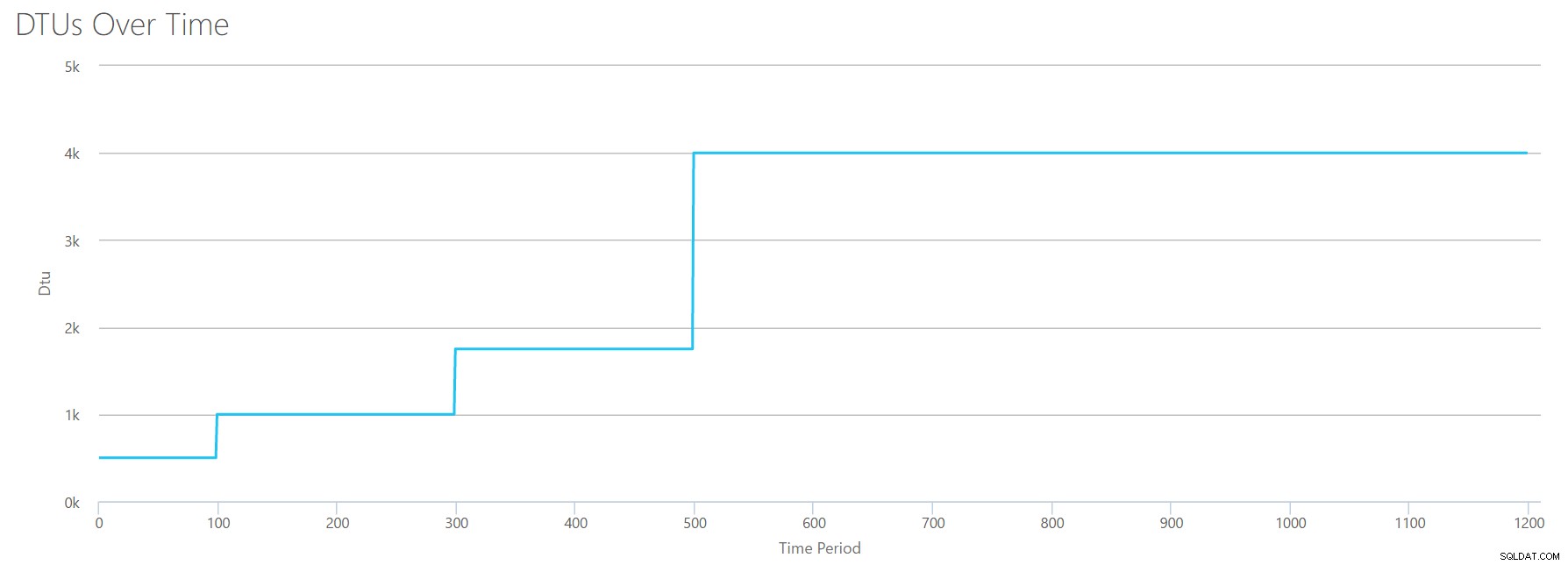
Bonjour, mon vieil ami… Cette forme familière est de retour. Voici un résumé des données du CSV et des estimations du calculateur de DTU pour l'utilisation totale de DTU et le niveau de service.
| Nombre de cœurs | Lectures/s | Écritures/s | Log Mégaoctets vidés/s | DTU | Niveau de service |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Maintenant, regardons comment les calculs DTU individuels (lorsque nous les avons évalués isolément) se comparent aux calculs DTU de cette vérification la plus récente :
| DTU du processeur | Lire les DTU | Écrire des DTU | Log flush DTU | Somme totale des DTU | Estimation du calculateur de DTU | Niveau de service |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Vous remarquerez que le calcul des DTU n'est pas aussi simple que d'additionner vos DTU distinctes. Comme la définition que j'ai citée au début l'indique, il s'agit d'une "mesure mixte" de ces mesures distinctes. La formule utilisée pour "mélanger" est compliquée, et nous n'avons pas réellement cette formule. Ce que nous pouvons voir, c'est que les estimations du calculateur de DTU sont inférieures que la somme des calculs DTU séparés.
Mappage des DTU sur du matériel traditionnel
Prenons les données du calculateur DTU et essayons de faire des suppositions sur la manière dont le matériel traditionnel pourrait être mappé à certains niveaux Azure SQL Database.
Tout d'abord, supposons que "lectures/s" et "écritures/s" se traduisent directement en IOPS, sans traduction nécessaire. Deuxièmement, supposons que l'ajout de ces deux compteurs nous donnera notre total d'IOPS. Troisièmement, admettons que nous n'avons aucune idée de ce qu'est l'utilisation de la mémoire et que nous n'avons aucun moyen de tirer des conclusions à ce sujet.
Pendant que j'estime les spécifications matérielles, je choisirai également une taille de machine virtuelle Azure possible qui conviendra à chaque configuration matérielle. Il existe de nombreuses tailles de machines virtuelles Azure similaires, chacune optimisée pour différentes métriques de performances, mais j'ai décidé de limiter mes choix aux séries A et DSv2.
| Nombre de cœurs | IOPS | Mémoire | DTU | Niveau de service | Taille de machine virtuelle Azure comparable |
|---|---|---|---|---|---|
| 1 cœur, 5 % d'utilisation | 10 | ??? | 5 | De base | Standard_A0, à peine utilisé |
| <1 cœur | 150 | ??? | 100 | Norme S0-S3 | Standard_A0, pas pleinement utilisé |
| 1 cœur | jusqu'à 4000 | ??? | 500 | Premium – P4 | Norme_DS1_v2 |
| 2-3 cœurs | jusqu'à 12 000 | ??? | 1000 | Premium – P6 | Norme_DS3_v2 |
| 4-5 cœurs | jusqu'à 20 000 | ??? | 1750 | Premium – P11 | Norme_DS4_v2 |
| 6-13 | jusqu'à 48 000 | ??? | 4000 | Premium – P15 | Norme_DS5_v2 |
Le niveau de base est incroyablement limité. C'est bon pour une utilisation occasionnelle/occasionnelle, et c'est un moyen peu coûteux de "garer" votre base de données lorsque vous ne l'utilisez pas. Mais si vous exécutez une application réelle, le niveau de base ne fonctionnera pas pour vous.
Le niveau standard est également assez limité, mais pour les petites applications, il est capable de répondre à vos besoins. Si vous avez un serveur à 2 cœurs exécutant une poignée de bases de données, ces bases de données individuellement peuvent s'intégrer au niveau Standard. De même, si vous avez un serveur avec une seule base de données, exécutant 1 cœur de processeur à 100 % (ou 2 cœurs fonctionnant à 50 %), c'est probablement juste assez de puissance pour faire basculer la balance vers le niveau de service Premium-P1.
Si vous utilisiez un serveur multicœur sur site (ou IaaS), vous chercheriez dans le niveau de service Premium sur Azure SQL Database. Il s'agit simplement de déterminer la puissance CPU et E/S dont vous avez besoin pour votre charge de travail. Votre serveur à 2 cœurs de 4 Go vous amène probablement quelque part autour d'une base de données SQL Azure P6. Dans une charge de travail CPU pure (avec zéro E/S), une base de données P15 peut gérer 16 cœurs de traitement, mais une fois que vous ajoutez des E/S au mélange, tout ce qui dépasse environ 12 cœurs ne rentre pas dans Azure SQL Database.
La prochaine fois, je prendrai des charges de travail réelles et comparerai les performances entre les niveaux de service. Les estimations du calculateur de DTU seront-elles exactes ? Nous le découvrirons.
À propos de l'auteur
 Andy Mallon est un administrateur de base de données SQL Server et un MVP de la plate-forme de données Microsoft qui a géré des bases de données dans les domaines de la santé, de la finance, de l'e -secteurs du commerce et à but non lucratif. Depuis 2003, Andy prend en charge des environnements OLTP à haut volume et hautement disponibles avec des besoins de performances exigeants. Andy est le fondateur de BostonSQL, co-organisateur de SQLSaturday Boston et blogue sur am2.co.
Andy Mallon est un administrateur de base de données SQL Server et un MVP de la plate-forme de données Microsoft qui a géré des bases de données dans les domaines de la santé, de la finance, de l'e -secteurs du commerce et à but non lucratif. Depuis 2003, Andy prend en charge des environnements OLTP à haut volume et hautement disponibles avec des besoins de performances exigeants. Andy est le fondateur de BostonSQL, co-organisateur de SQLSaturday Boston et blogue sur am2.co.