L'exécution de bases de données sur une infrastructure cloud devient de plus en plus populaire de nos jours. Bien qu'une machine virtuelle cloud ne soit pas aussi fiable qu'un serveur d'entreprise, les principaux fournisseurs de cloud offrent une variété d'outils pour augmenter la disponibilité des services. Dans cet article de blog, nous vous montrerons comment concevoir votre base de données MySQL ou MariaDB pour une haute disponibilité, dans le cloud. Nous examinerons spécifiquement Amazon Web Services et Google Cloud Platform, mais la plupart des conseils peuvent également être utilisés avec d'autres fournisseurs de cloud.
AWS et Google proposent tous deux des services de base de données sur leurs clouds, et ces services peuvent être configurés pour une haute disponibilité. Il est possible d'avoir des copies dans différentes zones de disponibilité (ou zones dans GCP), afin d'augmenter vos chances de survivre à une panne partielle des services dans une région. Bien qu'un service hébergé soit un moyen très pratique d'exécuter une base de données, notez que le service est conçu pour se comporter d'une manière spécifique et qu'il peut ou non répondre à vos besoins. Ainsi, par exemple, AWS RDS pour MySQL a une liste assez limitée d'options en matière de gestion du basculement. Les déploiements multi-AZ sont livrés avec un temps de basculement de 60 à 120 secondes selon la documentation. En fait, étant donné que l'instance MySQL "fantôme" doit démarrer à partir d'un ensemble de données "corrompu", cela peut prendre encore plus de temps car plus de travail pourrait être nécessaire pour appliquer ou annuler les transactions à partir des journaux redo InnoDB. Il existe une option pour promouvoir un esclave en maître, mais ce n'est pas faisable car vous ne pouvez pas réasservir les esclaves existants sur le nouveau maître. Dans le cas d'un service managé, il est aussi intrinsèquement plus complexe et plus difficile de tracer les problèmes de performance. Plus d'informations sur RDS pour MySQL et ses limites dans cet article de blog.
D'autre part, si vous décidez de gérer les bases de données, vous êtes dans un autre monde de possibilités. Un certain nombre de choses que vous pouvez faire sur du métal nu sont également possibles sur des instances EC2 ou Compute Engine. Vous n'avez pas les frais généraux liés à la gestion du matériel sous-jacent, tout en gardant le contrôle sur l'architecture du système. Il existe deux options principales lors de la conception de la disponibilité de MySQL :la réplication MySQL et Galera Cluster. Discutons-en.
Réplication MySQL
La réplication MySQL est un moyen courant de faire évoluer MySQL avec plusieurs copies des données. Asynchrone ou semi-synchrone, il permet de propager les modifications exécutées sur un seul écrivain, le maître, vers des répliques/esclaves - dont chacune contiendrait l'ensemble de données complet et peut être promue pour devenir le nouveau maître. La réplication peut également être utilisée pour mettre à l'échelle les lectures, en dirigeant le trafic de lecture vers les répliques et en déchargeant ainsi le maître. Le principal avantage de la réplication est sa facilité d'utilisation - elle est si largement connue et populaire (elle est également facile à configurer) qu'il existe de nombreuses ressources et outils pour vous aider à la gérer et à la configurer. Notre propre ClusterControl en fait partie :vous pouvez l'utiliser pour déployer facilement une configuration de réplication MySQL avec des équilibreurs de charge intégrés, gérer les changements de topologie, le basculement/la récupération, etc.
L'un des principaux problèmes de la réplication MySQL est qu'elle n'est pas conçue pour gérer les divisions du réseau ou les défaillances du maître. Si un maître tombe en panne, vous devez promouvoir l'une des répliques. Il s'agit d'un processus manuel, bien qu'il puisse être automatisé avec des outils externes (par exemple, ClusterControl). Il n'y a pas non plus de mécanisme de quorum et il n'y a pas de prise en charge de la clôture des instances maîtres défaillantes dans la réplication MySQL. Malheureusement, cela peut entraîner de graves problèmes dans les environnements distribués :si vous avez promu un nouveau maître alors que l'ancien revient en ligne, vous risquez d'écrire sur deux nœuds, de créer une dérive des données et de causer de graves problèmes de cohérence des données.
Nous examinerons quelques exemples plus loin dans cet article, qui vous montreront comment détecter les divisions du réseau et implémenter STONITH ou un autre mécanisme de clôture pour votre configuration de réplication MySQL.
Pôle Galera
Nous avons vu dans la section précédente que la réplication MySQL manque de prise en charge de la clôture et du quorum - c'est là que Galera Cluster brille. Il a un support de quorum intégré, il a également un mécanisme de clôture qui empêche les nœuds partitionnés d'accepter les écritures. Cela rend Galera Cluster plus adapté que la réplication dans les configurations multi-centres de données. Galera Cluster prend également en charge plusieurs écrivains et est capable de résoudre les conflits d'écriture. Vous n'êtes donc pas limité à un seul écrivain dans une configuration multi-centre de données, il est possible d'avoir un écrivain dans chaque centre de données, ce qui réduit la latence entre votre application et le niveau base de données. Cela n'accélère pas les écritures car chaque écriture doit encore être envoyée à chaque nœud Galera pour certification, mais c'est toujours plus facile que d'envoyer des écritures de tous les serveurs d'applications sur le WAN à un seul maître distant.
Aussi bon que soit Galera, ce n'est pas toujours le meilleur choix pour toutes les charges de travail. Galera ne remplace pas MySQL/InnoDB. Il partage des fonctionnalités communes avec MySQL "normal" - il utilise InnoDB comme moteur de stockage, il contient l'intégralité de l'ensemble de données sur chaque nœud, ce qui rend les JOIN possibles. Pourtant, certaines des caractéristiques de performance de Galera (comme les performances des écritures qui sont affectées par la latence du réseau) diffèrent de ce que vous attendez des configurations de réplication. La maintenance est également différente :la gestion des changements de schéma fonctionne légèrement différemment. Certaines conceptions de schéma ne sont pas optimales :si vous avez des points chauds dans vos tables, comme des compteurs fréquemment mis à jour, cela peut entraîner des problèmes de performances. Il existe également une différence dans les meilleures pratiques liées au traitement par lots :au lieu d'exécuter des requêtes dans des transactions volumineuses, vous souhaitez que vos transactions soient petites.
Niveau proxy
Il est très difficile et fastidieux de créer une configuration hautement disponible sans proxy. Bien sûr, vous pouvez écrire du code dans votre application pour garder une trace des instances de base de données, mettre sur liste noire celles qui ne sont pas saines, garder une trace du ou des maîtres inscriptibles, etc. Mais c'est beaucoup plus complexe que de simplement envoyer du trafic vers un seul point de terminaison - c'est là qu'un proxy entre en jeu. ClusterControl vous permet de déployer ProxySQL, HAProxy et MaxScale. Nous donnerons quelques exemples d'utilisation de ProxySQL, car cela nous donne une bonne flexibilité dans le contrôle du trafic de la base de données.
ProxySQL peut être déployé de plusieurs manières. Pour commencer, il peut être déployé sur des hôtes séparés et Keepalived peut être utilisé pour fournir une adresse IP virtuelle. L'adresse IP virtuelle sera déplacée en cas de défaillance de l'une des instances ProxySQL. Dans le cloud, cette configuration peut être problématique car l'ajout d'une adresse IP à l'interface n'est généralement pas suffisant. Vous devrez modifier la configuration et les scripts de Keepalived pour qu'ils fonctionnent avec une adresse IP élastique (ou statique, quelle que soit la manière dont votre fournisseur de cloud l'appelle). Ensuite, on utiliserait l'API cloud ou la CLI pour déplacer cette adresse IP vers un autre hôte. Pour cette raison, nous suggérons de colocaliser ProxySQL avec l'application. Chaque serveur d'application serait configuré pour se connecter au ProxySQL local, à l'aide de sockets Unix. Comme ProxySQL utilise un processus ange, les plantages de ProxySQL peuvent être détectés/redémarrés en une seconde. En cas de panne matérielle, ce serveur d'application particulier tombera en panne avec ProxySQL. Les serveurs d'applications restants peuvent toujours accéder à leurs instances ProxySQL locales respectives. Cette configuration particulière a des fonctionnalités supplémentaires. Sécurité - ProxySQL, à partir de la version 1.4.8, ne prend pas en charge SSL côté client. Il peut uniquement configurer une connexion SSL entre ProxySQL et le backend. Colocaliser ProxySQL sur l'hôte de l'application et utiliser des sockets Unix est une bonne solution de contournement. ProxySQL a également la capacité de mettre en cache les requêtes et si vous allez utiliser cette fonctionnalité, il est logique de la garder aussi près que possible de l'application pour réduire la latence. Nous suggérons d'utiliser ce modèle pour déployer ProxySQL.
Configurations typiques
Examinons des exemples de configurations hautement disponibles.
Centre de données unique, réplication MySQL
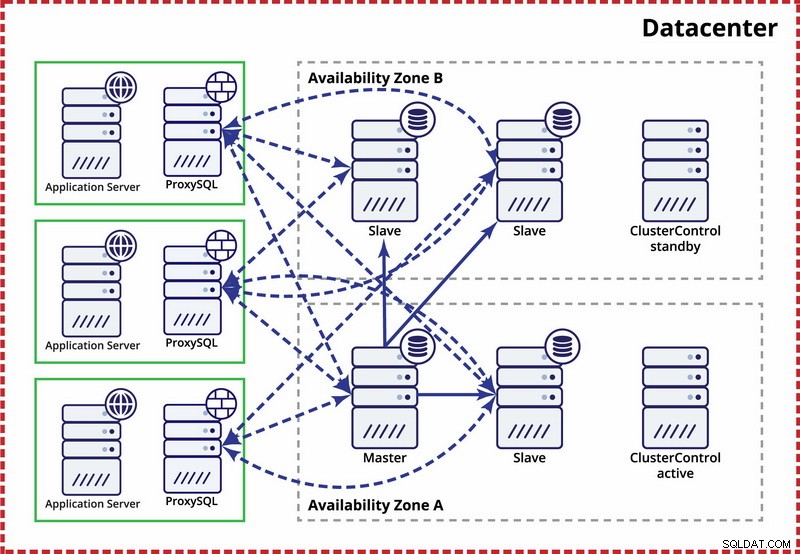
L'hypothèse ici est qu'il existe deux zones distinctes dans le centre de données. Chaque zone dispose d'une alimentation, d'un réseau et d'une connectivité redondants et séparés pour réduire le risque de défaillance simultanée de deux zones. Il est possible de mettre en place une topologie de réplication couvrant les deux zones.
Ici, nous utilisons ClusterControl pour gérer le basculement. Pour résoudre le scénario de split-brain entre les zones de disponibilité, nous colocalisons le ClusterControl actif avec le maître. Nous mettons également sur liste noire les esclaves dans l'autre zone de disponibilité pour nous assurer que le basculement automatique n'entraînera pas la disponibilité de deux maîtres.
Centres de données multiples, réplication MySQL
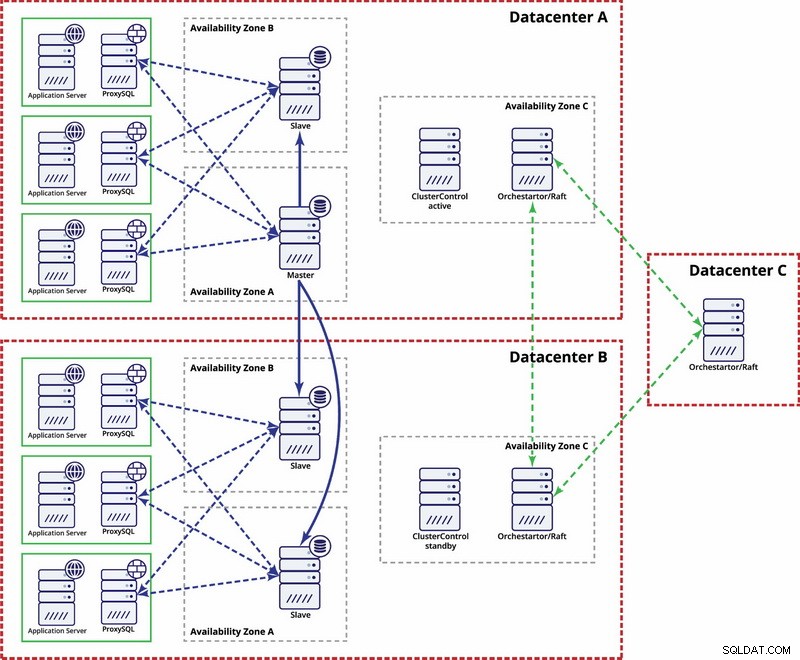
Dans cet exemple, nous utilisons trois centres de données et Orchestrator/Raft pour le calcul du quorum. Vous devrez peut-être écrire vos propres scripts pour implémenter STONITH si le maître se trouve dans le segment partitionné de l'infrastructure. ClusterControl est utilisé pour les fonctions de récupération et de gestion des nœuds.
Plusieurs centres de données, cluster Galera
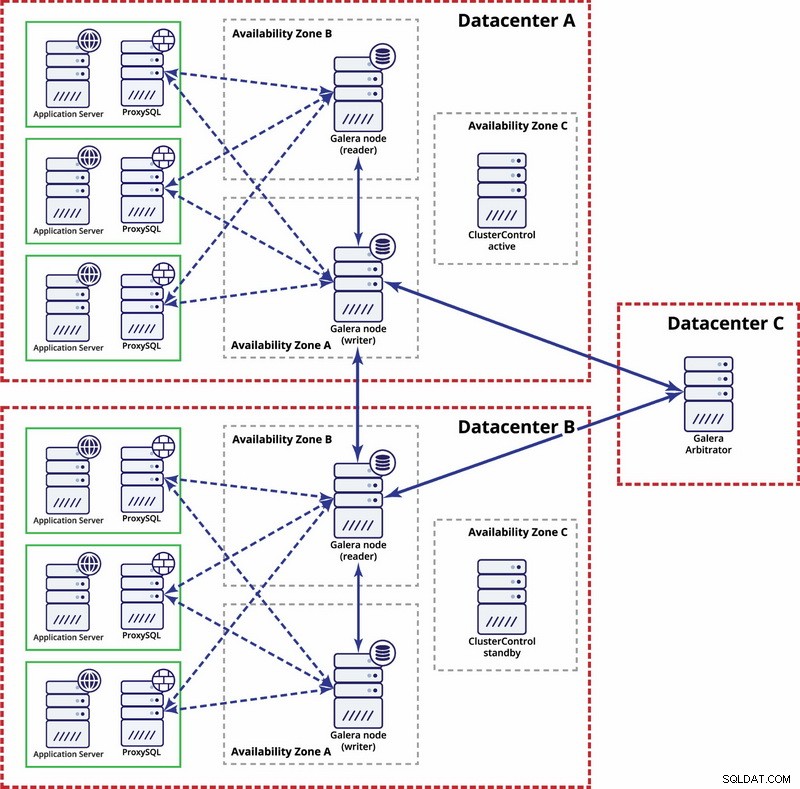
Dans ce cas, nous utilisons trois centres de données avec un arbitre Galera dans le troisième - cela permet de gérer l'échec de l'ensemble du centre de données et réduit le risque de partitionnement du réseau car le troisième centre de données peut être utilisé comme relais.
Pour en savoir plus, consultez le livre blanc "Comment concevoir des environnements de bases de données open source hautement disponibles" et regardez la rediffusion du webinaire "Concevoir des bases de données open source pour une haute disponibilité".