Un système de gestion de base de données est le coffre-fort de l'information. Nous essaierons de concevoir le système de gestion de base de données de sorte que la base de données reste bien gérée et fournisse les objectifs.
Dans cet article, nous allons discuter de la conception et de l'administration de systèmes de bases de données de grande taille. Nous utiliserons plusieurs constitutions qui incluront les technologies de base de données, le stockage, la distribution de données, les actifs de serveur, le modèle d'architecture et quelques autres.
De préférence, nous devrions rechercher une base de données de grande taille dans le domaine des télécommunications, des plateformes de commerce électronique, du domaine des assurances, du système bancaire, de la santé, du système énergétique, etc. Nous devons garder quelques paramètres à l'esprit avant de choisir la bonne technologie de base de données. c'est-à-dire le trafic, le TPS (transactions par seconde), le stockage estimé par jour, HA et DR.
Concevoir une base de données de grande taille
Lors de la construction de notre base de données, nous devons prêter attention à plusieurs paramètres car il est souvent très problématique de changer la base de données par un substitut. Considérons-les maintenant.
Technologie de base de données
La technologie des bases de données est le facteur principal. Si vous choisissez le bon système de gestion de base de données, cela aidera votre entreprise à fonctionner efficacement et sans effort.
Il existe différentes technologies de base de données avec de nombreuses fonctionnalités. Cependant, lorsque vous travaillez avec des technologies de base de données open source, vous n'aurez peut-être pas accès à certaines fonctionnalités explicites des solutions prédéfinies. Les technologies de base de données d'entreprise telles que Microsoft SQL Server, Oracle, etc. les fourniraient.
De nombreuses technologies de base de données d'entreprise implémentent HA (haute disponibilité), DR (reprise après sinistre), mise en miroir, réplication de données, réplica en lecture secondaire et des solutions d'entreprise configurables considérablement plus pratiques et prêtes à l'emploi. Ils peuvent être présents ou non dans les bases de données open source.
Il y a beaucoup de raisons. Par exemple, nous constatons parfois que l'architecture existante est perturbée parce que les facteurs mentionnés ci-dessus ne fonctionnent pas comme nous en avons besoin.
Stockage
Le stockage a un impact considérable sur les performances de la solution métier. Les solutions professionnelles nécessitent un stockage de premier ordre ou un SSD avec une certaine quantité d'IOPS. Cependant, en est-il ainsi ? Sur site ou dans le cloud, la taille et le type de stockage déterminent les coûts d'infrastructure.
Tout en considérant les performances de stockage, nous devons prêter attention au type de données et au comportement du traitement des données. Nous devons opter pour une sélection de stockage en fonction des données de l'utilisateur et de leur traitement. Si l'utilisateur va utiliser plusieurs bases de données, nous devons fournir le choix de stockage sur le SAN pour différentes bases de données pour les types de données et le comportement de traitement des données.
L'ingénieur base de données fournira une meilleure rétrospection sur les différentes bases de données nécessaires au calcul des IOPS si les utilisateurs n'ont pas du tout besoin de stockage premium.
Répartition des données
La plupart des technologies de bases de données récentes (SQL ou NoSQL) proposent des fonctionnalités de partitionnement ou de sharding.
- La partition redistribue les données dans le système de fichiers en fonction de la clé de partition.
- Le partage répartit les informations sur les nœuds de la base de données et les données sont stockées sur la même machine ou sur une machine différente.
Fondamentalement, chaque service de base de données ou table de base de données ne nécessitera pas les fonctionnalités de partitionnement/partage des données. Ils ne nécessitent d'être appliqués que sur des bases de données contenant des objets de plus grande taille. Cela améliorera les performances.
Actifs du serveur
Différentes machines nécessitent différents types et tailles de mémoire et de CPU. Vous devez tenir compte des actifs au niveau matériel, tels que la mémoire, le processeur, etc. Par exemple, une machine qui doit gérer des bases de données plus volumineuses ou plusieurs bases de données aura besoin de plus de mémoire et de processeurs. Par conséquent, la qualité de la mémoire et du processeur est importante. Il va gérer différents types de processeurs disponibles sur le marché avec différents caches CPU.
Souvent, nous rencontrons des problèmes dont nous ne sommes peut-être pas conscients. Nous n'avons pas prêté attention à l'utilisation et au rôle du cache CPU du matériel. Mais c'est crucial pour sélectionner et répondre aux exigences matérielles avec des systèmes de base de données plus volumineux.
Modèle d'architecture
Dans la conception de bases de données, le pattern Architecture joue toujours un rôle exemplaire. Auparavant, les systèmes de bases de données étaient conçus de manière extrêmement monolithique. Maintenant, nous utilisons des micro-services ou hybrides (monolithique + micro).
Les performances, l'évolutivité et l'absence de temps d'arrêt dépendent beaucoup du modèle d'architecture et de la conception de la base de données. Chaque application pourrait avoir une base de données distincte et toutes les bases de données pourraient être faiblement couplées les unes aux autres. En cas de panne d'une application ou d'une base de données, une autre partie du produit ne sera pas interrompue. Tous les micro-services seraient indépendants et faiblement couplés.
Microservice
Le diagramme ci-dessous explique comment toutes les applications se déploient et communiquent à l'aide de leurs bases de données, qui sont faiblement couplées en même temps. Nous pouvons manipuler les données avec T-SQL. Les informations seront recueillies ou accumulées par diverses applications, et le client pourra accéder aux données. Reportez-vous au diagramme avec le nombre d'applications mises à l'échelle et sa base de données intégrée.
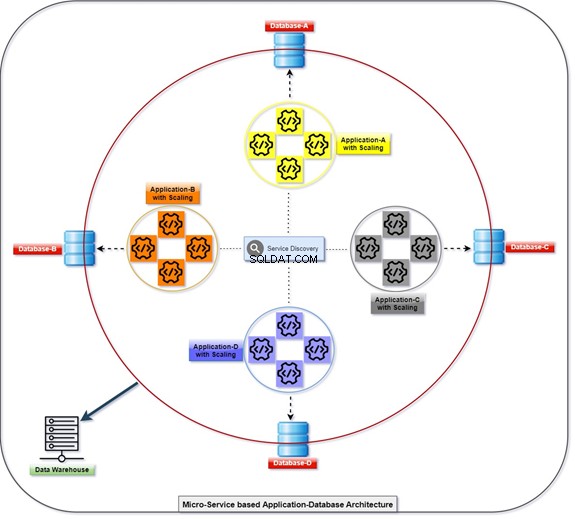
Monolithique
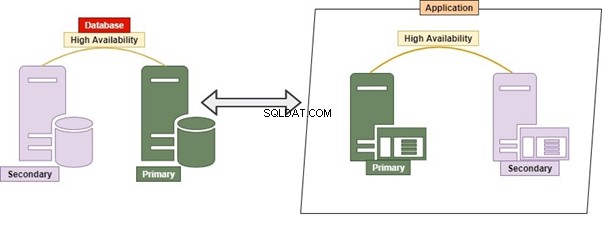
Quel SGBDR devrions-nous utiliser ? Il peut s'agir d'Oracle, de Microsoft SQL Server, de Postgres, de MySQL, de MongoDB ou de toute autre base de données. La manière conventionnelle de traiter toutes les tables ou objets gérés dans une ou plusieurs bases de données sur un seul serveur est connue sous le nom de monolithique.
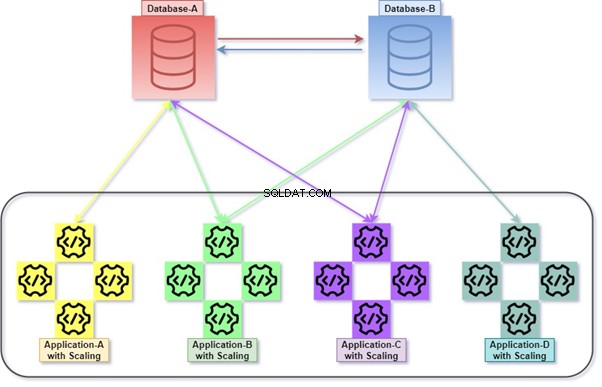
Hybride
Hybride est une permutation de Monolithic et Micro Service. C'est une pratique assez courante, car elle autorise de nombreuses applications, de nombreuses bases de données et des serveurs de bases de données. De nombreuses bases de données et serveurs de bases de données pourraient être étroitement couplés les uns aux autres.
Par exemple, interroger avec des JOIN entre des tables appartenant à deux bases de données ou plus dans le même serveur de base de données ou différentes. Requête à distance utilisée pour la récupération/la manipulation de données avec un autre serveur de base de données.
Tout tourne autour de l'architecture SQL Server. Cependant, nous parlons de la manipulation de données entre différentes tables au sein de la même base de données ou de différentes bases de données pouvant résider sur le même serveur ou sur différents serveurs.
Que ce soit dans une architecture hybride ou monolithique, nous utilisons des JOIN entre différentes tables au sein d'une même base de données ou de bases de données différentes. C'est assez complexe lorsque nous suivons les normes de base des micro-services car la distribution des tables peut se faire entre les services de base de données (Dbas).
Dans le cadre des technologies de base de données d'entreprise telles que Microsoft SQL Server, Oracle, etc., l'utilisateur peut interroger les tables de la base de données distribuée à l'aide de Linked Server Joins. Mais il n'est pas disponible dans toutes les technologies de bases de données open source. Il s'agit de l'approche à couplage serré qui peut ne pas fonctionner lorsque le service de base de données distant n'est pas disponible.
Maintenant, discutons de le rendre lâche. Pourquoi avons-nous besoin de manipulation de données entre des bases de données distantes ?
Pourquoi avons-nous besoin de manipulation de données entre des bases de données distantes ?
Les utilisateurs auront besoin que les données soient extraites de plusieurs services de base de données lorsque le système est conçu avec l'aide de services micro ou hybrides. L'ensemble du processus est vu depuis le backend qui peut gérer les quantités de données manipulées par l'application.
Lorsque nous examinons l'interrogation de bases de données croisées en temps réel, nous joignons toujours les tables d'entités principales, pas les tables de métadonnées. Les tables maîtres ne seront pas plus grandes que les tables de métadonnées. À des fins de reporting, nous utilisons toujours l'entrepôt de données pour rassembler toutes les informations. Mais ce n'est pas facile à gérer et à maintenir pour chaque produit. Si nous concevons la solution d'entreprise, nous pouvons nous permettre l'entrepôt. Mais nous ne pouvons pas nous le permettre pour les produits de petite ou moyenne taille.
Par exemple, nous avons besoin d'un rapport avec les données de plusieurs tables résidant dans différentes bases de données. Ce n'est pas une tâche facile à réaliser, car il rassemble les données à l'aide de différents microservices et les fusionne pour produire le rapport. Par conséquent, les données nécessaires doivent être synchronisées.
Que pouvons-nous utiliser comme solution standard effectuer une synchronisation de données de table à couplage lâche entre deux bases de données ?
La réplication de table doit être utilisée pour une synchronisation simple des données entre plusieurs bases de données. L'exemple est la réplication de transaction pour la synchronisation de données Simplex et la réplication de fusion pour la synchronisation de données Duplex fournies par SQL Server.
Il existe quelques solutions tierces et open source payantes qui peuvent synchroniser les données entre plusieurs bases de données. Même les solutions à couplage lâche à l'aide de files d'attente de messages comme la réplication des transactions SQL Server peuvent être développées par les utilisateurs eux-mêmes.
Conclusion
Les DBA conçoivent les bases de données à leur manière. Lors de l'architecture de la base de données et du choix du système de gestion de base de données, ils doivent garder à l'esprit de nombreux aspects. Nous avons présenté les facteurs les plus essentiels pour la conception de la base de données, en particulier pour les bases de données de plus grande taille. Restez à l'écoute pour les prochains matériaux !