Le modèle relationnel de gestion des données a été développé pour la première fois par le Dr Edgar F. Codd en 1969. Les systèmes modernes de gestion de bases de données relationnelles (RDBMS) sont alignés sur ce paradigme. La structure clé identifiée avec RDBMS est la structure logique appelée « table ». Les tables sont principalement composées de lignes et de colonnes (également appelées enregistrements et attributs ou tuples et champs). Au sens mathématique strict, le terme table est en fait appelé une relation et représente le terme « modèle relationnel ». En mathématiques, une relation est une représentation d'un ensemble.
L'attribut expression donne une bonne description de l'objectif d'une colonne - il caractérise l'ensemble des lignes qui lui sont associées. Chaque colonne doit être d'un type de données particulier et chaque ligne doit avoir des caractéristiques d'identification uniques appelées "clés". La modification des données est généralement plus efficace lorsqu'elle est effectuée à l'aide du modèle relationnel, tandis que la récupération des données peut être plus rapide avec l'ancien modèle hiérarchique qui a été redéfini dans les systèmes modèles NoSQL.
La normalisation des données est un processus mathématique de modélisation des données d'entreprise dans un formulaire qui garantit que chaque entité est représentée par une seule relation (table). Les premiers partisans du modèle relationnel ont proposé un concept de formes normales. Edgar Codd a défini les première, deuxième et troisième formes normales. Il est ensuite rejoint par Raymond F. Boyce. Ensemble, ils ont défini la forme normale de Boyce-Codd. À l'heure actuelle, six formes normales sont définies théoriquement, mais dans la plupart des applications pratiques, nous étendons généralement la normalisation jusqu'à la troisième forme normale. Chaque forme normale s'efforce d'éviter les anomalies lors de la modification des données, de réduire la redondance et la dépendance des données au sein d'une table. Chaque niveau de normalisation tend à introduire plus de tables, à réduire la redondance, à augmenter la simplicité de chaque table mais aussi à augmenter la complexité de l'ensemble du système de gestion de bases de données relationnelles. Donc, structurellement, les systèmes RDBM ont tendance à être plus complexes que les systèmes hiérarchiques.
Pourquoi la normalisation de la base de données :quatre anomalies
Le stockage de données sans normalisation entraîne un certain nombre de problèmes de consommation de données. Les partisans de la normalisation ont qualifié ces problèmes d'anomalies. Afin de décrire ces anomalies, regardons les données présentées dans la Fig. 1.

Fig. 1 tableau des membres du personnel
Liste 1. Tableau de base pour démontrer la normalisation de la base de données.
1.1. Créer un tableau
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Insérer des lignes
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Interroger la table
select * from staffers;
Ce tableau représente essentiellement deux ensembles de données qui ont été combinés par inadvertance :les noms du personnel et les départements. Notez que tout le personnel est du même département :Ingénierie. Cela a été fait par souci de simplicité et afin de démontrer la normalisation. Trois problèmes principaux sont associés à la manipulation de cette structure :
L'anomalie d'insertion
Afin d'insérer un nouvel enregistrement, nous devons continuer à répéter les noms de service et de responsable.
L'anomalie de suppression
Afin de supprimer la fiche d'un membre du personnel, nous devons également supprimer le responsable et le service associés. S'il est nécessaire de supprimer TOUS les enregistrements des membres du personnel, nous devons également supprimer tous les départements et tous les responsables.
L'anomalie de mise à jour
S'il est nécessaire de changer le responsable d'un service, nous devons effectuer le changement dans chaque ligne de ce tableau car les valeurs sont dupliquées pour chaque membre du personnel.
Formes normales de la base de données
Dans les sections suivantes de l'article, nous essaierons de décrire les 1ère, 2ème et 3ème formes normales qui sont beaucoup plus susceptibles d'être observées dans les vrais systèmes RDBM. Il existe d'autres extensions de la théorie telles que la quatrième, la cinquième et les formes normales de Boyce-Codd, mais dans cet article, nous nous limiterons aux trois formes normales.
La première forme normale
La 1ère Forme Normale est définie par quatre règles :
Chaque colonne doit contenir des valeurs du même type de données.
La table Staffers respecte déjà cette règle.
Chaque colonne d'un tableau doit être atomique.
Cela signifie essentiellement que vous devez diviser le contenu d'une colonne jusqu'à ce qu'il ne puisse plus être divisé. Notez que le Rôle colonne dans la colonne Staffers table enfreint la règle 2 pour la ligne avec StaffID=3.
Chaque ligne d'un tableau doit être unique.
L'unicité dans les tables normalisées est généralement obtenue à l'aide de clés primaires. Une clé primaire définit de manière unique chaque ligne d'une table. La plupart du temps, une clé primaire est définie par une seule colonne. Une clé primaire composée de plusieurs colonnes est appelée clé composite.
L'ordre dans lequel les enregistrements sont stockés n'a pas d'importance.
Pour aligner les données dans les Staffers tableau avec les principes de la première forme normale, nous devons diviser le tableau comme indiqué dans les figures 2, 3 et 4.
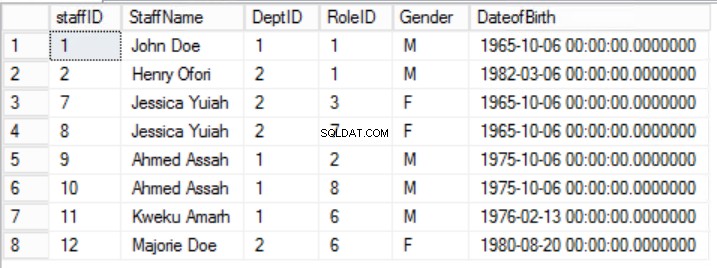
Fig. 2 Tableau des membres du personnel
Nous avons réduit les données dans les Staffers table et implémenté une clé primaire composite pour garantir l'unicité. Nous avons également créé deux tableaux supplémentaires Rôles et Départements qui ont des relations avec le noyau Staffers table implémentée à l'aide de clés étrangères. Passez en revue le DDL dans la liste 2.
Listing 2. DDL des nouveaux employés Table pour la première forme normale.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
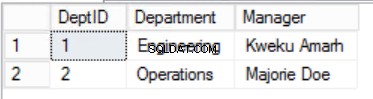
Fig. Tableau des 3 départements
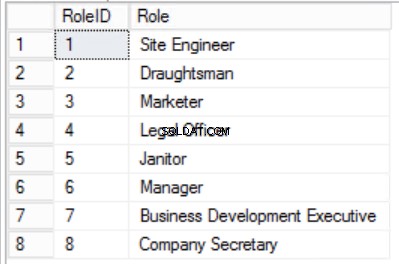
Fig. Tableau des 4 rôles
La deuxième forme normale
Le 1er formulaire normal doit déjà être en place.
Chaque colonne non clé ne doit pas avoir de dépendance partielle sur la clé primaire.
L'idée maîtresse de la deuxième règle est que toutes les colonnes de la table doivent dépendre de toutes les colonnes qui composent la clé primaire ensemble. En examinant les tableaux des figures 2, 3 et 4, nous constatons que nous avons satisfait à toutes les exigences de la première forme normale. Nous avons également atteint les exigences de la deuxième forme normale pour deux tables Rôles et Départements . Cependant, dans le cas des Staffers table, nous avons toujours un problème. Notre clé primaire est composée des colonnes StaffID et RoleID.
La règle 2 de la deuxième forme normale est enfreinte ici par le fait que le sexe et la date de naissance du personnel ne dépendent pas de l'ID de rôle. Il existe une dépendance partielle.
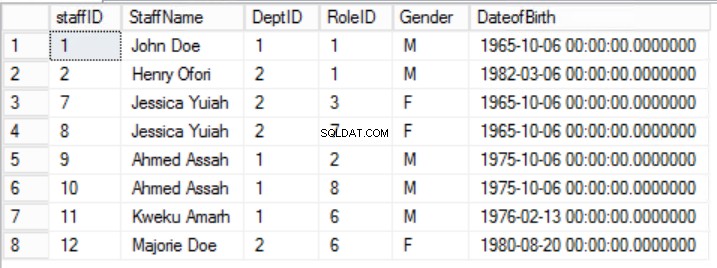
Fig. 5 membres du personnel pour la première forme normale
Dans l'exemple donné, nous pouvons essayer de résoudre ce problème en supprimant RoleID de la clé primaire, mais si nous le faisons, nous enfreindrons une autre règle :le rôle d'unicité indiqué dans la première forme normale. Nous devons adopter une autre approche. Nous modifierons les Staffers table étant entendu qu'un membre du personnel peut jouer plus d'un rôle. Voir Fig. 6.
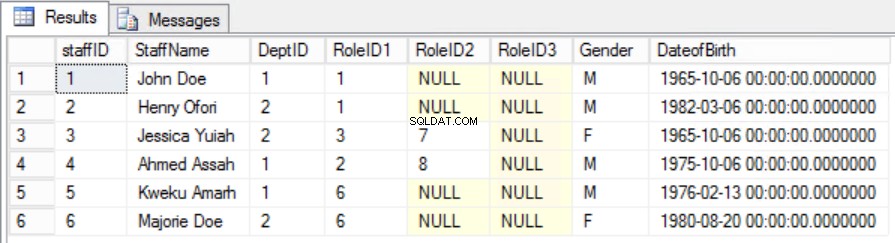
Fig. Tableau des 6 membres du personnel pour la deuxième forme normale
Nous avons réussi à maintenir l'unicité ainsi qu'à supprimer la dépendance partielle.
Listing 3. DDL du tableau des nouveaux membres du personnel pour la deuxième forme normale.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
La troisième forme normale
Le 2e formulaire normal doit déjà être en place.
Chaque colonne non clé ne doit pas avoir de dépendance transitive sur la clé primaire.
L'idée maîtresse de la troisième forme normale est qu'aucune colonne ne doit dépendre de colonnes non clés, même si ces colonnes non clés dépendent déjà de la clé primaire.
Par exemple, supposons que nous ayons décidé d'ajouter une colonne supplémentaire aux Staffers tableau comme indiqué sur la Fig. 7 afin de voir clairement le responsable du personnel. En faisant cela, nous aurions enfreint la deuxième règle de la troisième forme normale, car le nom du responsable dépend du DeptID et le DeptID, à son tour, dépend du StaffID. Il s'agit d'une dépendance transitive.
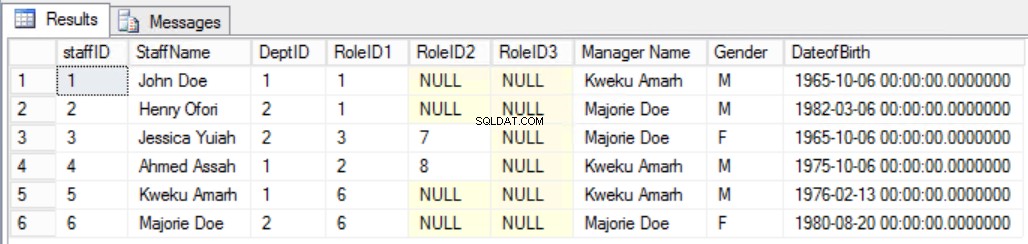
Fig. Tableau des 7 membres du personnel pour la troisième forme normale (règle brisée)
Il serait préférable de conserver l'ancien formulaire et d'afficher les informations requises en utilisant une jointure entre la table Staffers et la table Department.
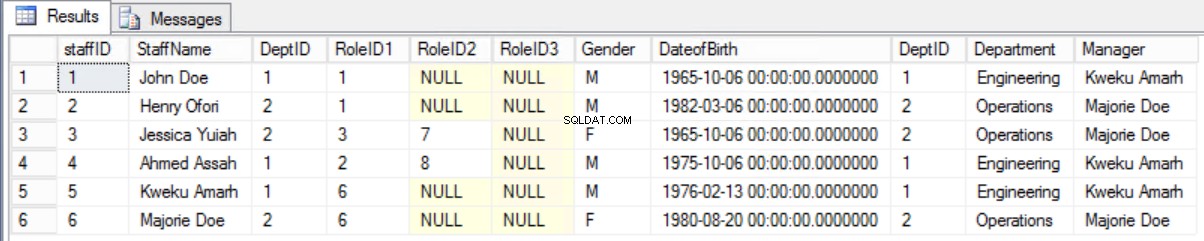
Fig. 8 Joindre entre le membre du personnel et le service
Liste 4. Requête pour afficher le personnel et les responsables.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Application pratique
La plupart des applications matures implémentent les règles de normalisation dans une mesure raisonnable. Nous voyons que la mise en œuvre de la normalisation des données donne lieu à l'utilisation de contraintes de clé primaire et de contraintes de clé étrangère. De plus, des problèmes tels que l'indexation des clés étrangères apparaissent également à mesure que nous approfondissons le sujet. Plus tôt, nous avons mentionné comment le manque de normalisation peut affecter la manipulation fluide des données comme décrit dans les Anomalies d'insertion, de suppression et de mise à jour. Un manque de normalisation appropriée peut également avoir un impact indirect sur les performances des requêtes.
Je suis récemment tombé sur un tableau qui avait la forme indiquée dans le tableau 1 que nous appellerons Customer_Accounts.
S/Non | Nom | Account_No | Téléphone_No |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tableau 1 Customer_Accounts
Le principal problème avec ce tableau est qu'il enfreint la deuxième règle de la première forme normale. Le résultat dans notre cas était que la recherche de clients en fonction de leurs numéros de téléphone nécessitait l'utilisation d'un LIKE dans la clause WHERE et d'un %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
L'impact de la construction ci-dessus était que l'optimiseur n'utilisait jamais un index, ce qui posait un énorme problème de performances.
Conclusion
La normalisation des données relève du domaine de la conception de bases de données et les développeurs et les administrateurs de base de données doivent prêter attention aux règles décrites dans cet article. Il est toujours préférable d'effectuer la normalisation avant que la base de données ne passe en production. Les avantages d'un système de gestion de base de données relationnelle bien conçu valent tout simplement l'effort.