Chaque produit a des bogues, et SQL Server ne fait pas exception. L'utilisation des fonctionnalités du produit d'une manière légèrement inhabituelle (ou la combinaison de fonctionnalités relativement nouvelles) est un excellent moyen de les trouver. Les bogues peuvent être intéressants, et même éducatifs, mais peut-être que certaines joies sont perdues lorsque la découverte entraîne le déclenchement de votre téléavertisseur à 4 heures du matin, peut-être après une soirée particulièrement sociale avec des amis…
Le bogue qui fait l'objet de cet article est probablement raisonnablement rare dans la nature, mais ce n'est pas un cas classique. Je connais au moins un consultant qui l'a rencontré dans un système de production. Sur un sujet qui n'a rien à voir, je profite de l'occasion pour dire "bonjour" au Grumpy Old DBA (blog).
Je vais commencer par quelques informations pertinentes sur les jointures de fusion. Si vous êtes certain que vous savez déjà tout ce qu'il y a à savoir sur la jointure par fusion, ou si vous voulez simplement aller droit au but, n'hésitez pas à faire défiler jusqu'à la section intitulée "Le bogue".
Fusionner la jointure
La jointure par fusion n'est pas une chose très compliquée et peut être très efficace dans les bonnes circonstances. Il nécessite que ses entrées soient triées sur les clés de jointure et fonctionne mieux en mode un-à-plusieurs (où au moins de ses entrées sont uniques sur les clés de jointure). Pour les jointures un-à-plusieurs de taille moyenne, la jointure par fusion en série n'est pas du tout un mauvais choix, à condition que les exigences de tri des entrées puissent être satisfaites sans effectuer de tri explicite.
Éviter un tri est le plus souvent réalisé en exploitant l'ordre fourni par un index. La jointure par fusion peut également tirer parti de l'ordre de tri préservé d'un tri antérieur inévitable. Une chose intéressante à propos de la jointure par fusion est qu'elle peut arrêter de traiter les lignes d'entrée dès que l'une des entrées est à court de lignes. Une dernière chose:la jointure de fusion ne se soucie pas de savoir si l'ordre de tri des entrées est croissant ou décroissant (bien que les deux entrées doivent être identiques). L'exemple suivant utilise un tableau Numbers standard pour illustrer la plupart des points ci-dessus :
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Notez que les index appliquant les clés primaires sur ces deux tables sont définis comme décroissants. Le plan de requête pour INSERT a un certain nombre de fonctionnalités intéressantes :
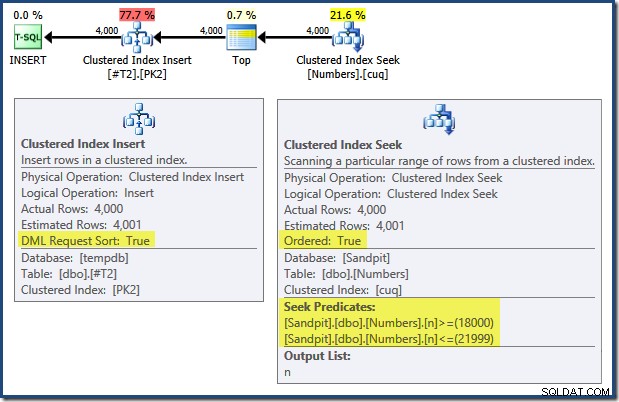
En lisant de gauche à droite (comme c'est logique !), l'insertion d'index groupé a la propriété "DML Request Sort" définie. Cela signifie que l'opérateur a besoin de lignes dans l'ordre des clés de l'index clusterisé. L'index clusterisé (appliquant la clé primaire dans ce cas) est défini comme DESC , les lignes avec des valeurs plus élevées doivent donc arriver en premier. L'index clusterisé sur ma table Numbers est ASC , de sorte que l'optimiseur de requête évite un tri explicite en recherchant d'abord la correspondance la plus élevée dans la table des nombres (21 999), puis en balayant vers la correspondance la plus faible (18 000) dans l'ordre inverse de l'index. La vue "Arborescence du plan" dans SQL Sentry Plan Explorer affiche clairement l'analyse inversée :
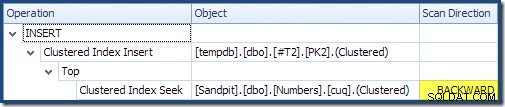
Le balayage vers l'arrière inverse l'ordre naturel de l'index. Un balayage vers l'arrière d'un ASC la clé d'index renvoie les lignes dans l'ordre décroissant des clés ; un balayage vers l'arrière d'un DESC La clé d'index renvoie les lignes dans l'ordre croissant des clés. La "direction de balayage" n'indique pas l'ordre des clés renvoyées par elle-même - vous devez savoir si l'index est ASC ou DESC pour prendre cette décision.
À l'aide de ces tables et données de test (T1 a 10 000 lignes numérotées de 10 000 à 19 999 inclus; T2 contient 4 000 lignes numérotées de 18 000 à 21 999), la requête suivante joint les deux tables et renvoie les résultats dans l'ordre décroissant des deux clés :
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; La requête renvoie les 2 000 lignes correspondantes correctes, comme prévu. Le plan de post-exécution est le suivant :
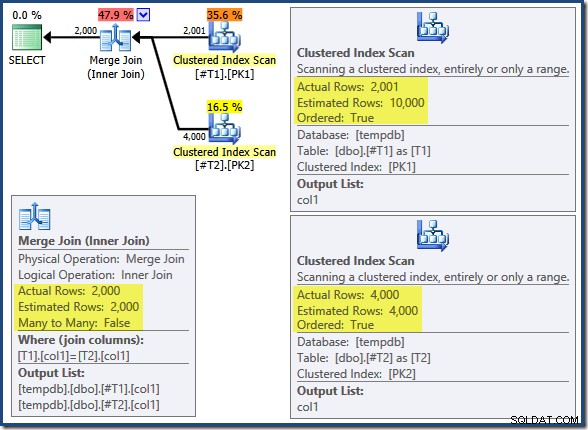
La jointure de fusion ne s'exécute pas en mode plusieurs à plusieurs (l'entrée supérieure est unique sur les clés de jointure) et l'estimation de cardinalité de 2 000 lignes est tout à fait correcte. Le balayage d'index clusterisé de la table T2 est ordonné (bien que nous devions attendre un moment pour découvrir si cet ordre est en avant ou en arrière) et l'estimation de cardinalité de 4 000 lignes est également tout à fait correcte. Le balayage d'index clusterisé de la table T1 est également ordonné, mais seules 2 001 lignes ont été lues alors que 10 000 ont été estimées. L'arborescence du plan montre que les deux balayages d'index clusterisés sont ordonnés vers l'avant :
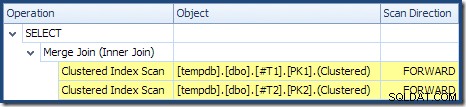
Rappelons que la lecture d'un DESC index FORWARD produira des lignes dans l'ordre inverse des clés. C'est exactement ce qui est requis par le ORDER BY T1.col DESC, T2.col1 DESC clause, donc aucun tri explicite n'est nécessaire. Le pseudo-code pour un-à-plusieurs Merge Join (reproduit du blog Merge Join de Craig Freedman) est :

L'analyse de l'ordre décroissant de T1 renvoie les lignes commençant à 19 999 et descendant vers 10 000. Le scan par ordre décroissant de T2 renvoie les lignes commençant à 21 999 et descendant vers 18 000. Toutes les 4 000 lignes dans T2 sont finalement lus, mais le processus de fusion itératif s'arrête lorsque la valeur de clé 17 999 est lue à partir de T1 , car T2 manque de rangées. Le traitement de la fusion se termine donc sans lire entièrement T1 . Il lit les lignes de 19 999 à 17 999 inclus; un total de 2 001 lignes, comme indiqué dans le plan d'exécution ci-dessus.
N'hésitez pas à relancer le test avec ASC indexe à la place, en changeant également le ORDER BY clause de DESC vers ASC . Le plan d'exécution produit sera très similaire et aucun tri ne sera nécessaire.
Pour résumer les points qui seront importants dans un instant, Merge Join nécessite des entrées triées par clé de jointure, mais peu importe que les clés soient triées par ordre croissant ou décroissant.
Le bogue
Pour reproduire le bogue, au moins une de nos tables doit être partitionnée. Pour que les résultats restent gérables, cet exemple n'utilisera qu'un petit nombre de lignes, de sorte que la fonction de partitionnement a également besoin de petites limites :
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
La première table contient deux colonnes, et est partitionnée sur la PRIMARY KEY :
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
La deuxième table n'est pas partitionnée. Il contient une clé primaire et une colonne qui se joindra à la première table :
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Les exemples de données
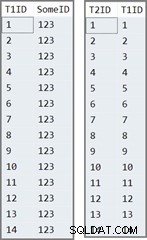
La première table a 14 lignes, toutes avec la même valeur dans le SomeID colonne. SQL Server attribue le IDENTITY valeurs des colonnes, numérotées de 1 à 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
La deuxième table est simplement remplie avec le IDENTITY valeurs du tableau 1 :
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
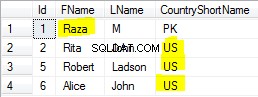
Les données des deux tables ressemblent à ceci :
La requête test
La première requête joint simplement les deux tables, en appliquant un seul prédicat de clause WHERE (qui correspond à toutes les lignes dans cet exemple très simplifié) :
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Le résultat contient les 14 lignes, comme prévu :

En raison du petit nombre de lignes, l'optimiseur choisit un plan de jointure de boucles imbriquées pour cette requête :
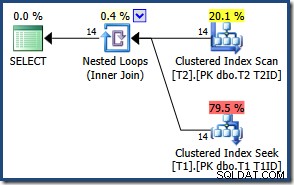
Les résultats sont les mêmes (et toujours corrects) si nous forçons un hachage ou une jointure par fusion :
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
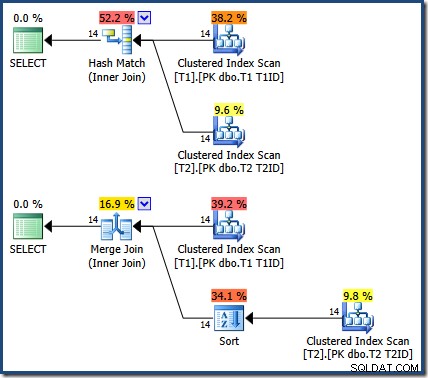
La jointure de fusion y est un-à-plusieurs, avec un tri explicite sur T1ID obligatoire pour la table T2 .
Le problème de l'index décroissant
Tout va bien jusqu'au jour où (pour de bonnes raisons qui n'ont pas à nous préoccuper ici) un autre administrateur ajoute un index descendant sur le SomeID colonne du tableau 1 :
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Notre requête continue de produire des résultats corrects lorsque l'optimiseur choisit une boucle imbriquée ou une jointure par hachage, mais c'est une autre histoire lorsqu'une jointure par fusion est utilisée. Ce qui suit utilise toujours un indicateur de requête pour forcer la jointure de fusion, mais ce n'est qu'une conséquence du faible nombre de lignes dans l'exemple. L'optimiseur choisirait naturellement le même plan de jointure par fusion avec des données de table différentes.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Le plan d'exécution est :
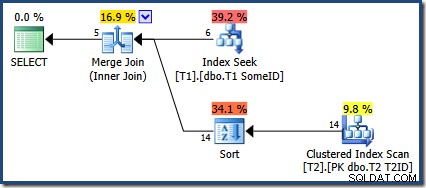
L'optimiseur a choisi d'utiliser le nouvel index, mais la requête ne produit plus que cinq lignes de sortie :

Qu'est-il arrivé aux 9 autres rangées ? Pour être clair, ce résultat est incorrect. Les données n'ont pas changé, donc les 14 lignes doivent être renvoyées (comme elles le sont toujours avec un plan Nested Loops ou Hash Join).
Cause et explication
Le nouvel index non clusterisé sur SomeID n'est pas déclaré unique, la clé d'index cluster est donc ajoutée silencieusement à tous les niveaux d'index non cluster. SQL Server ajoute le T1ID colonne (la clé clusterisée) à l'index non clusterisé comme si nous avions créé l'index comme ceci :
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Remarquez l'absence de DESC qualificatif sur le T1ID ajouté silencieusement clé. Les clés d'index sont ASC par défaut. Ce n'est pas un problème en soi (bien que cela y contribue). La deuxième chose qui arrive automatiquement à notre index est qu'il est partitionné de la même manière que la table de base. Ainsi, la spécification complète de l'index, si nous devions l'écrire explicitement, serait :
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Il s'agit maintenant d'une structure assez complexe, avec des clés dans toutes sortes d'ordres différents. Il est suffisamment complexe pour que l'optimiseur de requête se trompe lorsqu'il raisonne sur l'ordre de tri fourni par l'index. Pour illustrer, considérez la requête simple suivante :
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
La colonne supplémentaire nous montrera simplement à quelle partition appartient la ligne actuelle. Sinon, c'est juste une simple requête qui renvoie T1ID valeurs dans l'ordre croissant, WHERE SomeID = 123 . Malheureusement, les résultats ne correspondent pas à ceux spécifiés par la requête :
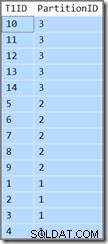
La requête nécessite que T1ID les valeurs doivent être renvoyées dans l'ordre croissant, mais ce n'est pas ce que nous obtenons. Nous obtenons des valeurs dans l'ordre croissant par partition , mais les partitions elles-mêmes sont renvoyées dans l'ordre inverse ! Si les partitions ont été retournées dans l'ordre croissant (et le T1ID les valeurs restaient triées dans chaque partition comme indiqué), le résultat serait correct.
Le plan de requête montre que l'optimiseur a été confondu par le premier DESC clé de l'index, et j'ai pensé qu'il fallait lire les partitions dans l'ordre inverse pour obtenir des résultats corrects :
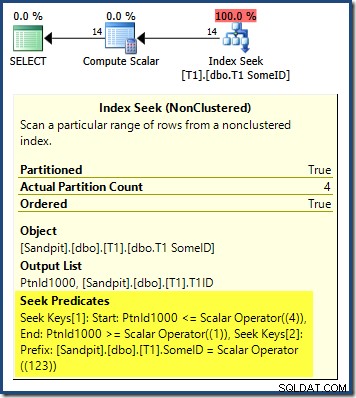
La recherche de partition commence à la partition la plus à droite (4) et revient à la partition 1. Vous pourriez penser que nous pourrions résoudre le problème en triant explicitement sur le numéro de partition ASC dans le ORDER BY clause :
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Cette requête retourne les mêmes résultats (il ne s'agit pas d'une faute de frappe ou d'une erreur de copier/coller) :
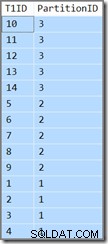
L'identifiant de la partition est toujours en décroissant ordre (non croissant, comme spécifié) et T1ID est uniquement trié par ordre croissant dans chaque partition. Telle est la confusion de l'optimiseur, il pense vraiment (prenez une profonde respiration maintenant) que l'analyse de l'index partitionné de la clé principale-descendante vers l'avant, mais avec des partitions inversées, se traduira par l'ordre spécifié par la requête.
Je ne lui en veux pas d'être franc, les diverses considérations d'ordre de tri me font aussi mal à la tête.
Comme dernier exemple, considérez :
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Les résultats sont :

Encore une fois, le T1ID ordre de tri dans chaque partition est correctement décroissant, mais les partitions elles-mêmes sont répertoriées à l'envers (elles vont de 1 à 3 dans les lignes). Si les partitions étaient retournées dans l'ordre inverse, les résultats seraient correctement 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Retour à la jointure de fusion
La cause des résultats incorrects avec la requête Merge Join est maintenant apparente :
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
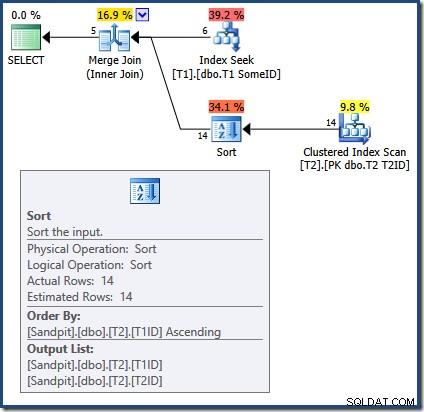
La jointure de fusion nécessite des entrées triées. L'entrée de T2 est explicitement trié par T1TD donc ça va. L'optimiseur raisonne à tort que l'index sur T1 peut fournir des lignes dans T1ID Commande. Comme nous l'avons vu, ce n'est pas le cas. L'Index Seek produit le même résultat qu'une requête que nous avons déjà vue :
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Seules les 5 premières lignes sont dans T1ID Commande. La valeur suivante (5) n'est certainement pas dans l'ordre croissant, et la jointure de fusion interprète cela comme une fin de flux plutôt que de produire une erreur (personnellement, je m'attendais à une assertion de vente au détail ici). Quoi qu'il en soit, l'effet est que la jointure de fusion termine de manière incorrecte le traitement plus tôt. Pour rappel, les résultats (incomplets) sont :

Conclusion
C'est un bug très sérieux à mon avis. Une simple recherche d'index peut renvoyer des résultats qui ne respectent pas le ORDER BY clause. Plus précisément, le raisonnement interne de l'optimiseur est complètement cassé pour les index partitionnés non uniques non clusterisés avec une clé de tête décroissante.
Oui, c'est un légèrement disposition inhabituelle. Mais, comme nous l'avons vu, des résultats corrects peuvent être soudainement remplacés par des résultats incorrects simplement parce que quelqu'un a ajouté un index décroissant. N'oubliez pas que l'index ajouté semblait assez innocent :pas de ASC/DESC explicite incompatibilité de clé et pas de partitionnement explicite.
Le bogue n'est pas limité aux jointures par fusion. Potentiellement, toute requête qui implique une table partitionnée et qui repose sur l'ordre de tri de l'index (explicite ou implicite) pourrait en être victime. Ce bogue existe dans toutes les versions de SQL Server de 2008 à 2014 CTP 1 inclus. La base de données Windows SQL Azure ne prend pas en charge le partitionnement, le problème ne se pose donc pas. SQL Server 2005 a utilisé un modèle d'implémentation différent pour le partitionnement (basé sur APPLY ) et ne souffre pas non plus de ce problème.
Si vous avez un moment, pensez à voter sur mon article Connect pour ce bogue.
Résolution
Le correctif de ce problème est désormais disponible et documenté dans un article de la base de connaissances. Veuillez noter que le correctif nécessite une mise à jour du code et l'indicateur de trace 4199 , qui permet une gamme d'autres modifications du processeur de requêtes. Il est inhabituel qu'un bogue de résultats incorrects soit corrigé sous 4199. J'ai demandé des éclaircissements à ce sujet et la réponse a été :
Même si ce problème implique des résultats incorrects comme d'autres correctifs impliquant le processeur de requêtes, nous n'avons activé ce correctif que sous l'indicateur de trace 4199 pour SQL Server 2008, 2008 R2 et 2012. Cependant, ce correctif est "activé" par par défaut sans l'indicateur de trace dans SQL Server 2014 RTM.