Ce blog est la deuxième partie de Implémentation d'une configuration multi-centre de données pour PostgreSQL. Dans ce coup, nous montrerons comment déployer PostgreSQL dans ce type d'environnement et comment basculer en cas de défaillance du maître à l'aide de la fonctionnalité de récupération automatique de ClusterControl.
À ce stade, nous supposerons que vous disposez d'une connectivité entre les centres de données (comme nous l'avons vu dans la première partie de ce blog) et que vous disposez des serveurs nécessaires pour cette tâche (comme nous l'avons également mentionné dans le partie précédente).
Déployer un cluster PostgreSQL
Nous utiliserons ClusterControl pour cette tâche, nous supposerons donc que vous l'avez installé (il pourrait être installé sur le même serveur Load Balancer, mais si vous pouvez en utiliser un autre, c'est encore mieux).
Allez sur votre serveur ClusterControl et sélectionnez l'option "Déployer". Si vous avez déjà une instance PostgreSQL en cours d'exécution, vous devez sélectionner "Importer un serveur/une base de données existants" à la place.
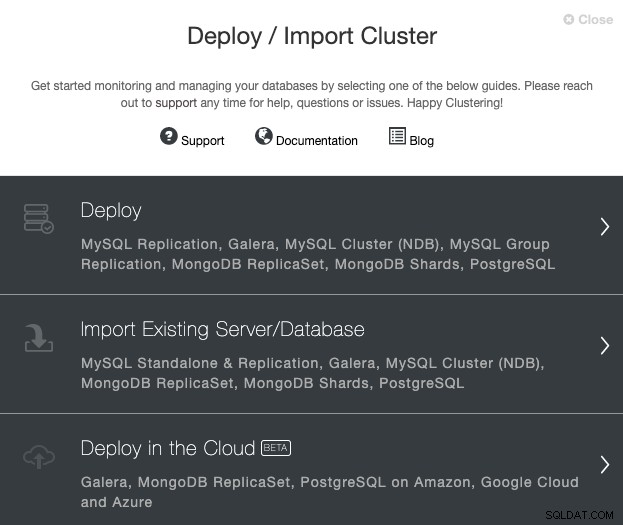
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier l'utilisateur, la clé ou le mot de passe et le port à connectez-vous en SSH à nos hôtes PostgreSQL. Vous avez également besoin du nom de votre nouveau cluster et si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
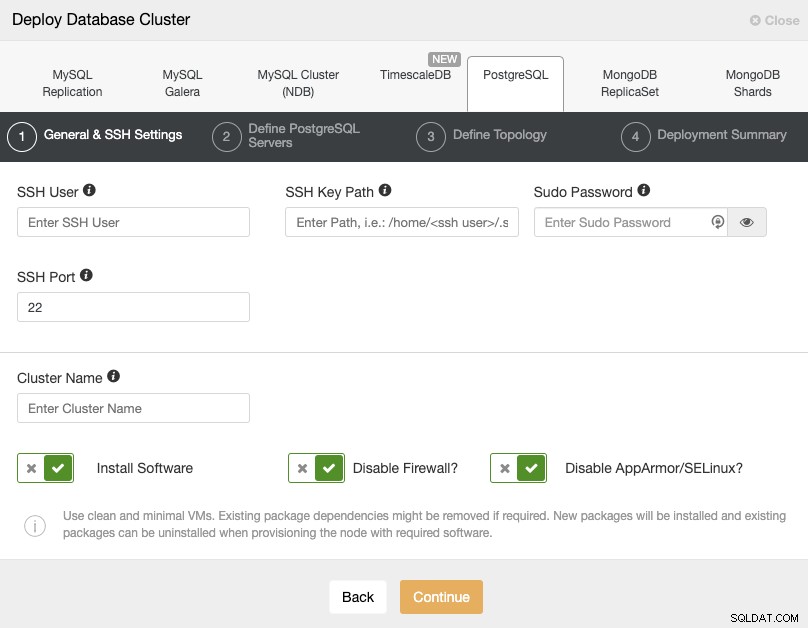
Veuillez vérifier les exigences utilisateur de ClusterControl pour cette tâche ici, mais si vous avez suivi le blog précédent, vous devez utiliser l'utilisateur "distant" ici et le bon port SSH (comme nous l'avons mentionné, il est recommandé d'en utiliser un autre si vous utilisez l'adresse IP publique pour y accéder au lieu d'un VPN).
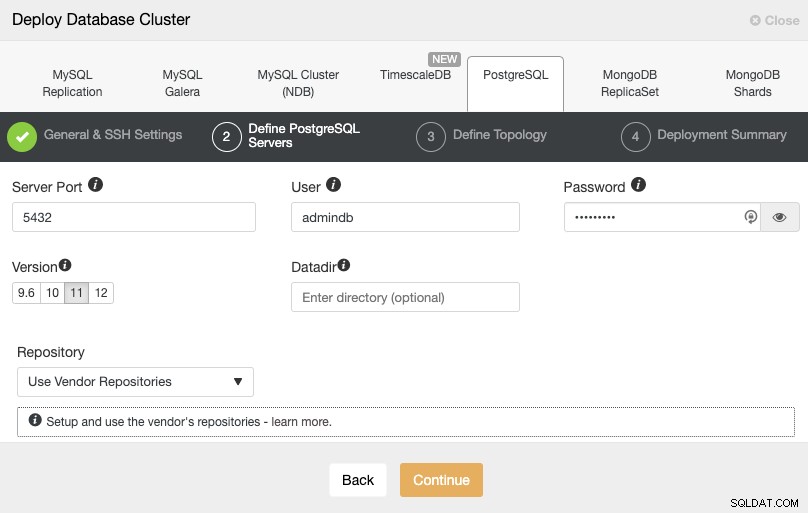
Après avoir configuré les informations d'accès SSH, vous devez définir l'utilisateur de la base de données, version et datadir (facultatif). Vous pouvez également spécifier le référentiel à utiliser. À l'étape suivante, vous devez ajouter vos serveurs au cluster que vous allez créer.
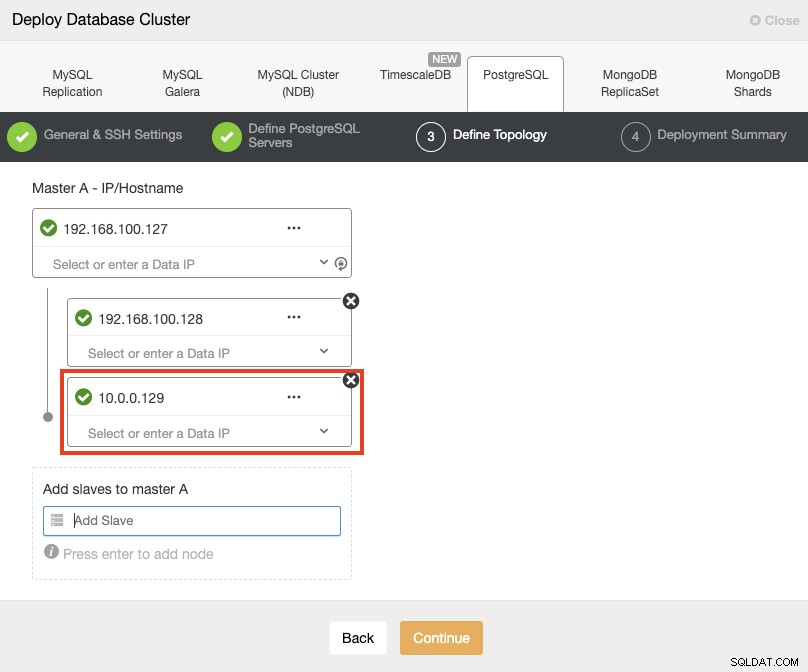
Lorsque vous ajoutez vos serveurs, vous pouvez entrer l'IP ou le nom d'hôte. Dans cette partie, vous utiliserez les adresses IP publiques de vos serveurs, et comme vous pouvez le voir dans la case rouge, j'utilise un réseau différent pour le deuxième nœud de secours. ClusterControl n'a aucune limitation sur le réseau à utiliser. La seule exigence à ce sujet est d'avoir un accès SSH au nœud.
Donc, en suivant notre exemple précédent, ces adresses IP devraient être :
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Dans la dernière étape, vous pouvez choisir si votre réplication sera synchrone ou asynchrone.
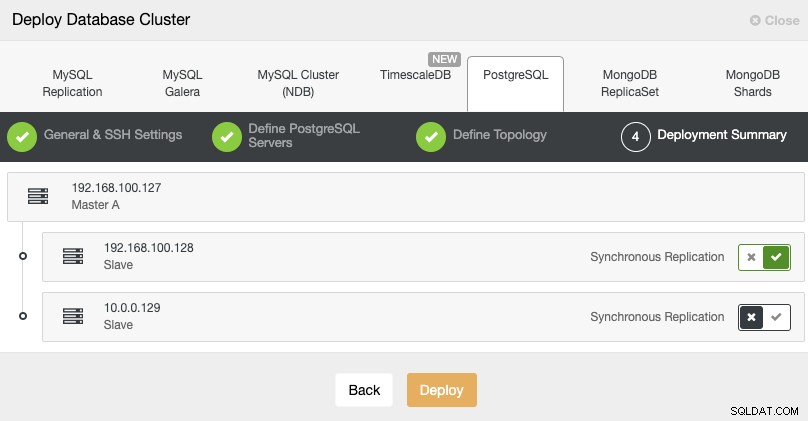
Dans ce cas, il est important d'utiliser la réplication asynchrone pour votre nœud distant , sinon, votre cluster pourrait être affecté par la latence ou des problèmes de réseau.
Vous pouvez surveiller l'état de la création de votre nouveau cluster à partir du moniteur d'activité de ClusterControl.
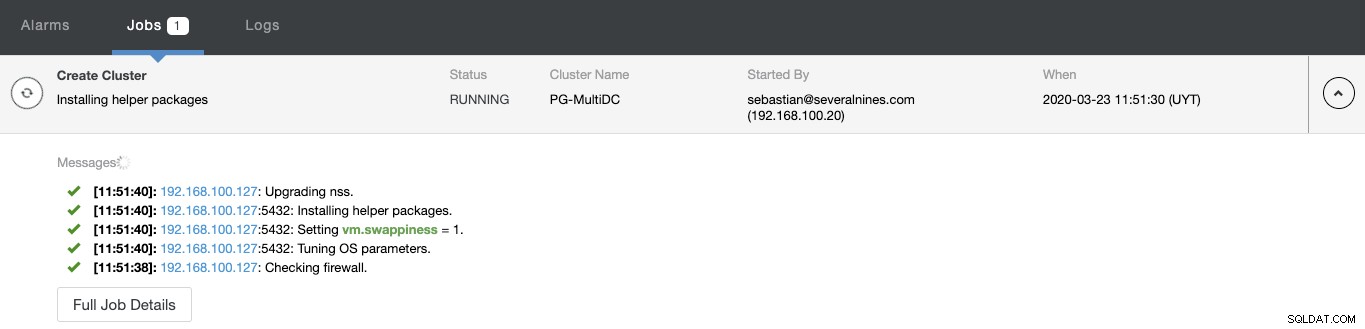
Une fois la tâche terminée, vous pouvez voir votre nouveau cluster PostgreSQL dans le l'écran principal de ClusterControl.

Ajout d'un équilibreur de charge PostgreSQL (HAProxy)
Une fois que vous avez créé votre cluster, vous pouvez y effectuer plusieurs tâches, comme ajouter un équilibreur de charge (HAProxy) ou un nouveau réplica.
Pour suivre notre exemple précédent, ajoutons un équilibreur de charge qui, comme nous l'avons mentionné, vous aidera à gérer votre environnement HA. Pour cela, allez dans ClusterControl -> Select PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
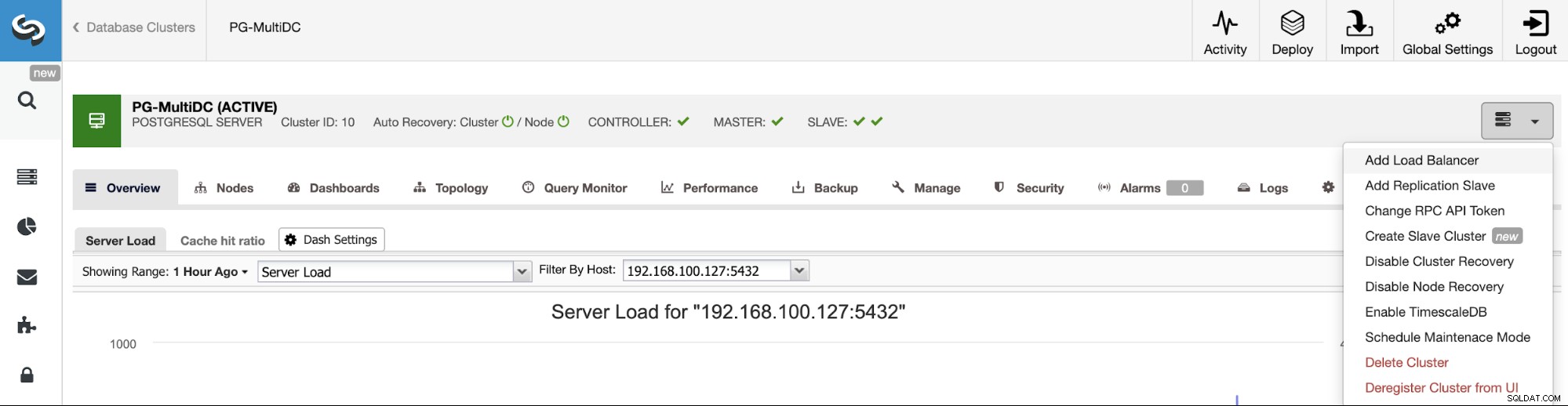
Vous devez ajouter ici les informations que ClusterControl utilisera pour installer et configurer votre Équilibreur de charge HAProxy. Ce Load Balancer peut être installé sur le même serveur ClusterControl, mais si vous pouvez en utiliser un autre, c'est encore mieux.
Les informations que vous devez introduire sont :
Action :déployer ou importer.
Adresse du serveur :adresse IP de votre serveur HAProxy (il peut s'agir de la même adresse IP ClusterControl).
Port d'écoute (lecture/écriture) :port pour le mode lecture/écriture.
Port d'écoute (lecture seule) :port pour le mode lecture seule.
Politique :Cela peut être :
- leastconn :le serveur avec le plus petit nombre de connexions reçoit la connexion.
- roundrobin :chaque serveur est utilisé à tour de rôle, en fonction de son poids.
- source :l'adresse IP source est hachée et divisée par le poids total des serveurs en cours d'exécution pour désigner le serveur qui recevra la requête.
Installer pour le fractionnement lecture/écriture :pour la réplication maître-esclave.
Construire à partir de la source :vous pouvez choisir d'installer à partir d'un gestionnaire de packages ou de créer à partir de la source.
Et vous devez sélectionner les serveurs que vous souhaitez ajouter à la configuration HAProxy.
Vous pouvez également configurer des paramètres avancés tels que l'utilisateur administrateur, le nom du backend, les délais d'attente, etc.
Lorsque vous avez terminé la configuration et confirmé le déploiement, vous pouvez suivre la progression dans la section Activité de l'interface utilisateur de ClusterControl.
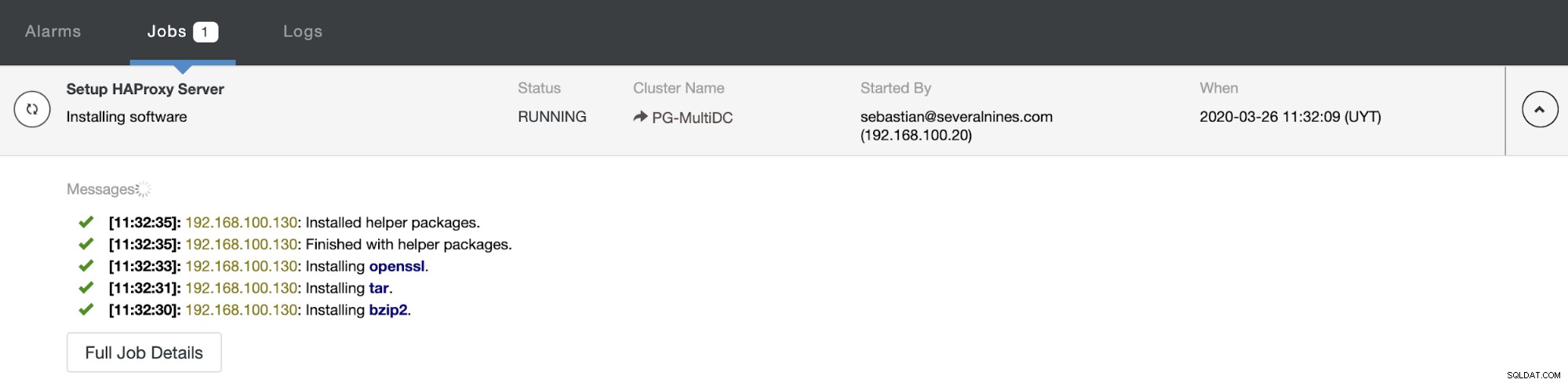
Et lorsque cela se termine, vous pouvez accéder à ClusterControl -> Nodes -> nœud HAProxy et vérifiez l'état actuel.
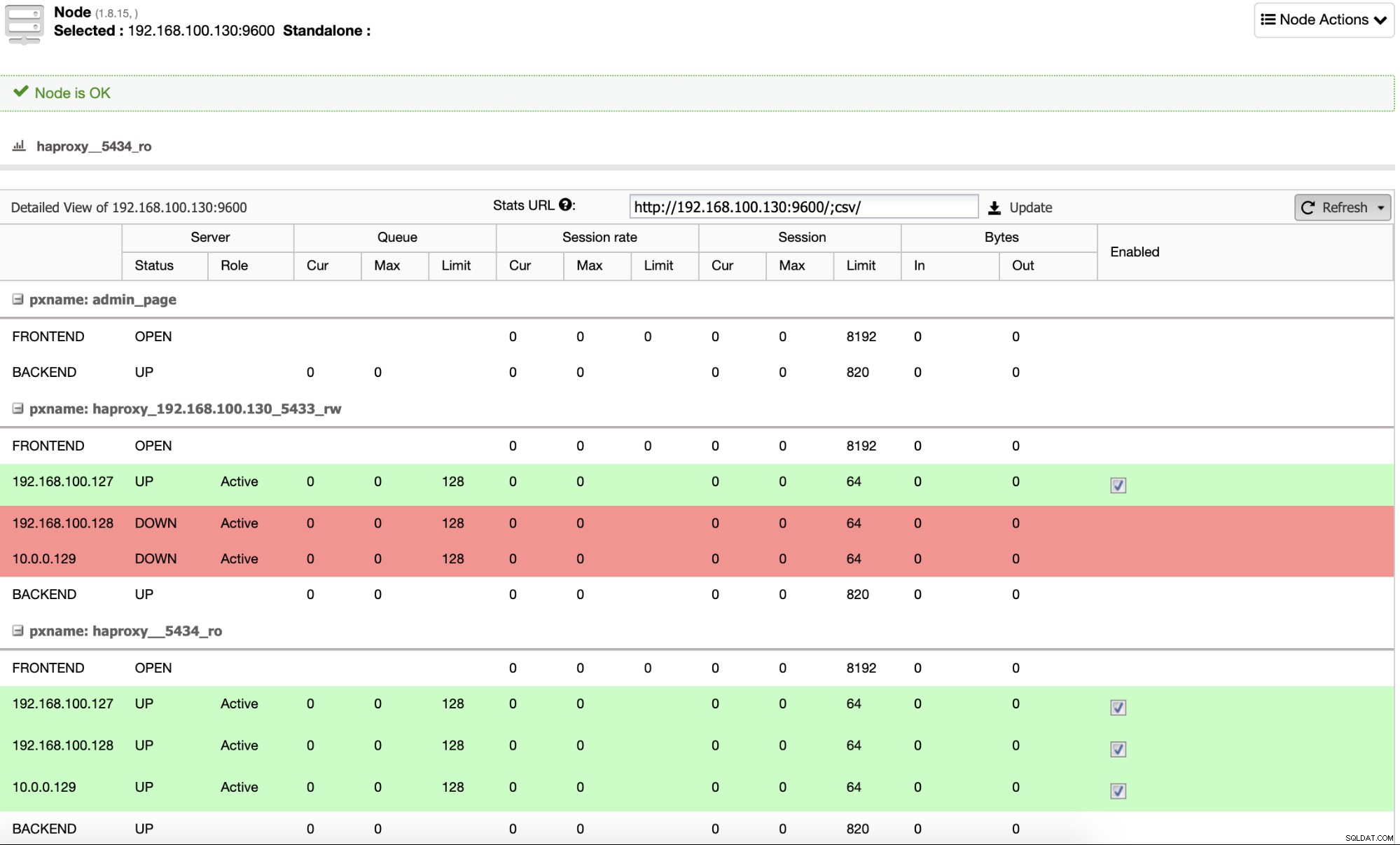
Par défaut, ClusterControl configure HAProxy avec deux ports différents, un pour la lecture Write, qui sera utilisé pour que l'application ou l'utilisateur écrive (et lise) des données, et un autre pour Read-Only, qui sera utilisé pour équilibrer le trafic de lecture entre tous les nœuds. Dans le port Lecture-Écriture, seul le nœud maître est activé, et en cas de défaillance du maître, ClusterControl promouvra l'esclave le plus avancé en maître et reconfigurera ce port pour désactiver l'ancien maître et activer le nouveau. De cette façon, votre application peut toujours fonctionner en cas de défaillance de la base de données principale, car le trafic est redirigé par le Load Balancer vers le bon nœud.
Vous pouvez également surveiller vos serveurs HAProxy en consultant la section Tableau de bord.
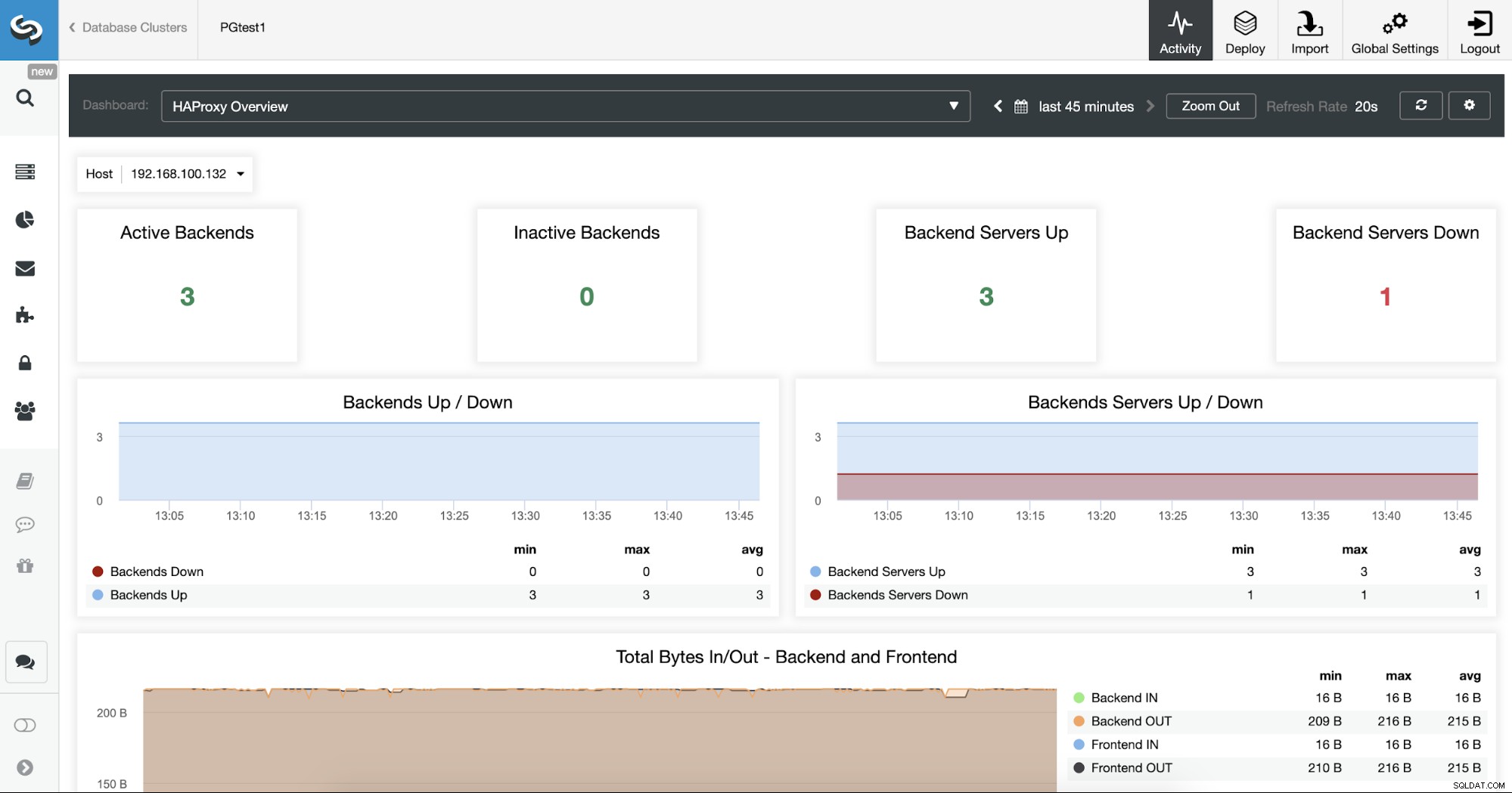
Maintenant, vous pouvez améliorer votre conception HA en ajoutant un nouveau nœud HAProxy dans le centre de données distant et configuration du service Keepalived entre eux. Keepalived vous permettra d'utiliser une adresse IP virtuelle attribuée au nœud Load Balancer actif. Si ce nœud échoue, cette adresse IP virtuelle sera migrée vers le nœud HAProxy secondaire, donc avoir cette adresse IP configurée dans votre application vous permettra de continuer à fonctionner en cas de problème de Load Balancer.
Toute cette configuration peut être effectuée à l'aide de ClusterControl.
Conclusion
En suivant ce blog en deux parties, vous pouvez implémenter une configuration multi-centre de données pour PostgreSQL avec une haute disponibilité et une connectivité SSH entre le centre de données, pour éviter la complexité d'une configuration VPN.
En utilisant la réplication asynchrone pour le nœud distant, vous éviterez tout problème lié à la latence et aux performances du réseau, et en utilisant ClusterControl, vous aurez un basculement automatique (ou manuel) en cas de panne (entre autres plusieurs fonctionnalités). Cela pourrait être le moyen le plus simple d'atteindre cette topologie et nous espérons que cela vous sera utile.