Pour toute nouvelle base de données créée dans SQL Server, la valeur par défaut de l'option de mise à jour automatique des statistiques est activée . Je soupçonne que la plupart des DBA laissent l'option activée, car elle permet à l'optimiseur de mettre à jour automatiquement les statistiques lorsqu'elles sont invalidées, et il est généralement recommandé de la laisser activée. Les statistiques sont également mises à jour lorsque les index sont reconstruits, et bien qu'il ne soit pas rare que les statistiques soient bien gérées via l'option de mise à jour automatique des statistiques et via les reconstructions d'index, de temps en temps, un administrateur de base de données peut trouver nécessaire de configurer une tâche régulière pour mettre à jour un statistique ou ensemble de statistiques.
La gestion personnalisée des statistiques implique souvent la commande UPDATE STATISTICS, qui semble assez bénigne. Il peut être exécuté pour toutes les statistiques d'une table ou d'une vue indexée, ou pour une statistique spécifique. L'échantillon par défaut peut être utilisé, un taux d'échantillonnage spécifique ou un nombre de lignes à échantillonner peut être spécifié, ou vous pouvez utiliser la même valeur d'échantillon que celle utilisée précédemment. Si les statistiques sont mises à jour pour une table ou une vue indexée, vous pouvez choisir de mettre à jour toutes les statistiques, uniquement les statistiques d'index ou uniquement les statistiques de colonne. Et enfin, vous pouvez désactiver l'option de mise à jour automatique des statistiques pour une statistique.
Pour la plupart des administrateurs de base de données, la plus grande considération peut être quand pour exécuter l'instruction UPDATE STATISTICS. Mais les DBA décident également, consciemment ou non, de la taille de l'échantillon pour la mise à jour. La taille de l'échantillon sélectionné peut affecter les performances de la mise à jour réelle, ainsi que les performances des requêtes.
Comprendre les effets de la taille de l'échantillon
La taille d'échantillon par défaut pour UPDATE STATISTICS provient d'un algorithme non linéaire, et la taille d'échantillon diminue à mesure que la taille de la table augmente, comme Joe Sack l'a montré dans son article, Auto-Update Stats Default Sampling Test. Dans certains cas, la taille de l'échantillon peut ne pas être assez grande pour capturer suffisamment d'informations intéressantes, ou le bon informations, pour l'histogramme des statistiques, comme l'a noté Conor Cunningham dans son article Statistics Sample Rates. Si l'échantillon par défaut ne crée pas un bon histogramme, les DBA peuvent choisir de mettre à jour les statistiques avec un taux d'échantillonnage plus élevé, jusqu'à un FULLSCAN (balayage de toutes les lignes de la table ou de la vue indexée). Mais comme Conor l'a mentionné dans son article, la numérisation de plus de lignes a un coût, et le DBA est mis au défi de décider s'il doit exécuter un FULLSCAN pour essayer de créer le "meilleur" histogramme possible, ou échantillonner un pourcentage plus petit pour minimiser l'impact sur les performances de la mise à jour.
Pour essayer de comprendre à quel point un échantillon prend plus de temps qu'un FULLSCAN, j'ai exécuté les instructions suivantes sur des copies de la table SalesOrderDetail agrandies à l'aide du script de Jonathan Kehayias :
| ID d'instruction | Instruction UPDATE STATISTICS |
|---|---|
| 1 | METTRE À JOUR LES STATISTIQUES [Ventes].[SalesOrderDetailEnlarged] AVEC FULLSCAN ; |
| 2 | METTRE À JOUR LES STATISTIQUES [Ventes].[SalesOrderDetailEnlarged] ; |
| 3 | METTRE À JOUR LES STATISTIQUES [Sales].[SalesOrderDetailEnlarged] AVEC UN ÉCHANTILLON DE 10 % ; |
| 4 | METTRE À JOUR LES STATISTIQUES [Sales].[SalesOrderDetailEnlarged] AVEC UN ÉCHANTILLON DE 25 POUR CENT ; |
| 5 | METTRE À JOUR LES STATISTIQUES [Sales].[SalesOrderDetailEnlarged] AVEC UN ÉCHANTILLON DE 50 % ; |
| 6 | METTRE À JOUR LES STATISTIQUES [Sales].[SalesOrderDetailEnlarged] AVEC UN ÉCHANTILLON À 75 % ; |
J'avais trois copies de la table SalesOrderDetailEnlarged, avec les caractéristiques suivantes* :
| Nombre de lignes | Nombre de pages | MAXDOP | Mémoire maximale | Stockage | Machine |
|---|---|---|---|---|---|
| 23 899 449 | 363 284 | 4 | 8 Go | SSD_1 | Ordinateur portable |
| 607 312 902 | 7 757 200 | 16 | 54 Go | SSD_2 | Serveur de test |
| 607 312 902 | 7 757 200 | 16 | 54 Go | 15K | Serveur de test |
*Des détails supplémentaires sur le matériel sont à la fin de cet article.
Toutes les copies de la table avaient les statistiques suivantes, et aucune des trois statistiques d'index n'incluait de colonnes :
| Statistique | Type | Colonnes dans la clé |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | guide de ligne |
| IX_SalesOrderDetailEnlarged_ProductID | Index | ID de produit |
| user_CarrierTrackingNumber | Colonne | Numéro de suivi du transporteur |
J'ai exécuté les instructions UPDATE STATISTICS ci-dessus quatre fois chacune sur la table SalesOrderDetailEnlarged sur mon ordinateur portable, et deux fois chacune sur les tables SalesOrderDetailEnlarged sur le TestServer. Les instructions étaient exécutées dans un ordre aléatoire à chaque fois, et le cache de procédure et le cache de tampon étaient effacés avant chaque instruction de mise à jour. La durée et l'utilisation de tempdb pour chaque ensemble d'instructions (en moyenne) sont présentées dans les graphiques ci-dessous :
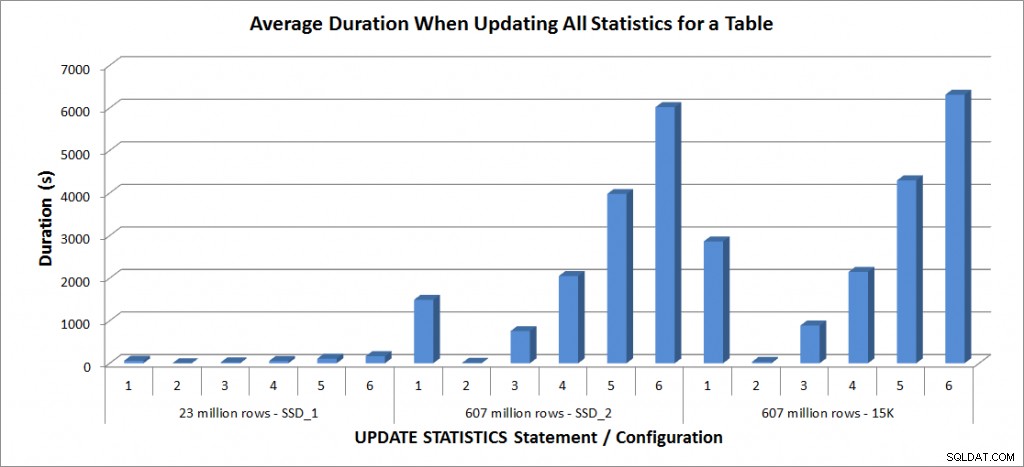
Durée moyenne – Mettre à jour toutes les statistiques pour SalesOrderDetailEnlarged
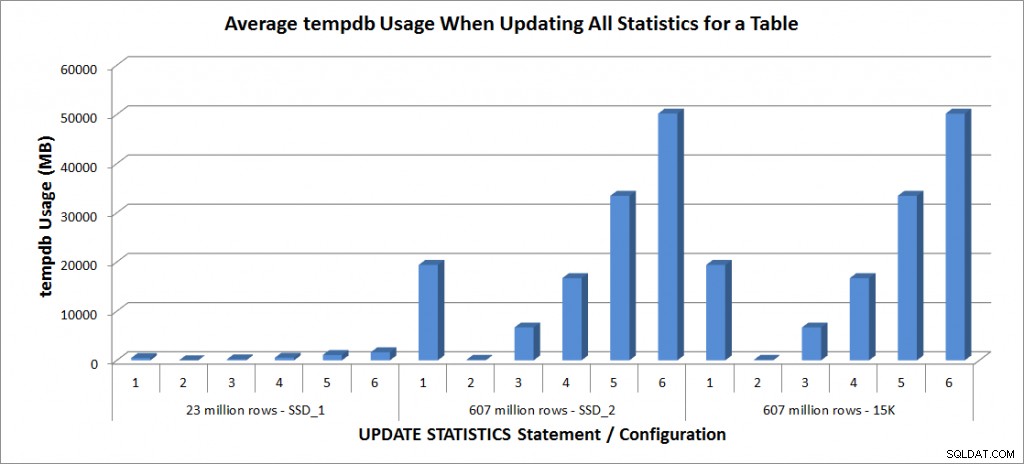
Utilisation de tempdb – Mettre à jour toutes les statistiques pour SalesOrderDetailEnlarged
Les durées de la table de 23 millions de lignes étaient toutes inférieures à trois minutes et sont décrites plus en détail dans la section suivante. Pour la table sur les disques SSD_2, l'instruction FULLSCAN a pris 1492 secondes (près de 25 minutes) et la mise à jour avec un échantillon de 25 % a pris 2051 secondes (plus de 34 minutes). En revanche, sur les disques 15K, l'instruction FULLSCAN a pris 2864 secondes (plus de 47 minutes) et la mise à jour avec un échantillon de 25 % a pris 2147 secondes (presque 36 minutes) – moins que le FULLSCAN. Cependant, la mise à jour avec un échantillon de 50 % a pris 4296 secondes (plus de 71 minutes).
L'utilisation de Tempdb est beaucoup plus cohérente, montrant une augmentation constante à mesure que la taille de l'échantillon augmente et utilisant plus d'espace tempdb qu'un FULLSCAN entre 25% et 50%. Ce qui est remarquable ici, c'est que UPDATE STATISTICS fait utiliser tempdb, dont il est important de se souvenir lorsque vous dimensionnez tempdb pour un environnement SQL Server. L'utilisation de Tempdb est mentionnée dans l'entrée UPDATE STATISTICS BOL :
UPDATE STATISTICS peut utiliser tempdb pour trier l'échantillon de lignes pour la construction de statistiques. »
Et l'effet est documenté dans le post de Linchi Shea, Performance impact:tempdb and update statistics. Cependant, ce n'est pas toujours mentionné lors des discussions sur le dimensionnement de tempdb. Si vous avez de grandes tables et effectuez des mises à jour avec FULLSCAN ou des valeurs d'échantillon élevées, soyez conscient de l'utilisation de tempdb.
Performance des mises à jour sélectives
J'ai ensuite décidé de tester les instructions UPDATE STATISTICS pour les autres statistiques de la table, mais j'ai limité mes tests à la copie de la table avec 23 millions de lignes. Les six variantes ci-dessus de l'instruction UPDATE STATISTICS ont été répétées quatre fois chacune pour les statistiques individuelles suivantes, puis comparées à la mise à jour pour l'ensemble du tableau :
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Tous les tests ont été exécutés avec la configuration susmentionnée sur mon ordinateur portable, et les résultats sont dans le graphique ci-dessous :
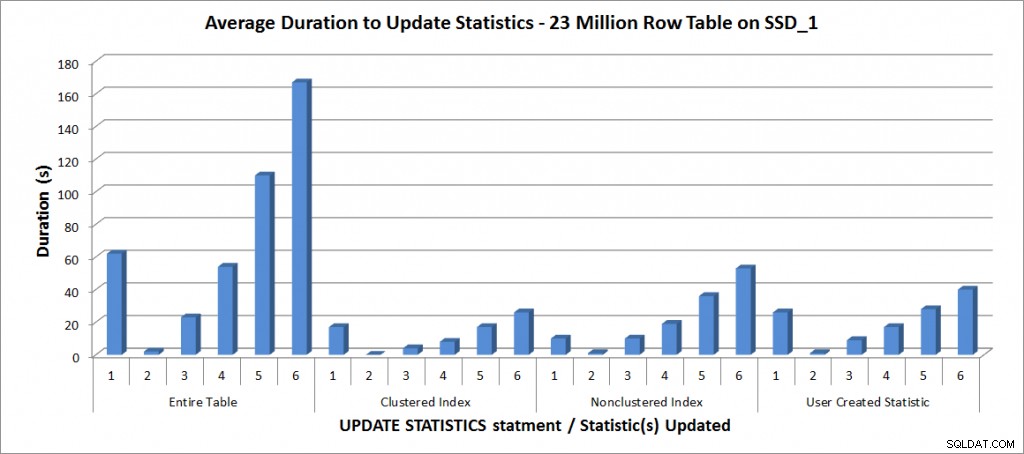
Durée moyenne pour UPDATE STATISTICS - Toutes les statistiques par rapport à celles sélectionnées
Comme prévu, les mises à jour d'une statistique individuelle ont pris moins de temps que lors de la mise à jour de toutes les statistiques du tableau. La valeur à laquelle la mise à jour échantillonnée a pris plus de temps qu'un FULLSCAN a varié :
| Instruction UPDATE | Durée(s) FULLSCAN | Première mise à jour qui a pris plus de temps |
|---|---|---|
| Table entière | 62 | 50 % - 110 secondes |
| Index clusterisé | 17 | 75 % – 26 secondes |
| Index non clusterisé | 10 | 25 % - 19 secondes |
| Statistique créée par l'utilisateur | 26 | 50 % - 28 secondes |
Conclusion
Sur la base de ces données et des données FULLSCAN des tables de 607 millions de lignes, il n'y a pas de données spécifiques point de basculement où une mise à jour échantillonnée prend plus de temps qu'un FULLSCAN ; ce point dépend de la taille de la table et des ressources disponibles. Mais les données sont toujours utiles car elles démontrent qu'il existe un point où une valeur échantillonnée peut prendre plus de temps à capturer qu'un FULLSCAN. Cela revient encore une fois à connaître vos données. Ceci est essentiel non seulement pour comprendre si une table nécessite une gestion personnalisée des statistiques, mais également pour comprendre la taille d'échantillon idéale pour créer un histogramme utile et également optimiser l'utilisation des ressources.
Spécifications
Spécifications de l'ordinateur portable :Dell M6500, 1 Intel i7 (2,13 GHz 4 cœurs et HT est activé donc 8 cœurs logiques), 32 Go de mémoire, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), fichiers de base de données stockés sur un SSD Samsung de 265 Go PM810Spécifications du serveur de test :Dell R720, 2 Intel E5-2670 (2,6 GHz 8 cœurs et HT est activé donc 16 cœurs logiques par socket), 64 Go de mémoire, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), fichiers de base de données pour une table se trouve sur deux cartes Fusion-io Duo MLC de 640 Go, les fichiers de base de données de l'autre table se trouvent sur neuf disques 15 000 tr/min dans une matrice RAID5