Plus tôt cette semaine, j'ai posté un suivi de mon récent article sur STRING_SPLIT() dans SQL Server 2016, répondant à plusieurs commentaires laissés sur la publication et/ou qui m'ont été envoyés directement :
STRING_SPLIT()dans SQL Server 2016 :Suivi #1
Après que ce message ait été en grande partie écrit, Doug Ellner a posé une question de dernière minute :
Comment ces fonctions se comparent-elles aux paramètres table ?
Maintenant, tester les TVP figurait déjà sur ma liste de futurs projets, après un récent échange sur Twitter avec @Nick_Craver sur Stack Overflow. Il a dit qu'ils étaient ravis que STRING_SPLIT() ont bien fonctionné, car ils n'étaient pas satisfaits des performances d'envoi d'environ 7 000 valeurs via un paramètre de table.
Mes tests
Pour ces tests, j'ai utilisé SQL Server 2016 RC3 (13.0.1400.361) sur une machine virtuelle Windows 10 à 8 cœurs, avec un stockage PCIe et 32 Go de RAM.
J'ai créé une table simple qui imitait ce qu'ils faisaient (en sélectionnant environ 10 000 valeurs dans une table de plus de 3 millions de lignes), mais pour mes tests, elle a beaucoup moins de colonnes et moins d'index :
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ;
J'ai également créé une version In-Memory, car j'étais curieux de savoir si une approche fonctionnerait différemment ici :
CREATE TABLE dbo.Posts_InMemory( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) WITH (MEMORY_OPTIMIZED =ON);
Maintenant, je voulais créer une application C # qui transmettrait 10 000 valeurs uniques, soit sous forme de chaîne séparée par des virgules (construite à l'aide d'un StringBuilder), soit sous forme de TVP (passée à partir d'un DataTable). Le but serait de récupérer ou de mettre à jour une sélection de lignes en fonction d'une correspondance, soit vers un élément produit en divisant la liste, soit vers une valeur explicite dans un TVP. Le code a donc été écrit pour ajouter chaque 300e valeur à la chaîne ou au DataTable (le code C # se trouve dans une annexe ci-dessous). J'ai pris les fonctions que j'ai créées dans le message d'origine, les ai modifiées pour gérer varchar(max) , puis ajouté deux fonctions acceptant un TVP, dont une optimisée en mémoire. Voici les types de tableaux (les fonctions sont en annexe ci-dessous) :
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE(PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =1000000)) WITH (MEMORY_OPTIMIZED =ON);GOJ'ai également dû agrandir la table Numbers afin de gérer les chaînes> 8K et avec> 8K éléments (je l'ai fait en lignes de 1MM). Ensuite, j'ai créé sept procédures stockées :cinq d'entre elles prenant un
varchar(max)et se joindre à la sortie de la fonction afin de mettre à jour la table de base, puis deux pour accepter le TVP et se joindre directement à cela. Le code C# appelle chacune de ces sept procédures, avec la liste des 10 000 publications à sélectionner ou mettre à jour, 1 000 fois. Ces procédures sont également en annexe ci-dessous. Donc, juste pour résumer, les méthodes testées sont :
- Natif (
STRING_SPLIT()) - XML
- CLR
- Tableau des nombres
- JSON (avec
intexplicite sortie) - Paramètre table
- Paramètre table à mémoire optimisée
Nous testerons la récupération des 10 000 valeurs, 1 000 fois, à l'aide d'un DataReader - mais sans itérer sur le DataReader, car cela ne ferait que rendre le test plus long et représenterait la même quantité de travail pour l'application C # quelle que soit la façon dont la base de données produit l'ensemble. Nous testerons également la mise à jour des 10 000 lignes, 1 000 fois chacune, à l'aide de ExecuteNonQuery() . Et nous testerons à la fois les versions régulières et optimisées en mémoire de la table Posts, que nous pouvons basculer très facilement sans avoir à modifier aucune des fonctions ou procédures, en utilisant un synonyme :
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular ; -- pour tester la version optimisée en mémoire :DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- pour tester à nouveau la version sur disque :DROP SYNONYM dbo.Posts ;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular ;
J'ai lancé l'application, l'ai exécutée plusieurs fois pour chaque combinaison pour m'assurer que la compilation, la mise en cache et d'autres facteurs n'étaient pas injustes pour le lot exécuté en premier, puis j'ai analysé les résultats de la table de journalisation (j'ai également vérifié ponctuellement sys. dm_exec_procedure_stats pour s'assurer qu'aucune des approches n'avait de surcharge importante basée sur les applications, et ce n'était pas le cas).
Résultats – Tables sur disque
J'ai parfois du mal avec la visualisation des données - j'ai vraiment essayé de trouver un moyen de représenter ces mesures sur un seul graphique, mais je pense qu'il y avait beaucoup trop de points de données pour faire ressortir les points saillants.
Vous pouvez cliquer pour agrandir n'importe lequel d'entre eux dans un nouvel onglet/fenêtre, mais même si vous avez une petite fenêtre, j'ai essayé de rendre le gagnant clair grâce à l'utilisation de la couleur (et le gagnant était le même dans tous les cas). Et pour être clair, par "durée moyenne", j'entends le temps moyen qu'il a fallu à l'application pour effectuer une boucle de 1 000 opérations.
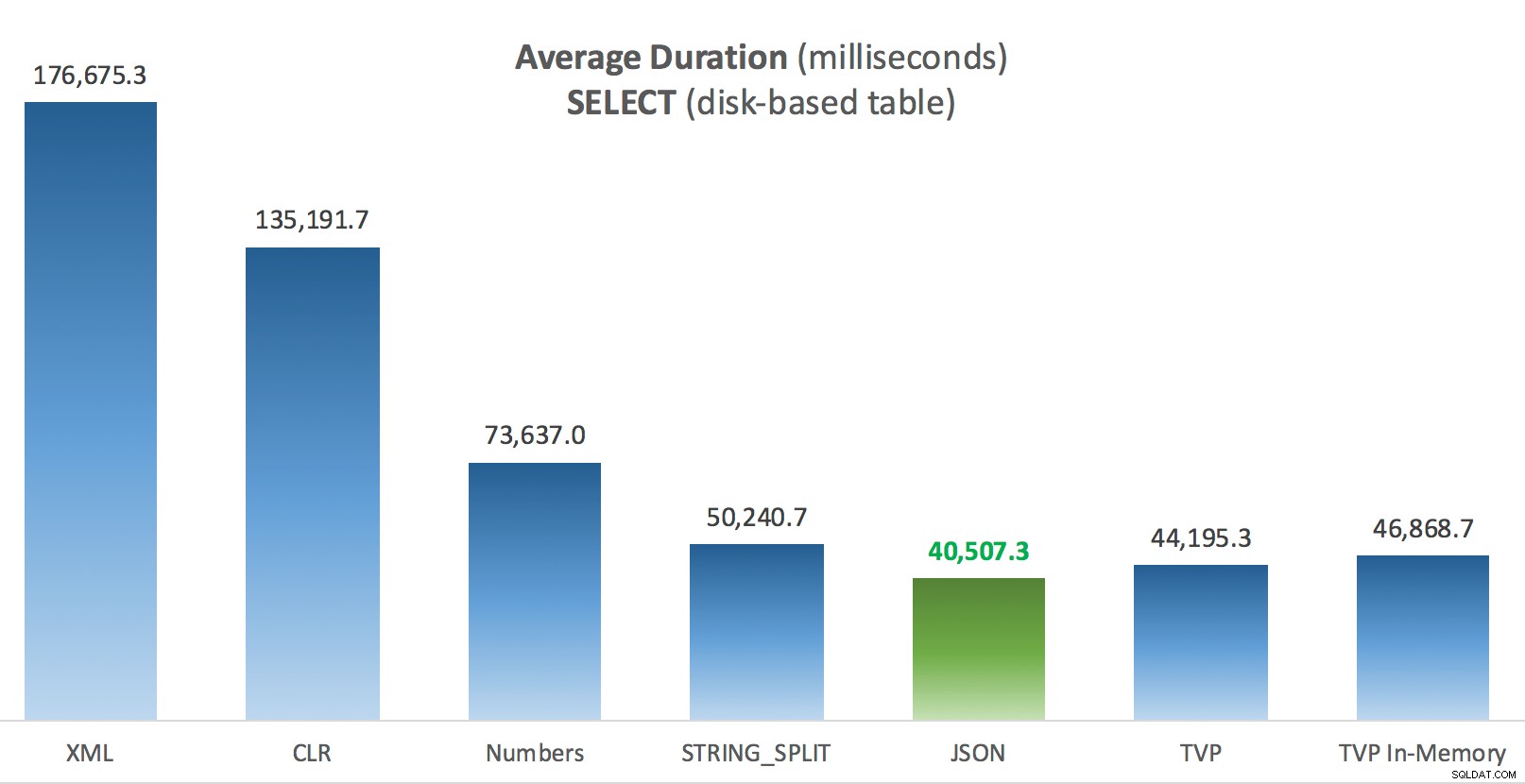 Durée moyenne (millisecondes) des SELECTs par rapport au tableau des messages sur disque
Durée moyenne (millisecondes) des SELECTs par rapport au tableau des messages sur disque
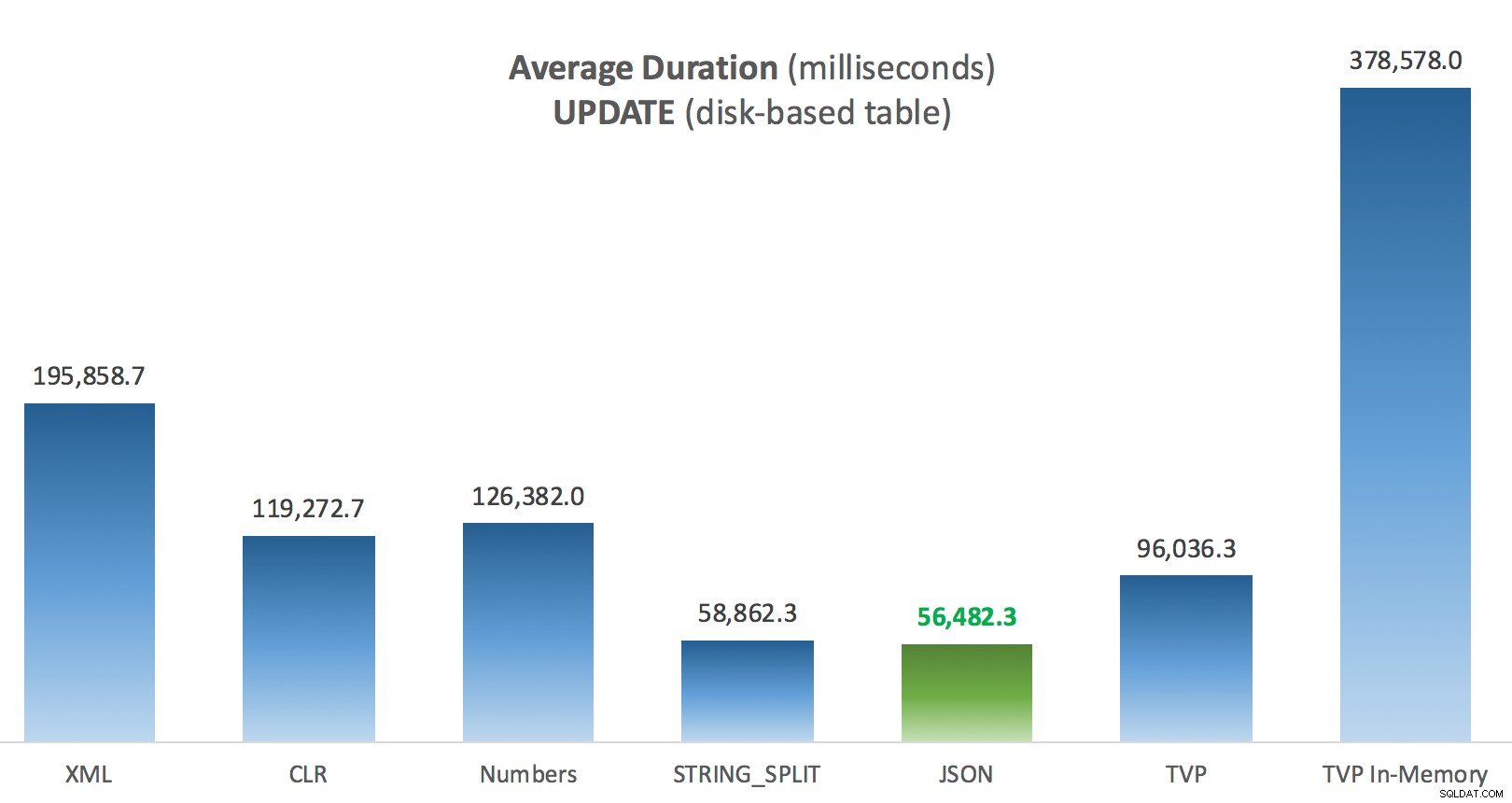 Durée moyenne (millisecondes) des mises à jour par rapport au tableau des publications sur disque
Durée moyenne (millisecondes) des mises à jour par rapport au tableau des publications sur disque
La chose la plus intéressante ici, pour moi, c'est à quel point le TVP à mémoire optimisée s'est comporté lors d'une UPDATE . Il s'avère que les analyses parallèles sont actuellement bloquées de manière trop agressive lorsque DML est impliqué ; Microsoft a reconnu cela comme une lacune dans les fonctionnalités et espère y remédier bientôt. Notez que l'analyse parallèle est actuellement possible avec SELECT mais il est bloqué pour DML en ce moment. (Il ne sera pas résolu dans SQL Server 2014, car ces opérations d'analyse parallèle spécifiques n'y sont disponibles pour aucune opération.) Lorsque cela est corrigé, ou lorsque vos TVP sont plus petits et/ou que le parallélisme n'est de toute façon pas avantageux, vous devriez voir que les TVP à mémoire optimisée fonctionneront mieux (le modèle ne fonctionne tout simplement pas bien pour ce cas d'utilisation particulier de TVP relativement volumineux).
Pour ce cas précis, voici les plans pour le SELECT (que je pourrais contraindre à aller en parallèle) et le UPDATE (ce que je n'ai pas pu) :
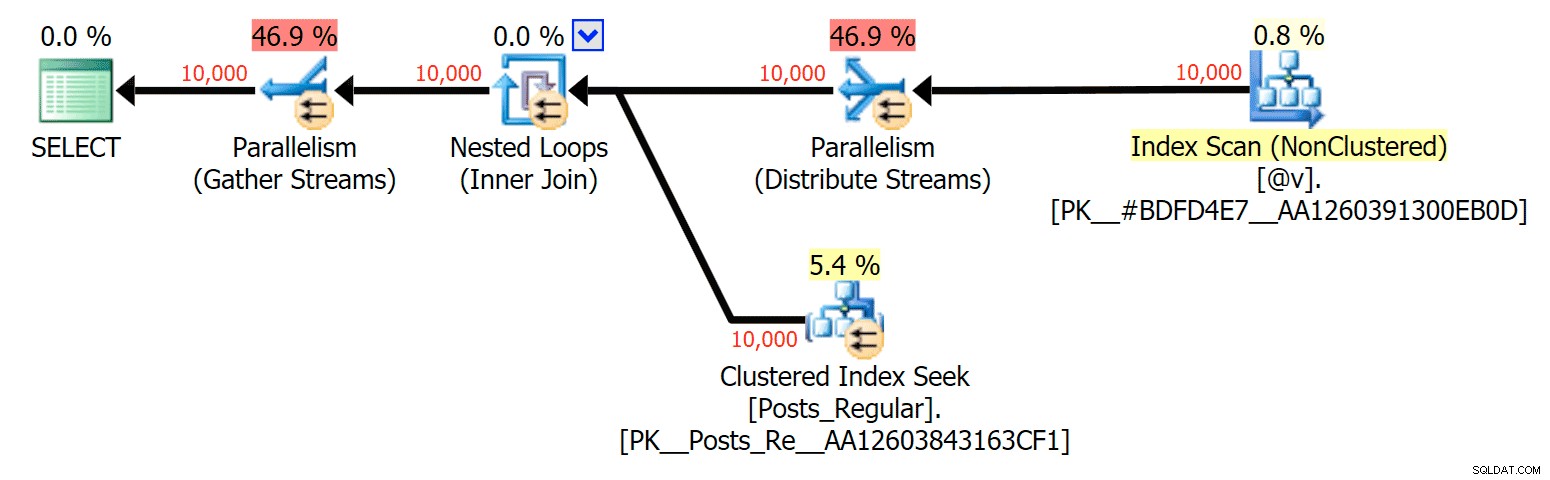 Parallélisme dans un plan SELECT joignant une table sur disque à un TVP en mémoire
Parallélisme dans un plan SELECT joignant une table sur disque à un TVP en mémoire
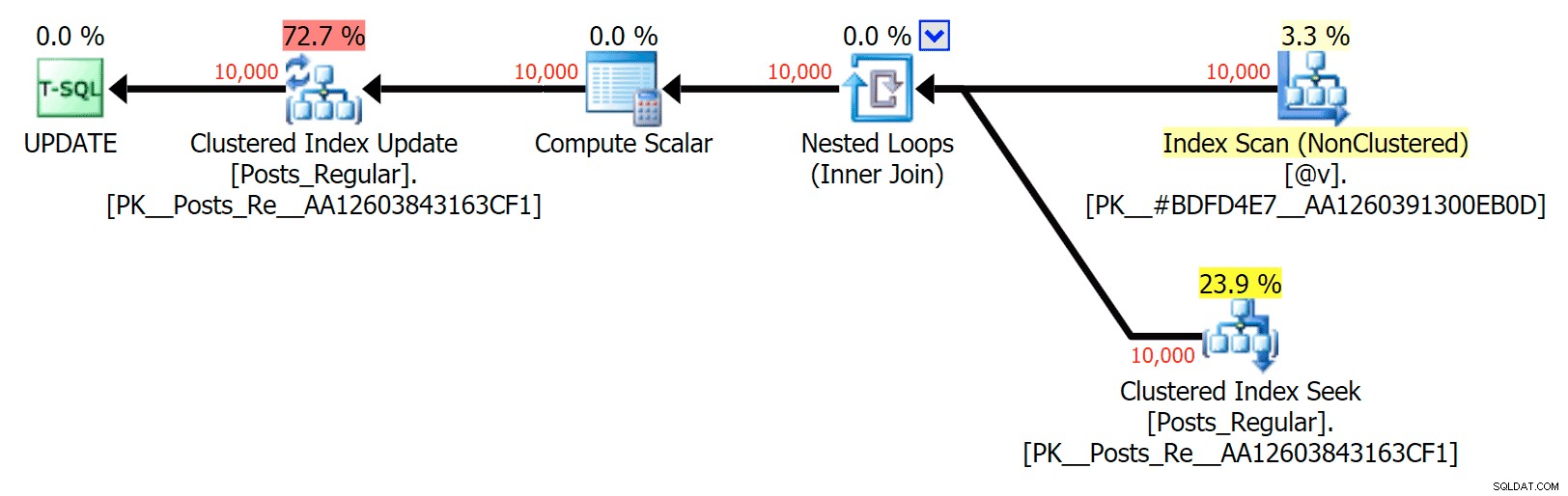 Aucun parallélisme dans un plan UPDATE joignant une table sur disque à une table en mémoire TVP
Aucun parallélisme dans un plan UPDATE joignant une table sur disque à une table en mémoire TVP
Résultats – Tableaux à mémoire optimisée
Un peu plus de cohérence ici – les quatre méthodes de droite sont relativement égales, tandis que les trois de gauche semblent très indésirables par contraste. Portez également une attention particulière à l'échelle absolue par rapport aux tables sur disque - pour la plupart, en utilisant les mêmes méthodes, et même sans parallélisme, vous vous retrouvez avec des opérations beaucoup plus rapides sur les tables optimisées en mémoire, ce qui réduit l'utilisation globale du processeur.
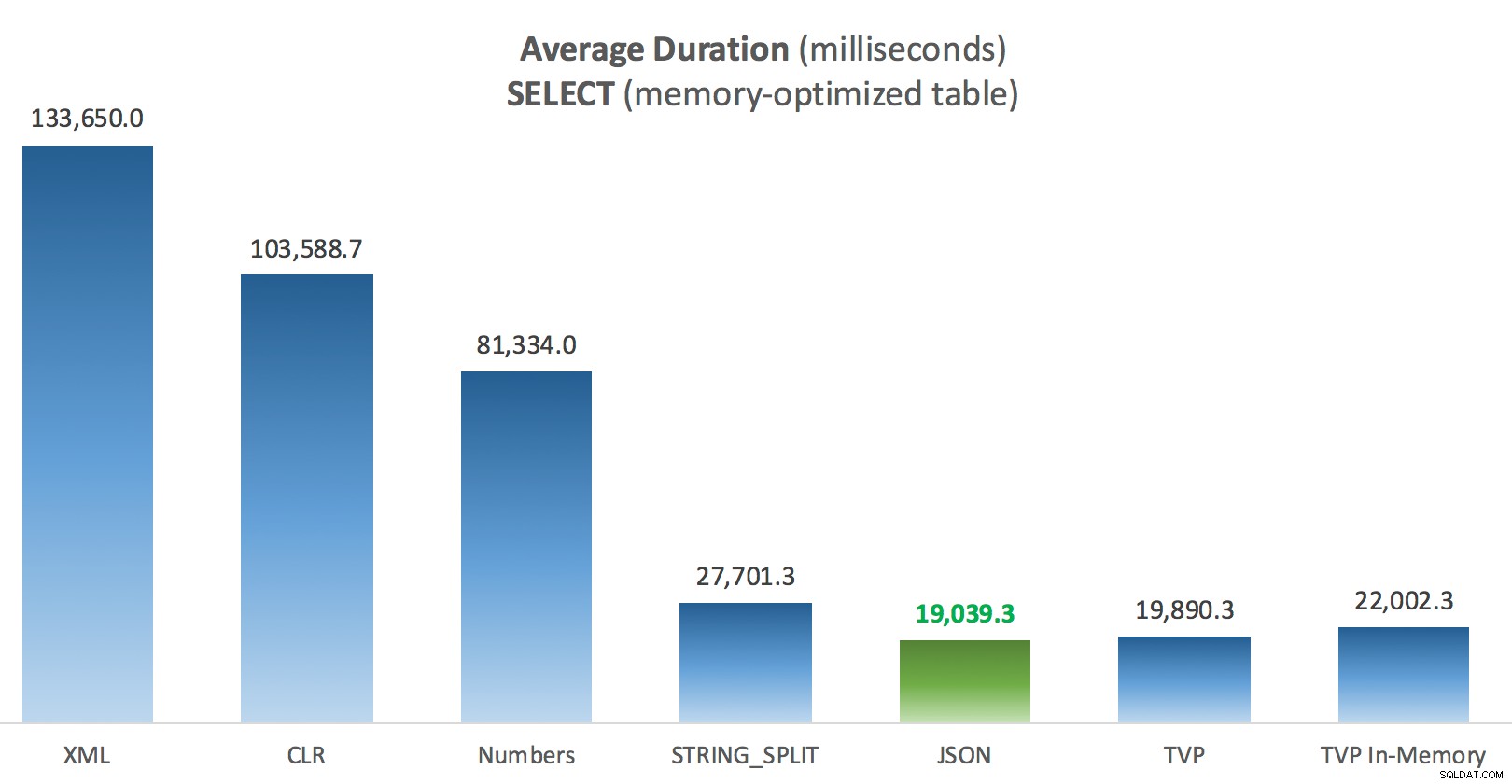 Durée moyenne (millisecondes) des SELECTs par rapport au tableau Posts à mémoire optimisée
Durée moyenne (millisecondes) des SELECTs par rapport au tableau Posts à mémoire optimisée
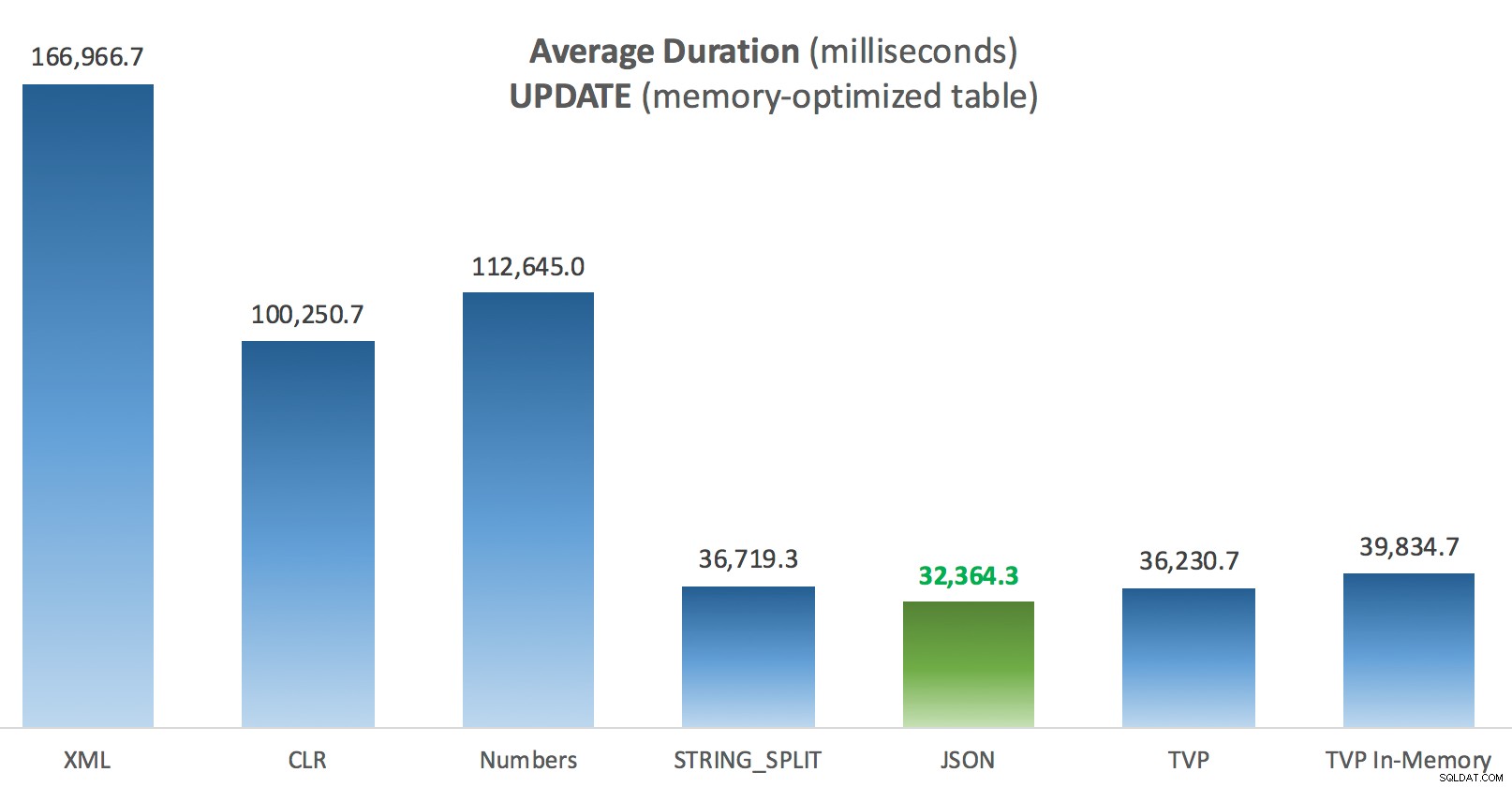 Durée moyenne (millisecondes) des mises à jour par rapport au tableau des publications optimisées en mémoire
Durée moyenne (millisecondes) des mises à jour par rapport au tableau des publications optimisées en mémoire
Conclusion
Pour ce test spécifique, avec une taille de données, une distribution et un nombre de paramètres spécifiques, et sur mon matériel particulier, JSON a été un gagnant constant (bien que marginal). Pour certains des autres tests dans les articles précédents, cependant, d'autres approches se sont mieux comportées. Juste un exemple de la façon dont ce que vous faites et où vous le faites peut avoir un impact dramatique sur l'efficacité relative de diverses techniques, voici les choses que j'ai testées dans cette brève série, avec mon résumé de la technique à utiliser utiliser dans ce cas, et lequel utiliser comme 2e ou 3e choix (par exemple, si vous ne pouvez pas implémenter le CLR en raison de la politique de l'entreprise ou parce que vous utilisez Azure SQL Database, ou si vous ne pouvez pas utiliser JSON ou STRING_SPLIT() car vous n'êtes pas encore sur SQL Server 2016). Notez que je ne suis pas revenu en arrière et n'ai pas retesté l'affectation de variable et SELECT INTO scripts utilisant des TVP - ces tests ont été configurés en supposant que vous disposiez déjà de données existantes au format CSV qui devraient de toute façon être décomposées en premier. Généralement, si vous pouvez l'éviter, ne mélangez pas vos ensembles en chaînes séparées par des virgules en premier lieu, à mon humble avis.
| Objectif | 1er choix | 2e choix (et 3e, le cas échéant) |
|---|---|---|
| Affectation de variable simple | STRING_SPLIT() | CLR si <2016 XML si pas de CLR et <2016 |
| SÉLECTIONNER DANS | CLR | XML si pas de CLR |
| SELECT INTO (pas de bobine) | CLR | Table des nombres si pas de CLR |
| SELECT INTO (pas de spool + MAXDOP 1) | STRING_SPLIT() | CLR si <2016 Tableau des nombres si pas de CLR et <2016 |
| SELECT rejoint une grande liste (sur disque) | JSON (entier) | TVP si <2016 |
| SELECT rejoint une grande liste (mémoire optimisée) | JSON (entier) | TVP si <2016 |
| UPDATE rejoignant une grande liste (sur disque) | JSON (entier) | TVP si <2016 |
| UPDATE rejoignant une grande liste (mémoire optimisée) | JSON (entier) | TVP si <2016 |
Pour la question spécifique de Doug :JSON, STRING_SPLIT() , et les TVP ont obtenu des résultats assez similaires dans ces tests en moyenne - suffisamment proches pour que les TVP soient le choix évident si vous n'êtes pas sur SQL Server 2016. Si vous avez des cas d'utilisation différents, ces résultats peuvent différer. Grandement .
Ce qui nous amène à la morale de ceci histoire :moi et d'autres pouvons effectuer des tests de performances très spécifiques, portant sur n'importe quelle fonctionnalité ou approche, et arriver à une conclusion sur l'approche la plus rapide. Mais il y a tellement de variables que je n'aurai jamais la confiance nécessaire pour dire "cette approche est toujours le plus rapide." Dans ce scénario, j'ai essayé très fort de contrôler la plupart des facteurs contributifs, et bien que JSON ait gagné dans les quatre cas, vous pouvez voir comment ces différents facteurs ont affecté les temps d'exécution (et de manière drastique pour certaines approches). cela vaut toujours la peine de construire vos propres tests, et j'espère avoir aidé à illustrer comment je m'y prends.
Annexe A :Code d'application de la console
S'il vous plaît, pas de pinaillerie à propos de ce code ; il a été littéralement jeté ensemble comme un moyen très simple d'exécuter ces procédures stockées 1 000 fois avec de vraies listes et des DataTables assemblés en C #, et d'enregistrer le temps que chaque boucle a pris à une table (pour être sûr d'inclure toute surcharge liée à l'application avec la gestion soit une grande chaîne ou une collection). Je pourrais ajouter la gestion des erreurs, boucler différemment (par exemple, construire les listes à l'intérieur de la boucle au lieu de réutiliser une seule unité de travail), etc.
utilisation de System ;utilisation de System.Text ;utilisation de System.Configuration ;utilisation de System.Data ;utilisation de System.Data.SqlClient ; namespace SplitTesting{ class Program { static void Main(string[] args) { string operation ="Update"; if (args[0].ToString() =="-Select") { opération ="Select" ; } var csv =new StringBuilder(); Éléments DataTable =new DataTable(); elements.Columns.Add("value", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elements.Rows.Add(i*300); } méthodes de chaîne [] ={ "Natif", "CLR", "XML", "Numéros", "JSON", "TVP", "TVP_InMemory" } ; using (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primary"].ToString(); con.Open(); SqlParamètre p ; foreach (méthode de chaîne dans les méthodes) { SqlCommand cmd =new SqlCommand("dbo." + opération + "Posts_" + méthode, con); cmd.CommandType =CommandType.StoredProcedure ; if (method =="TVP" || method =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =elements; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operation =="Update") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Close(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds ; // enregistrement de l'heure - la procédure d'enregistrement ajoute l'heure d'horloge et // enregistre la mémoire/le disque (déterminé via un synonyme) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure ; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value =opération ; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =method; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(method + " :" + this_time.ToString()); } } } }} Exemple d'utilisation :
SplitTesting.exe -SélectionnerSplitTesting.exe -Mettre à jour
Annexe B :Fonctions, procédures et tableau de journalisation
Voici les fonctions modifiées pour prendre en charge varchar(max) (la fonction CLR acceptait déjà nvarchar(max) et j'hésitais encore à essayer de le changer):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));GO CREATE FUNCTION dbo.SplitStrings_XML ( @List varchar(max), @Delimiter char(1))RETOURS TABLE AVEC SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') FROM (SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] =SUBSTRING (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) FROM dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCH EMABINDINGAS RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));GO Et les procédures stockées ressemblaient à ceci :
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [valeur];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s.[value];ENDGO-- répéter pour les 4 autres méthodes basées sur varchar(max) CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- passer de _Regular à _InMemoryASBEGIN SET NOCOUNT ON; UPDATE p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory ASBEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- répéter pour en mémoire
Et enfin, la table et la procédure de journalisation :
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory ou Posts_Regular Operation varchar(32) NOT NULL DEFAULT 'Mise à jour', -- ou sélectionnez Méthode varchar(32) NOT NULL DEFAULT 'Native', -- ou TVP, JSON, etc. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN SET NOCOUNT ON ; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- et la requête pour générer les graphiques :;WITH x AS( SELECT OperatingTable,Operation,Method,Timing, Recency =ROW_NUMBER() OVER (PARTITION BY OperatingTable,Operation,Method ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable,Operation,Method,AverageDuration =AVG(1.0*Timing) FROM x WHERE Récence <=3GROUP BY OperatingTable,Operation,Method;