Dans ce blog, nous vous fournirons l'introduction complète de Hadoop Mapper . Je
Dans ce blog, nous répondrons à ce qu'est Mapper dans Hadoop MapReduce, comment fonctionne Hadoop Mapper, quel est le processus de mapper dans Mapreduce, comment Hadoop génère une paire clé-valeur dans MapReduce.
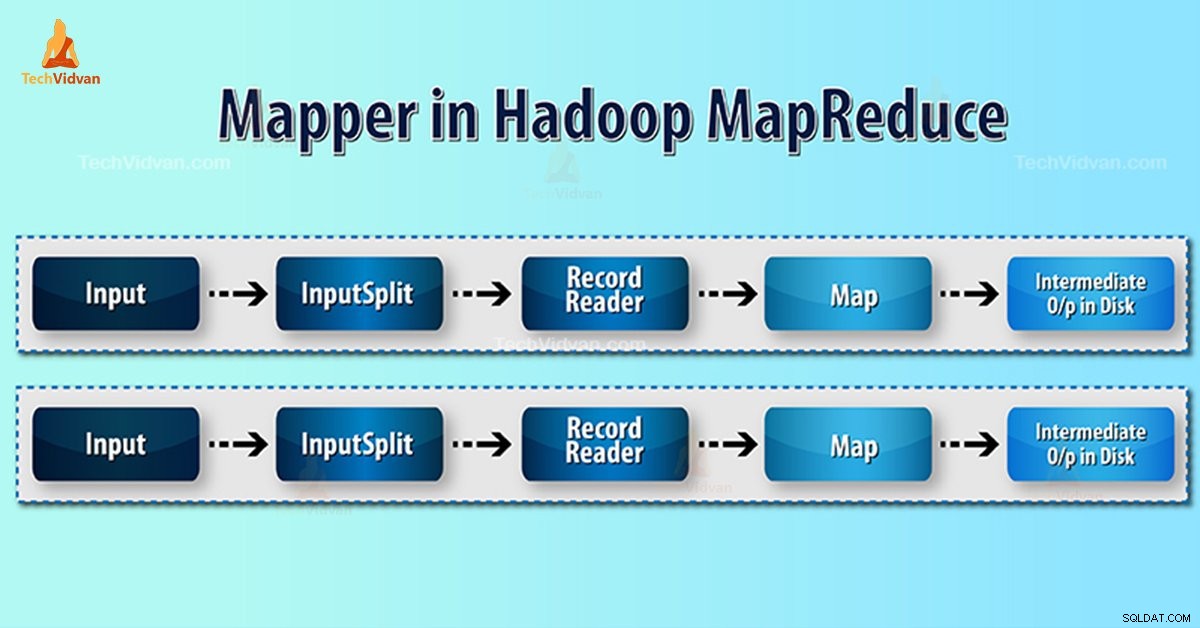
Introduction au mappeur Hadoop
Mappeur Hadoop traite l'enregistrement d'entrée produit par le RecordReader et génère des paires clé-valeur intermédiaires. La sortie intermédiaire est complètement différente de la paire d'entrée.
La sortie du mappeur est la collection complète de paires clé-valeur. Avant d'écrire la sortie pour chaque tâche de mappeur, le partitionnement de la sortie a lieu sur la base de la clé. Ainsi, le partitionnement indique que toutes les valeurs de chaque clé sont regroupées.
Hadoop MapReduce génère une tâche de carte pour chaque InputSplit.
Hadoop MapReduce ne comprend que les paires clé-valeur de données. Ainsi, avant d'envoyer des données au mappeur, le framework Hadoop doit dissimuler les données dans la paire clé-valeur.
Comment la paire clé-valeur est-elle générée dans Hadoop ?
Comme nous avons compris ce qu'est le mappeur dans hadoop, nous allons maintenant discuter de la manière dont Hadoop génère une paire clé-valeur ?
- InputSplit – C'est la représentation logique des données générées par InputFormat. Dans le programme MapReduce, il décrit une unité de travail qui contient une seule tâche cartographique.
- RecordReader- Il communique avec l'inputSplit. Et convertit ensuite les données en paires clé-valeur adaptées à la lecture par le mappeur. RecordReader utilise par défaut TextInputFormat pour convertir les données dans la paire clé-valeur.
Processus de mappage dans Hadoop MapReduce
InputSplit convertit la représentation physique des blocs en logique pour le mappeur. Par exemple, pour lire le fichier de 100 Mo, il faudra 2 InputSplit. Pour chaque bloc, le framework crée un InputSplit. Chaque InputSplit crée un mappeur.
MapReduce InputSplit ne dépend pas toujours du nombre de blocs de données . Nous pouvons modifier le nombre d'un fractionnement en définissant la propriété mapred.max.split.size pendant l'exécution du travail.
MapReduce RecordReader est responsable de la lecture/conversion des données en paires clé-valeur jusqu'à la fin du fichier. RecordReader attribue un décalage d'octet à chaque ligne présente dans le fichier.
Ensuite Mapper reçoit cette paire de clés. Mapper produit la sortie intermédiaire (paires clé-valeur qu'il est compréhensible de réduire).
Combien de tâches Map dans Hadoop ?
Le nombre de tâches cartographiques dépend du nombre total de blocs des fichiers d'entrée. Dans la carte MapReduce, le bon niveau de parallélisme semble être d'environ 10 à 100 cartes/nœud. Mais il y a 300 cartes pour les tâches de carte CPU-light.
Par exemple, nous avons une taille de bloc de 128 Mo. Et nous attendons 10 To de données d'entrée. Ainsi, il produit 82 000 cartes. Par conséquent, le nombre de cartes dépend de InputFormat.
Mappeur =(taille totale des données)/ (taille de la répartition des entrées)
Exemple – la taille des données est de 1 To. La taille du partage d'entrée est de 100 Mo.
Cartographe =(1000*1000)/100 =10 000
Conclusion
Par conséquent, Mapper dans Hadoop prend un ensemble de données et le convertit en un autre ensemble de données. Ainsi, il divise les éléments individuels en tuples (paires clé/valeur).
J'espère que vous aimez ce bloc, si vous avez des questions sur le mappeur Hadoop, veuillez donc laisser un commentaire dans une section ci-dessous. Nous serons heureux de les résoudre.



