Dans ce tutoriel Hadoop , nous allons vous fournir une introduction complète de HDFS Federation. Dans ce didacticiel, nous discuterons de l'architecture HDFS, des limites de l'architecture actuelle de HDFS.
Ensuite, nous couvrirons en détail l'architecture de la fédération HDFS ainsi que leurs avantages dans le cadre Hadoop.
Qu'est-ce que la fédération HDFS ?
Fédération améliore un Hadoop HDFS existant architecture. L'architecture HDFS précédente permet un espace de noms unique pour l'ensemble du cluster. Dans cette architecture, un seul NameNode gère l'espace de noms.
Si NameNode échoue, tout le cluster sera hors service. Et le cluster sera indisponible jusqu'à ce que le NameNode redémarre ou soit amené sur une machine séparée.
La fédération HDFS a été introduite pour surmonter cette limitation. Il surmonte cela en ajoutant la prise en charge de nombreux NameNode/Namespaces à HDFS.
Architecture HDFS actuelle
HDFS a deux couches principales indiquées ci-dessous :
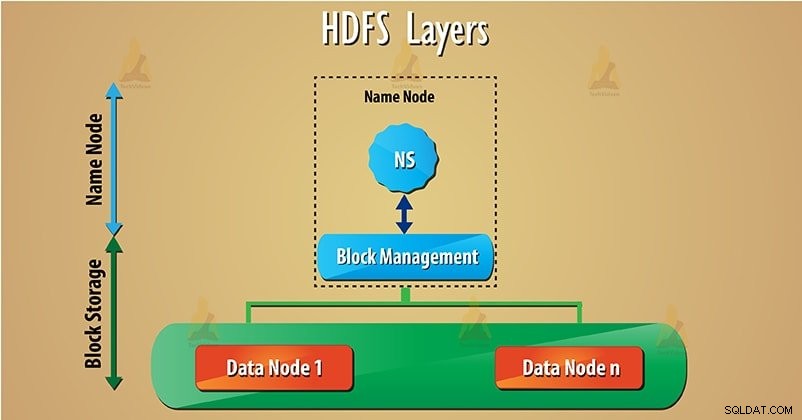
a) Espace de noms – Cette couche gère les fichiers, les répertoires et les blocs . Cette couche prend en charge les opérations de base du système de fichiers telles que la création et la suppression de fichiers.
b) Stockage de blocs – Il comporte deux parties-
- Gestion des blocs – Il prend en charge les opérations liées aux blocs telles que la création, la suppression des blocs. Il gère les nœuds de données dans le cluster et s'occupe de la gestion de la réplication.
- Stockage physique : Cela stocke les blocs sur le système de fichiers local et permet d'accéder aux opérations de lecture ou d'écriture. Suivez ce lien pour découvrir les opérations de lecture et d'écriture des données HDFS.
Ce HDFS actuel fonctionne bien pour les petites configurations. Mais, pour les grandes organisations où nous devons nous occuper de l'énorme quantité de données, il y a certaines limites. La fédération Hadoop gère ces limitations.
Limitation de l'architecture HDFS actuelle
Les limites de l'architecture HDFS actuelle sont indiquées ci-dessous :
1. Stockage de blocs et espace de noms étroitement couplés
Couche d'espace de noms et couche de stockage sont étroitement couplés. Cela rend difficile la mise en œuvre alternative de namenode. Et cela empêche d'autres services d'utiliser le stockage en mode bloc.
2. Évolutivité de l'espace de noms
L'espace de noms n'est pas évolutif comme datanode. La mise à l'échelle dans le cluster HDFS s'effectue horizontalement en ajoutant des nœuds de données. Mais nous ne pouvons pas ajouter plus d'espace de noms à un cluster existant. Nous pouvons mettre à l'échelle verticalement l'espace de noms sur un seul nœud de nom.
3. Performances
L'ensemble des performances de Hadoop dépend du débit du namenode. Une opération du système de fichiers actuel dépend du débit d'un seul namenode. NameNode prend actuellement en charge 60 000 tâches simultanées.
À venir MapReduce prendra en charge plus de 1 00 000 tâches simultanées. Et cela nécessitera plus de namenode.
4. Isolement
Il n'y a pas de séparation de l'espace de noms. Il n'y a donc pas d'isolement entre les organisations locataires qui utilisent le cluster.
HDFS architecture de fédération
La fédération utilise de nombreux Namenodes/espaces de noms indépendants pour mettre à l'échelle horizontalement le service de noms. Dans l'architecture de fédération HDFS, en bas, les nœuds de données sont présents. Et les datanodes sont utilisés comme stockage commun pour les blocs par tous les namenodes.
Chaque nœud de données s'enregistre auprès de tous les nœuds de nom du cluster. Ces nœuds de données envoient des pulsations périodiques, bloquent, signalent et gèrent les commandes des nœuds de nom.
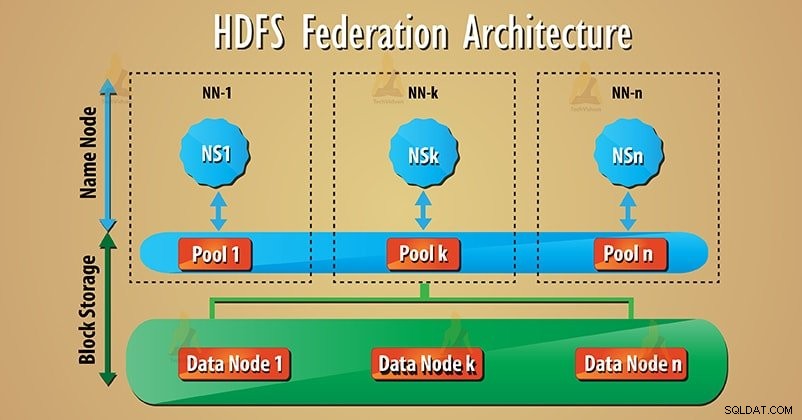
De nombreux namenodes (NN1, NN2…, NNn) gèrent respectivement de nombreux espaces de noms (NS1, NS2…, NSn). Chaque espace de noms a son propre pool de blocs (NS1 a le pool 1, etc.). Le bloc du pool 1 est stocké sur le datanode 1 et ainsi de suite.
1. Groupe de blocs
L'ensemble de blocs est Groupe de blocs qui appartient à un seul espace de noms. Il existe une collection de pools dans l'architecture de fédération HDFS. Et chaque bloc est géré depuis l'autre.
Cela permet à un espace de noms de créer un ID de bloc pour les nouveaux blocs sans coordination avec un autre espace de noms. Tous les Datanodes stockent les blocs de données présents dans tous les pools de blocs.
2. Volume d'espace de noms
L'espace de noms avec son pool de blocs correspond au volume d'espace de noms . De nombreux volumes d'espace de noms sont présents dans la fédération HDFS. Par conséquent, chaque volume d'espace de noms fonctionne indépendamment. Lorsque nous supprimons un namenode ou un namespace, le pool de blocs correspondant présent sur les datanodes sera également supprimé.
Avantages de la fédération HDFS
La fédération HDFS surmonte les limitations de l'architecture HDFS précédente. Il fournit donc :
- Isolement – Il n'y a pas d'isolation dans un seul namenode dans un environnement multi-utilisateurs. Dans la fédération HDFS, différentes catégories d'applications et d'utilisateurs peuvent être isolées dans différents espaces de noms en utilisant de nombreux nœuds de noms.
- Évolutivité de l'espace de noms : Dans la fédération, de nombreux nœuds de noms évoluent horizontalement dans l'espace de noms du système de fichiers.
- Performances – Nous pouvons améliorer le débit des opérations de lecture/écriture en ajoutant plus de namenodes.
Conclusion
En conclusion de la fédération HDFS, nous pouvons dire qu'elle surmonte la limitation de l'architecture HDFS à nœud unique. Dans l'architecture HDFS précédente, un cluster entier n'autorisait qu'un seul espace de noms. Tandis que la Fédération utilise de nombreux Namenodes/espaces de noms indépendants pour redimensionner horizontalement le service de noms.
Il sépare également la couche d'espace de noms et le stockage couche. Fournit donc isolation, évolutivité et conception simple.
Si vous avez des questions ou des suggestions concernant la Fédération dans Hadoop HDFS, faites-le nous savoir en laissant un commentaire.



