Dans notre précédentHadoop blogs, nous avons étudié chaque composant du Hadoop Processus MapReduce en détail. Dans ce document, nous allons discuter du sujet très intéressant, à savoir le travail Map Only dans Hadoop.
Tout d'abord, nous allons faire une brève introduction de la Carte et Réduire phase dans Hadoop Mapreduce, puis nous discuterons de ce qu'est la tâche Map only dans Hadoop MapReduce.
Enfin, nous discuterons également des avantages et des inconvénients du travail Hadoop Map Only dans ce didacticiel.
Qu'est-ce qu'une tâche Hadoop Map Only ?
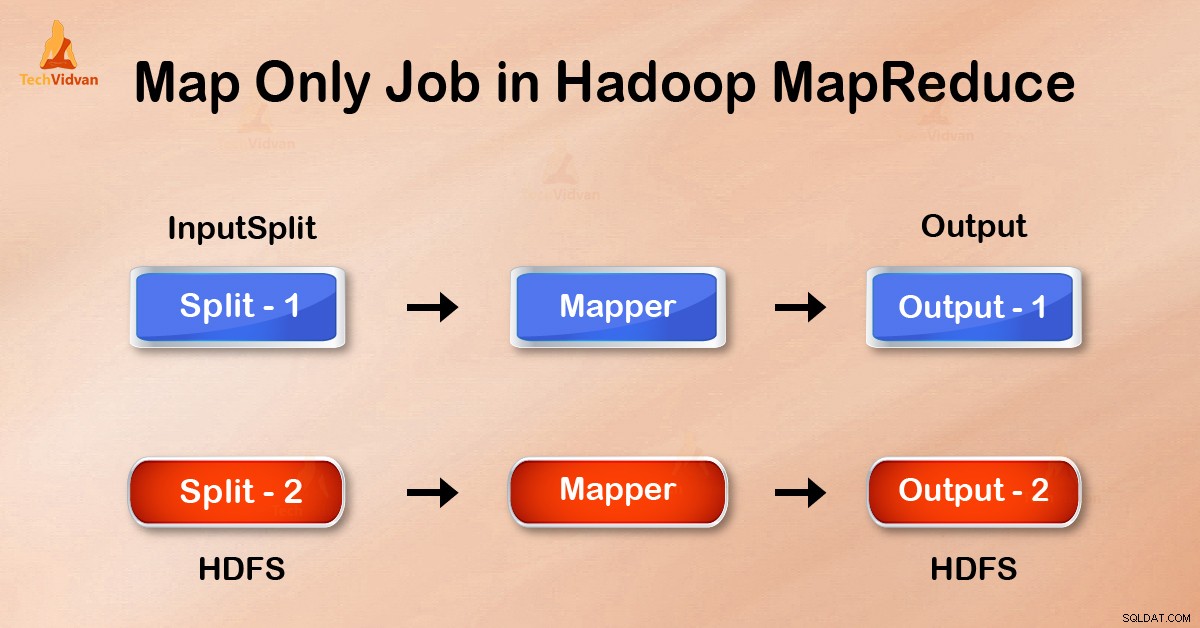
Tâche Map-Only dans Hadoop est le processus dans lequel mapper fait toutes les tâches. Aucune tâche n'est effectuée par le réducteur . La sortie de Mapper est la sortie finale.
MapReduce est la couche de traitement des données de Hadoop. Il traite de grandes données structurées et non structurées stockées dans HDFS . MapReduce traite également une énorme quantité de données en parallèle.
Pour ce faire, il divise le travail (travail soumis) en un ensemble de tâches indépendantes (sous-travail). Dans Hadoop, MapReduce fonctionne en divisant le traitement en phases :Map et Réduire .
- Carte : C'est la première phase du traitement, où nous spécifions tout le code logique complexe. Il prend un ensemble de données et le convertit en un autre ensemble de données. Il divise chaque élément individuel en tuples (paires clé-valeur ).
- Réduire : C'est la deuxième phase du traitement. Ici, nous spécifions un traitement léger comme l'agrégation/la sommation. Il prend la sortie de la carte en entrée. Ensuite, il combine ces tuples en fonction de la clé.
À partir de cet exemple de nombre de mots, nous pouvons dire qu'il existe deux ensembles de processus parallèles, mapper et réduire. Dans le processus de mappage, la première entrée est divisée pour répartir le travail entre tous les nœuds de la carte, comme indiqué ci-dessus.
Ensuite, le framework identifie chaque mot et le mappe au numéro 1. Ainsi, il crée des paires appelées paires de tuples (clé-valeur).
Dans le premier nœud de mappeur, il passe trois mots lion, tigre et rivière. Ainsi, il produit 3 paires clé-valeur en sortie du nœud. Trois clés différentes et une valeur définie sur 1 et le même processus se répètent pour tous les nœuds.
Ensuite, il transmet ces tuples aux nœuds réducteurs. Le partitionneur effectue le remaniement de sorte que tous les tuples avec la même clé vont au même nœud.
Dans le processus de réduction, ce qui se passe essentiellement est une agrégation de valeurs ou plutôt une opération sur des valeurs qui partagent la même clé.
Maintenant, considérons un scénario où nous avons juste besoin d'effectuer l'opération. Nous n'avons pas besoin d'agrégation, dans ce cas, nous préférerons 'Map-Only job '.
Dans le travail Map-Only, la carte effectue toutes les tâches avec son InputSplit . Le réducteur ne fait aucun travail. La sortie des mappeurs est la sortie finale.
Comment éviter la phase de réduction dans MapReduce ?
En définissant job.setNumreduceTasks(0) dans la configuration dans un driver on peut éviter de réduire la phase. Cela fera un nombre de réducteur comme 0 . Ainsi, le seul mappeur effectuera la tâche complète.
Avantages du travail Map only dans Hadoop
Dans l'exécution du travail MapReduce entre les phases de mappage et de réduction, il y a une phase de clé, de tri et de mélange. Mélange – Tri sont chargés de trier les clés par ordre croissant. Regroupant ensuite les valeurs en fonction des mêmes clés. Cette phase est très coûteuse.
Si la phase de réduction n'est pas nécessaire, nous devrions l'éviter. Comme éviter la phase de réduction éliminerait également la phase de tri et de mélange. Par conséquent, cela évitera également la congestion du réseau.
La raison en est qu'en mélangeant, une sortie du mappeur se déplace pour réduire. Et lorsque la taille des données est énorme, les données volumineuses doivent être acheminées vers le réducteur.
La sortie du mappeur est écrite sur le disque local avant d'être envoyée à reduce. Mais dans le travail de carte uniquement, cette sortie est directement écrite dans HDFS. Cela permet de gagner du temps et de réduire les coûts.
Conclusion
Par conséquent, nous avons vu que le travail Map-only réduit la congestion du réseau en évitant les phases de mélange, de tri et de réduction. Map seul s'occupe du traitement global et produit la sortie. EN utilisant job.setNumreduceTasks(0) ceci est réalisé.
J'espère que vous avez compris le travail Hadoop map only et son importance, car nous avons tout couvert sur le travail Map Only dans Hadoop. Mais si vous avez des questions, vous pouvez les partager avec nous dans la section des commentaires.



