Dans notre blog précédent, nous avons étudiéHadoop Introduction et Fonctionnalités de Hadoop , Maintenant, dans ce blog, nous allons couvrir en détail la fonctionnalité HDFS NameNode High Availability.
Tout d'abord, nous discuterons de l'architecture haute disponibilité HDFS NemNode, puis de la mise en œuvre de l'architecture haute disponibilité Hadoop à l'aide des nœuds Quorum Journal et du stockage partagé.
Haute disponibilité du nœud de nom HDFS
Dans HDFS , les données sont hautement disponibles et accessibles malgré une panne matérielle. HDFS est le système de stockage le plus fiable conçu pour stocker des fichiers très volumineux.
HDFS suit la topologie maître/esclave. Dans quel maître est NameNode et les esclaves est DataNode . NameNode stocke les métadonnées. Les métadonnées incluent le nombre de blocs, leur emplacement, les répliques et d'autres détails. Pour une récupération plus rapide des données, les métadonnées sont disponibles dans le maître. NameNode maintient et attribue des tâches au nœud esclave.
NameNode était le point de défaillance unique (SPOF) avant Hadoop 2.0. Le cluster HDFS avait un seul NameNode. Si le NameNode échoue, tout le cluster tombe en panne.
Le point de défaillance unique limite la haute disponibilité des manières suivantes :
- Si un événement imprévu se déclenche, comme un plantage de nœud, le cluster sera indisponible à moins qu'un opérateur ne redémarre le nouveau nœud de nom.
- Les activités de maintenance planifiées telles que les mises à niveau matérielles sur le NameNode entraîneront également des temps d'arrêt du cluster Hadoop.
Architecture HDFS NameNode haute disponibilité
L'introduction de Hadoop 2.0 surmonte ce SPOF en prenant en charge plusieurs NameNode. L'architecture HDFS NameNode High Availability offre la possibilité d'exécuter deux NameNodes redondants dans le même cluster dans une configuration active/passive avec un serveur de secours.
- Noeud de nom actif – Il gère toutes les opérations du client HDFS dans le cluster HDFS.
- Noeud de nom passif – C'est un namenode de réserve. Il a des données similaires à celles du NameNode actif.
Ainsi, chaque fois que Active NameNode échoue, le NameNode passif assumera toute la responsabilité du nœud actif. Ainsi, le cluster HDFS continue de fonctionner.
Les problèmes de maintien de la cohérence dans le cluster haute disponibilité HDFS sont les suivants :
- Les NameNode actifs et en veille doivent toujours être synchronisés, c'est-à-dire qu'ils doivent avoir les mêmes métadonnées. Cela permet de rétablir le cluster Hadoop dans le même état d'espace de noms où il s'est écrasé. Et cela nous permettra d'avoir un basculement rapide.
- Il ne doit y avoir qu'un seul NameNode actif à la fois. Sinon, deux NameNode conduiront à la corruption des données. Nous appelons ce scénario un " Scénario Split-Brain ”, où un cluster est divisé en un cluster plus petit. Chacun croit qu'il est le seul cluster actif. Le « clôture » évite une telle clôture est un processus qui garantit qu'un seul NameNode reste actif à un moment donné.
Mise en œuvre de l'architecture haute disponibilité Hadoop
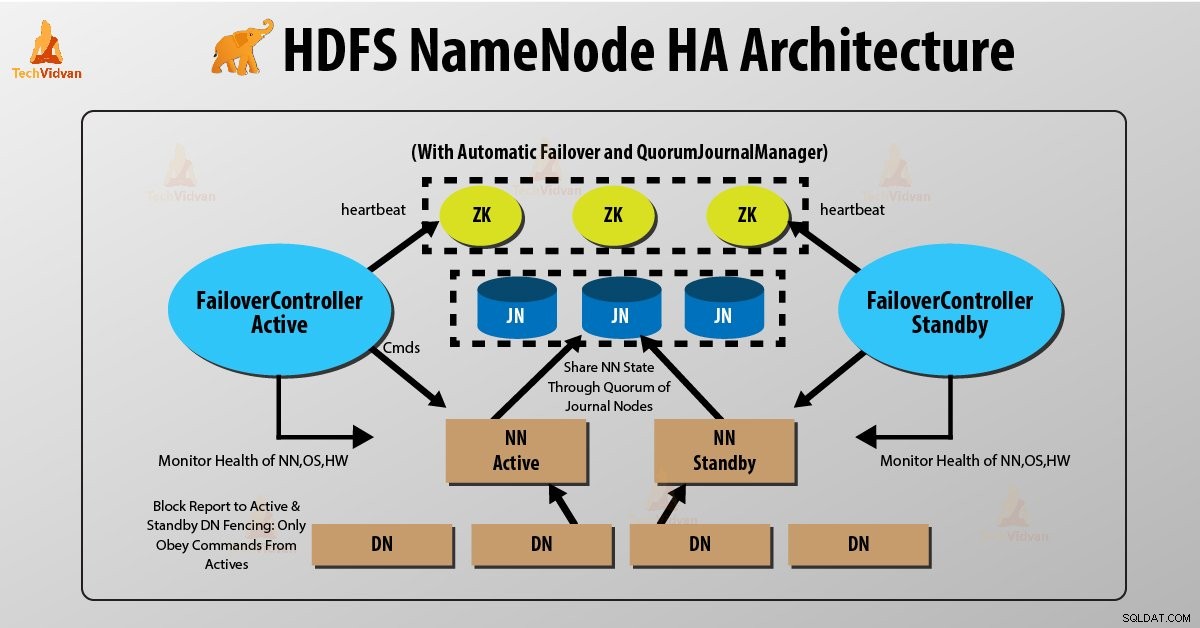
Deux NameNodes s'exécutent en même temps dans HDFS NameNode High Availability Architecture. Le client HDFS peut implémenter la configuration de NameNode actif et en veille de deux manières :
- Utiliser les nœuds de journal de quorum
- Utiliser le stockage partagé
1. Utilisation des nœuds de journal de quorum
Nœuds de journal de quorum est une implémentation HDFS. QJN fournit des journaux d'édition. Il permet de partager ces journaux d'édition entre le NameNode actif et en veille.
Le Namenode en veille communique et se synchronise avec le NameNode actif pour une haute disponibilité. Cela se fera par un groupe de démons appelés "Journal nodes". Les nœuds de journal de quorum s'exécutent comme un groupe de nœuds de journal. Au moins trois nœuds de journal doivent s'y trouver.
Pour N nœuds de journal, le système peut tolérer au plus (N-1)/2 pannes. Le système continue donc de fonctionner. Ainsi, pour trois nœuds de journal, le système peut tolérer la défaillance d'un {(3-1)/2} d'entre eux.
Chaque fois qu'un nœud actif effectue une modification, il consigne la modification dans tous les nœuds du journal.
Le nœud de secours lit les modifications à partir des nœuds de journal et s'applique à son propre espace de noms de manière constante. En cas de basculement, le standby s'assurera qu'il a lu toutes les modifications des nœuds de journal avant de passer à l'état Actif. Cela garantit que l'état de l'espace de noms est complètement synchronisé avant qu'un échec ne se produise.
Pour fournir un basculement rapide, le nœud de secours doit disposer d'informations à jour sur l'emplacement des blocs de données dans le cluster. Pour que cela se produise, l'adresse IP des deux NameNode est disponible pour tous les datanodes et ils envoient des informations sur l'emplacement du bloc et des battements de cœur aux deux NameNode.
Clôturage de NameNode
Pour le bon fonctionnement d'un cluster HA, un seul des NameNodes doit être actif à la fois. Sinon, l'état de l'espace de noms s'écarterait entre les deux NameNodes. Ainsi, la clôture est un processus pour garantir cette propriété dans un cluster.
- Les nœuds de journal effectuent cette clôture en autorisant un seul NameNode à être l'auteur à la fois.
- Le NameNode de secours prend la responsabilité d'écrire aux nœuds du journal et d'interdire à tout autre NameNode de rester actif.
- Enfin, le nouveau NameNode actif peut effectuer ses activités.
2. Utiliser le stockage partagé
Les NameNode en veille et actifs se synchronisent en utilisant un « périphérique de stockage partagé ». Pour cette implémentation, le NameNode actif et le Namenode de secours doivent avoir accès au répertoire particulier sur le périphérique de stockage partagé (c'est-à-dire le système de fichiers réseau).
Lorsque le NameNode actif effectue une modification de l'espace de noms, il enregistre un enregistrement de la modification dans un fichier journal d'édition stocké dans le répertoire partagé. Le NameNode de secours surveille ce répertoire pour les modifications, et lorsque des modifications se produisent, le NameNode de secours les applique à son propre espace de noms. En cas d'échec, le NameNode de secours s'assurera qu'il a lu toutes les modifications du stockage partagé avant de passer à l'état Actif. Cela garantit que l'état de l'espace de noms est complètement synchronisé avant le basculement.
Pour éviter le "scénario de cerveau partagé" dans lequel l'état de l'espace de noms dévie entre les deux NameNode, un administrateur doit configurer au moins une méthode de fencing pour le stockage partagé.
Conclusion
Par conséquent, Hadoop 2.0 HDFS HA fournit un seul NameNode actif et un seul NameNode de secours. Cependant, certains déploiements nécessitent un degré élevé de tolérance aux pannes . Hadoop nouvelle version 3.0, permet à l'utilisateur d'exécuter de nombreux NameNodes de secours.
Par exemple, configurer cinq journalnodes et trois NameNode. En conséquence, le cluster hadoop est capable de tolérer la défaillance de deux nœuds plutôt qu'un seul.
Veuillez partager votre expérience et vos suggestions concernant la haute disponibilité HDFS NameNode dans la section des commentaires ci-dessous.



