Jusqu'à présent, nous avons couvert l'introduction de Hadoop et Hadoop HDFS en détail. Dans ce tutoriel, nous vous fournirons une description détaillée de Hadoop Reducer.
Ici, nous discuterons de ce qu'est Reducer dans MapReduce, du fonctionnement de Reducer dans Hadoop MapReduce, des différentes phases de Hadoop Reducer, de la manière dont nous pouvons modifier le nombre de Reducer dans Hadoop MapReduce.
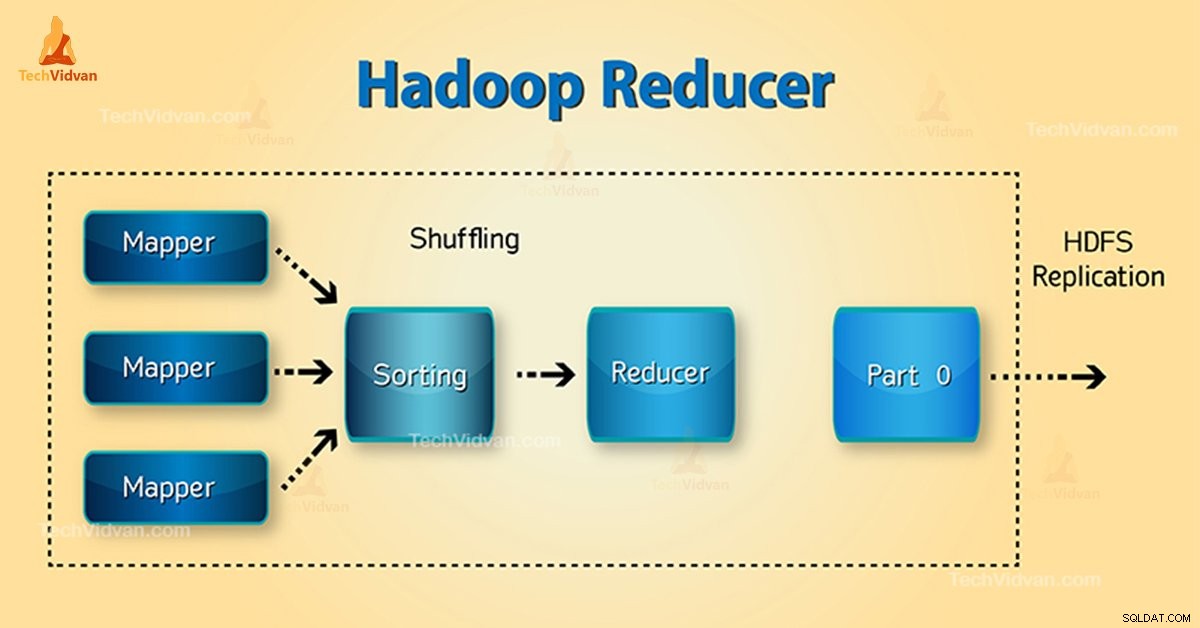
Qu'est-ce que Hadoop Reducer ?
Réducteur dans Hadoop MapReduce réduit un ensemble de valeurs intermédiaires qui partagent une clé en un ensemble de valeurs plus petit.
Dans le flux d'exécution de la tâche MapReduce, Reducer prend un ensemble d'une paire clé-valeur intermédiaire produit par le mapper comme entrée. Ensuite, Reducer agrège, filtre et combine les paires clé-valeur, ce qui nécessite un large éventail de traitements.
Le mappage un-un a lieu entre les clés et les réducteurs dans l'exécution de la tâche MapReduce. Ils fonctionnent en parallèle car ils sont indépendants les uns des autres. L'utilisateur décide du nombre de réducteurs dans MapReduce.
Phases du réducteur Hadoop
Les trois phases de Reducer sont les suivantes :
1. Phase de mélange
C'est la phase dans laquelle la sortie triée du mappeur est l'entrée du réducteur. Le framework à l'aide de HTTP récupère la partition pertinente de la sortie de tous les mappeurs dans cette phase.Phase de tri
2. Phase de tri
Il s'agit de la phase au cours de laquelle les entrées de différents mappeurs sont à nouveau triées en fonction des clés similaires dans différents mappeurs.
Mélanger et trier se produisent simultanément.
3. Réduire la Phase
Cette phase se produit après le mélange et le tri. Réduire la tâche agrège les paires clé-valeur. Avec OutputCollector.collect() , la sortie de la tâche reduce est écrite dans le FileSystem. La sortie du réducteur n'est pas triée.
Nombre de réducteurs dans Hadoop MapReduce
L'utilisateur définit le nombre de réducteurs à l'aide de Job.setNumreduceTasks(int) biens. Ainsi le bon nombre de réducteurs par la formule :
0,95 ou 1,75 multiplié par (
Ainsi, avec 0,95, tous les réducteurs se lancent immédiatement. Ensuite, commencez à transférer les sorties de carte à la fin des cartes.
Le nœud le plus rapide termine le premier tour de réducteurs avec 1,75. Ensuite, il lance la deuxième vague de réducteur qui fait un bien meilleur travail d'équilibrage de charge.
Avec l'augmentation du nombre de réducteurs :
- Les frais généraux du cadre augmentent.
- L'équilibrage de charge augmente.
- Le coût des pannes diminue.
Conclusion
Par conséquent, Reducer prend la sortie des mappeurs en entrée. Ensuite, traitez les paires clé-valeur et produit la sortie. La sortie du réducteur est la sortie finale. Si vous aimez ce blog ou si vous avez des questions concernant Hadoop Reducer, veuillez partager avec nous en laissant un commentaire.
J'espère que nous vous aiderons.



